WordPiece 的“前世今生”
- 2026-07-14 23:36:45
引言
我们在上一篇《由浅入深了解 NLP 中的 Tokenizer》 中提到 Subword-based 中的 WordPiece 算法。
这篇来详细聊下 WordPiece 词表训练算法。
💡 为什么选择 WordPiece:
1、 WordPiece 的训练与分词过程以字符为基本单位,且显式区分词首与词内子词,使得子词合并过程、结果更适合人类阅读和理解习惯。
2、 在理解了 WordPiece 之后,再去理解缺乏显式子词边界语义的 BPE,以及以 byte 作为基本单位的 Byte-level BPE,会明显降低整体理解成本。
本文将讲述:
1、WordPiece 的“前世”
2、WordPiece 的“今生”(huggingface-tokenizers 中的 WordPiece 实现)
WordPiece 的“前世”
最早提出并明确命名 WordPiece 是来自 Google 2012年的一篇论文
《Japanese And Korean Voice Search》
这是一篇关于语音识别的论文。它最早提出了 WordPieceModel 概念,是现代 WordPiece 的鼻祖。
不要被论文的标题迷惑了,Voice Search 并不是直接使用声音搜索,而是 声音 -> 文本 -> 搜索
声音 -> 文本 现在通常称为自动语音识别 (ASR,Automatic Speech Recognition)。
有别于神经网络实现的 ASR,在十几年前,是传统混合式 ASR,它主要有几个步骤:
1、声学模型:分析声学特征,输出音素 (phoneme/语音的最小单位) 的概率
2、发音字典 (lexicon) :这些音素可能组成什么词
3、语言模型 (Language Model):根据上下文和可能组成的词,组合成合理的句子
💡 在 ASR 系统中,lexicon 可以看作“一对多”映射:一个音素序列可能对应多个文本形式,从而为解码提供候选。
例如:
chén mò -> 沉默 、沉没
注意:
为了方便理解本文都使用拼音代替音素,实际上音素是另一套独立、完整的符号体系。
Google 语音搜索系统在把语言从英语扩展到日文、韩文时碰到了一些问题。
我们这里只关注其中一个问题,就是关于发音字典 (lexicon) 的问题。
由于这个发音词典的存在,文本必须被切分。
ℹ️ 如果不切分,这个发音字典里面都是完整句子,而句子是无法穷举的。
词组成句子的数量几乎是无限的
在英语中词语之间由空格天然分隔,且词级多音现象较少,因此可以直接构建基于单词的发音词典。
例如:today is cloudy
按空格分:today / is / cloudy
而日文、韩文以及中文没有明确的词语分界线且有大量的多音字、多形字。
方法一:按字分
例如:今天天气真好
按字分词:今 / 天 / 天 / 气 / 真 / 好
看似按照字分没有问题,但是日语中存在大量的“一字多音”、“一音多字”。
ℹ️ 我们用中文举例:
读音 yì 对应的常见汉字有:义、意、易、艺、译、异、议、益、亿、翼、忆、抑…
“行” 对应的读音有:xíng、háng
但是事实上日文的情况更严重
举个简单的例子:5 个字的句子,平均每个字有 3 个发音,那就有 5³ = 125 种可能。
一般来说可以通过剪枝减少路径,但是发音字典还是需要保留所有可能性。
论文中提到一个指标,在日文中如果按字分,平均需要尝试十次以上的发音才能找到正确结果。
💡 按词切分在日文、韩文、中文时显得有些“水土不服”。
方法二:按照高频字符串分
论文中还提到一个方法就是对网页里“经常一起出现的字符串”当词。
例如抓去一批网页后统计出高频词做成发音字典:
rén gōng zhì néng -> 人工智能shēn dù xué xí -> 深度学习jī qì xué xí -> 机器学习这时用户说了“人工智能大模型应用”发音字典中还是没有,所以这种方式往往会产生大量未登录词(OOV),并且强烈依赖语言和领域。
💡 按照高频字符串分在小规模、单领域系统中是可行的,但在多领域的搜索场景下,词表维护成本和 OOV 问题会迅速失控,因此在工程上难以扩展。
方法三:WordPieceModel
论文中提出了 WordPieceModel 技术,也是 WordPiece 的雏形。
大致过程:
