
适合人群:科研写作者 场景:论文写作、投稿前润色、英文/中文学术表达训练 核心想法:不用“背词典”判 AI,而是用你提供的领域范例库对照你的文字 —— 看看哪些地方“偏离本领域写法”,并给出可参考的范句(带 PDF 出处)。
1)你有没有遇到这种“说不清但很致命”的问题?
很多同学的文字,语法不一定错、也“挺通顺”,但导师或审稿人会说:
这类问题,往往不是一个“敏感词”能解释的,而是更底层的写作风格差异:
- 用词频率不像本领域(该高频的术语没出现,泛化词太多)
- 搭配/语序不像本领域(短语组合很“通用”,不够专业)
- 句式结构更像模板(段落推进逻辑、连接方式、句首重复等)
- 语义表达“意思对、说法不对”(缺少本领域常见表述方式)
2)AI Word Detector 是什么?一句话解释
你提供一个“规范文档库”当人类范例(比如资产定价领域 100 篇顶刊 PDF),软件会自动学习这个领域的常见写法,然后对照你输入的文本,标出哪些词/句子/表达更像“领域外写法”,并解释原因,还会给出可参考的范句(带 PDF 出处)。

3)它的亮点是什么?(这才是和普通“AI 检测”不一样的地方)
亮点 A:你用“顶刊 PDF 文档库”来定义“什么叫规范”
不是用一个固定词典去套所有学科,而是你自己决定范例是什么:
- 机器学习:你放 100 篇 NeurIPS/ICML 相关论文
- 生物医药:你放 100 篇你领域的高质量 paper
范例库越“同领域/同子方向”,诊断越准。
亮点 B:输出不是“吓唬人的分数”,而是“可改的定位结果”
你会看到:
- 哪些词在你的范例库里很少见(词频/文档频率 DF)
- 哪些搭配在范例库里不常见(短语/语序 bigram)
亮点 C:给“范句 + PDF 出处”,你知道该参考谁怎么写
当某句话被判定为“语义偏离”时,会给出来自你的范例库的范句,并标注来源 PDF(蓝色显示)。
亮点 D:句子诊断可直接复制,丢给 AI 做“定向改稿”
软件的“句子诊断”面板支持直接选中复制。你可以把:
一起复制给 ChatGPT/DeepSeek/Claude,让 AI 按诊断点改写,而不是瞎改。
说明:AI Word Detector 的目标是提升学术表达与领域一致性。如果你在学校/期刊场景使用 AI 辅助润色,请遵守相应的披露与规范要求。
4)不用 GitHub 也能下载:3 步开箱即用(Windows)
- 打开下载页(浏览器即可):https://github.com/bluesHeart/ai-word-detector/releases/tag/v2.7.3
- 在页面里找到
AIWordDetector_2.7.3_offline.zip,点击下载 - 解压后双击运行
AIWordDetector.exe
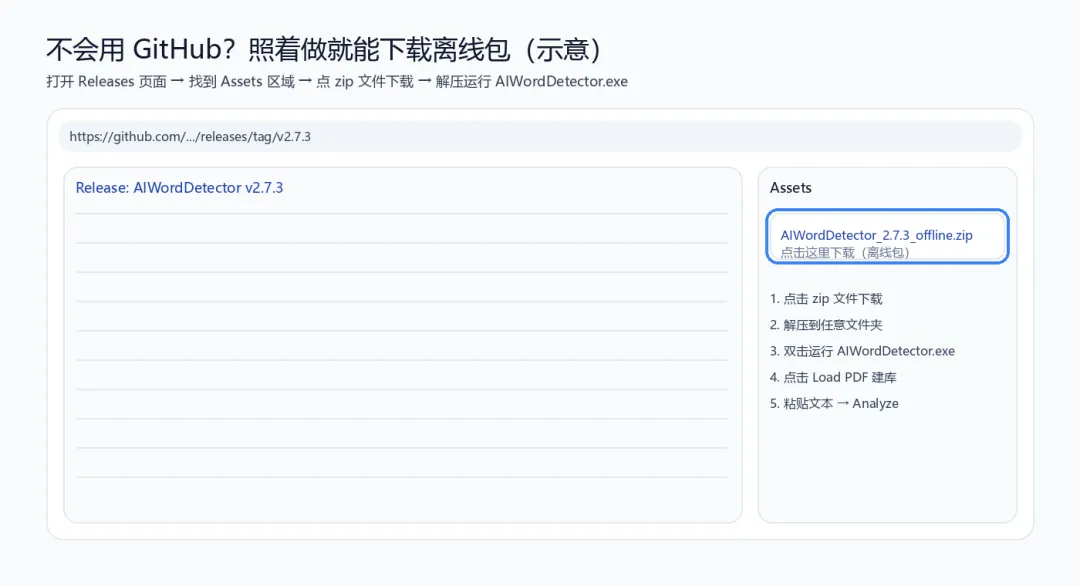
离线包已内置本地模型(不联网),整体体积 < 1GB。
5)第一次建库要怎么做?(建议:先用 50–100 篇)
你需要准备什么样的 PDF?
建议:
- 可复制文字的 PDF(扫描版/图片版可能提取不到内容)
- 从 50 篇开始,效果就会明显;100–200 篇会更稳
建库会不会很慢?
第一次建库属于“重活”(要抽取文本、统计词频/短语、建立语义索引)。不同电脑差异很大,但有几个经验:
- PDF 越多、越长,首次建库越久(这是一次性成本)
软件会显示进度与阶段;数据默认保存在 exe 同目录,方便清理。
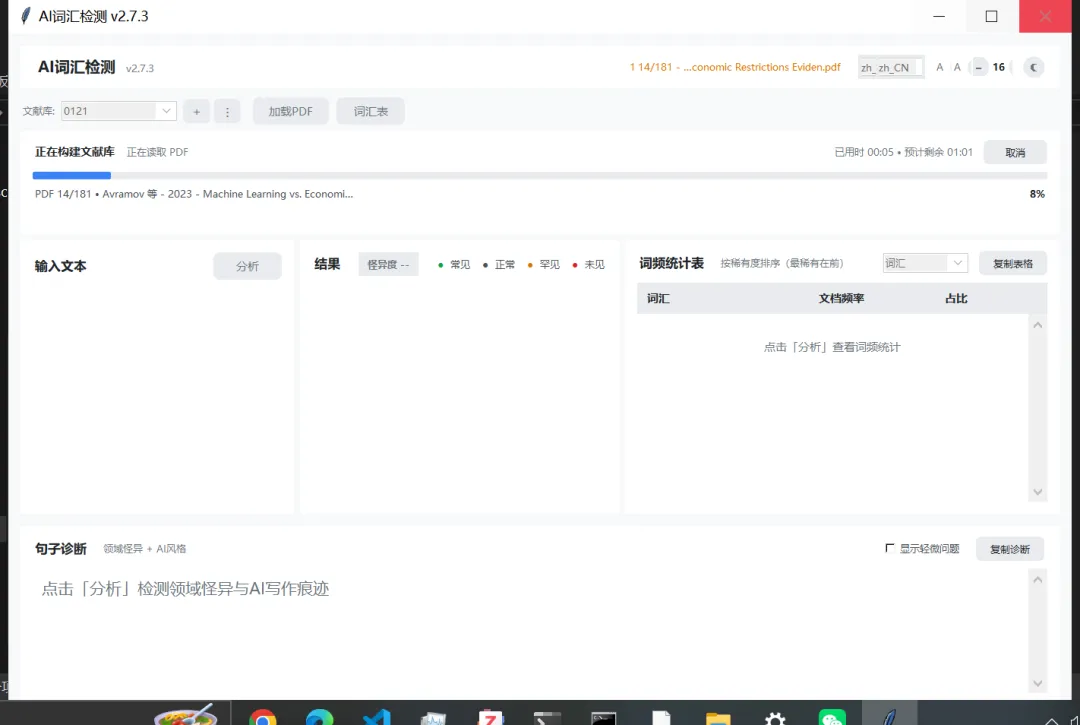
6)你会看到什么结果?怎么读?
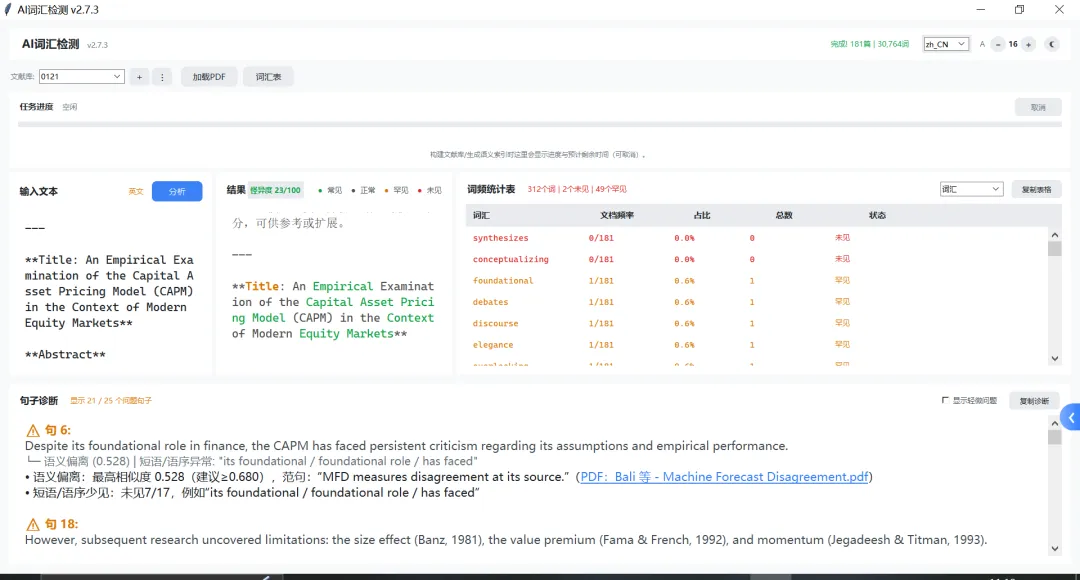 (这是用deepseek生成的一篇资产定价论文,作为例子进行测试,我上传了181篇资产定价的顶刊论文作为文档库)
(这是用deepseek生成的一篇资产定价论文,作为例子进行测试,我上传了181篇资产定价的顶刊论文作为文档库)
你主要看三块:
① 词频/短语统计(右侧)
告诉你哪些词/短语在你的范例库里很少见 —— 很多“看着像 AI”的句子,问题就出在用词过泛、搭配不专业。
② 句子诊断(底部,最重要)
按严重程度排序,优先显示“最值得先改”的句子。 并且:句子诊断支持直接选中复制(拖拽选中 → Ctrl+C)。
③ 范句(用于对照改写)
当出现“语义偏离”时,会给出相似范句,并标注 PDF 出处(蓝色)。 这能让你知道:顶刊/范例库里通常怎么说这件事。
7)把诊断复制给 AI:一键变成“按点改稿”
你可以把软件里的诊断复制出来,按下面模板丢给 AI:
模板(建议复制使用)
你是【资产定价/你的领域】的学术写作编辑。请根据“诊断点”和“范句”改写我的句子,使其更贴近顶刊写法。要求:1) 不改变原意,不新增虚构结论/数据2) 尽量采用范句的表达习惯(术语、句式、推进逻辑)3) 改写后更像人类顶刊论文风格:更具体、更克制、更可检验4) 输出三段:改写句子 / 修改要点(对应诊断点逐条)/ 可选替代表达(2-3 个)这是原始诊断(来自软件):【粘贴你复制的“句子诊断”内容到这里】
小提示:你可以一次只让 AI 改 1–3 句,质量通常更高。
8)常见问题(你可能会遇到)
Q1:为什么我换了模型/更新了软件,结果看起来没变?
如果你更换过语义模型,但还在用旧的语义索引,结果可能会“看起来像没生效”。 软件会在检测到模型与索引不匹配时提示你重建索引(按提示操作即可)。
Q2:为什么有些标题/小节也被当成异常?
软件对标题/列表/公式做了“结构识别”,尽量避免把标题当成短句误报;但如果你的文本格式非常不规则,也可能误判。建议尽量保持正常段落格式,或在建库时选更规范的 PDF。
Q3:我的 PDF 是扫描版怎么办?
扫描版通常提取不到文字,建库效果会很差。建议换可复制文字的版本(出版社版、arXiv/SSRN 源文件等)。
9)隐私与本地化
- 范例库、缓存默认保存在 exe 同目录(便于清理)
10)下载与项目地址
- 项目主页: https://github.com/bluesHeart/ai-word-detector
- 开箱即用离线包(Releases): https://github.com/bluesHeart/ai-word-detector/releases/tag/v2.7.3
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