1、使用基本 Unicode 字符初始化词单元表(日语包括汉字、平假名、片假名,韩语包括谚文和 ASCII),总数约为日语 22000 个,韩语 11000 个。
2、使用该词表在训练数据上构建语言模型。
3、通过将当前词表中的两个单元合并,生成一个新词单元,选择能最大提升训练数据似然的新单元。
4、重复步骤 2,直到达到预定义的词表规模或似然增益低于阈值。
详解:
上面的描述非常宏观,我们通过一个例子来详细理解下。
例如有训练语料:
"今天杭州天气好""北京天气也好"1、先根据语料初始化一个单字符的词表(语料中所有字的去重集合):
"今", "天", "气", "好", "也", "杭", "州", "北", "京"2、统计词表中 token 的出现的次数:
token 次数 今 1 天 3 气 2 好 2 也 1 杭 1 州 1 北 1 京 1 3、根据词表生成相邻子词表(bigram)并统计次数:

仔细思考这个统计过程,在后面也会用到 4、计算相邻子词得分:
举个例子:
根据上面的表很明显应该先合并成杭州、北京,并添加的词表中,重复这个过程。
💡 这里需要注意的是合并后的“杭州” 加入词表后,原来的“杭”,“州”是不删除的。词表在训练过程中是只会增大的,也就是初始化的词表一定是最终词表的一个子集。
这只是第一轮,让我们以轮次的角度再看下整个过程:

ℹ️ 这样仅计算得分就可以逐渐从大量日、韩、中语料中合并出词语,得到一个大小适当、不容易OOV的词表
⚠️ 注意
论文中仅提到了大致过程及 WordPieceModel 名称,并没有任何的伪代码或者公式。
Google 虽然开源了基于 WordPiece 训练完成的词表(例如:BERT模型中词表),却从未开源其训练算法。
以上算法均是开源社区根据后来公开的资料文献推测的。
到这里,我们已经看到 WordPiece 的“前世”是如何为日语、韩语、汉语等没有空格分词的语言解决 音素->文本 发音字典 (lexicon) 的问题。
而随着 Transformer 大幅推高文本语言模型的能力,对文本分词在泛化能力、词表规模与建模稳定性上的要求也大幅提高。这种要求不仅体现在中文、日文等语言上,也体现在英语等拉丁语系语言中。
WordPiece 又有了用武之地。这就是它的“今生”。
WordPiece 的“今生”
英语中,一个词往往会因为时态、单复数、派生关系而产生大量形态变化:
tokentokenstokenizertokenizingtokenization如果将这些形式全部作为独立的词条加入词表,不仅会导致词表规模迅速膨胀,还会使得模型难以在不同词形之间共享统计信息(长尾)。
为了解决这一问题,语言模型开始转向子词级(subword-level)建模: 不再将“词”视为最小不可分割的单位,而是将其拆解为在多种上下文中反复出现的、更小的片段。
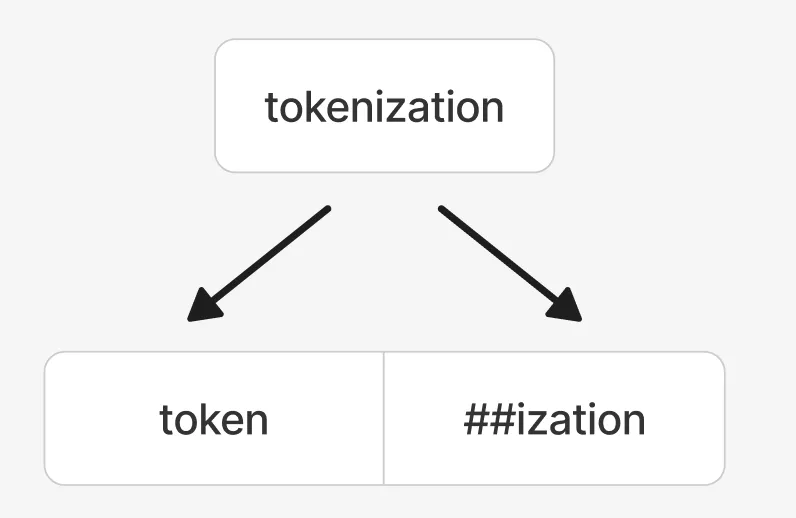
“##”代表不是首词
这样的拆分方式是不是很眼熟,其实就是一个没有空格作为词界的字符串,需要拆分。
这和中文的拆分如出一辙。
WordPiece 的“今生”实现
“今生”的 WordPiece 以 HuggingFace 的 tokenizer 项目中的实现为参考。
💡 这是因为:
1、Google 并没有公开 WordPiece 训练算法/代码,仅是一个思想,因此没有一个标准的参考。
2、HuggingFace 的算法相较于 Google 论文中的算法效率更高,更具工程价值。
HuggingFace 的 WordPiece 总体思路和论文中一致。其不同之处在于:
首先:对于词内子词增加后缀指示符(suffix indicator),例如BERT中的“##”。
其次:合并相邻词的选择方法不同(前者根据出现次数,后者根据score)。
后缀指示符的作用
后缀指示符(如 BERT 中的 ##)的核心作用,是在 token 中显式编码子词的词边界信息。可以在解码时还原词信息。
当然还有其他作用,例如减少语义歧义、减少非法分词路径提高效率等。
看一个例子:
假设有一个词表没有使用后缀指示符:
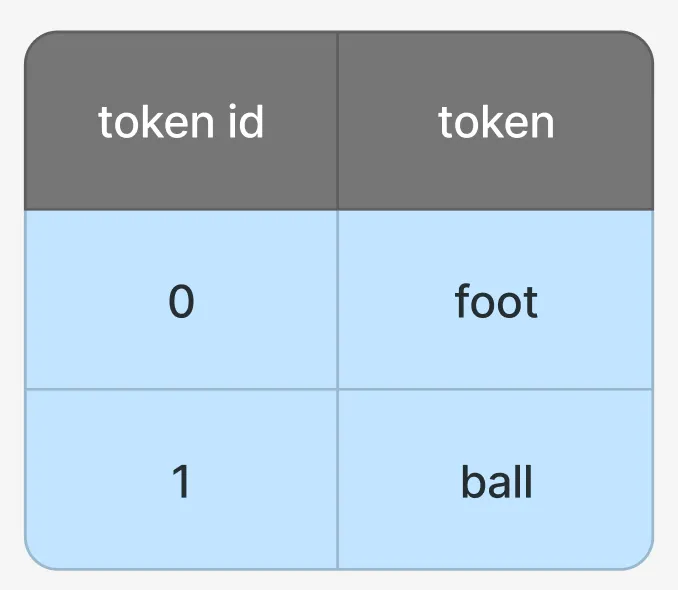
当模型输出 token id 为 [0,1],解码时就无法区分是 "football" 还是 "foot","ball"。
假设使用了后缀指示符的词表:
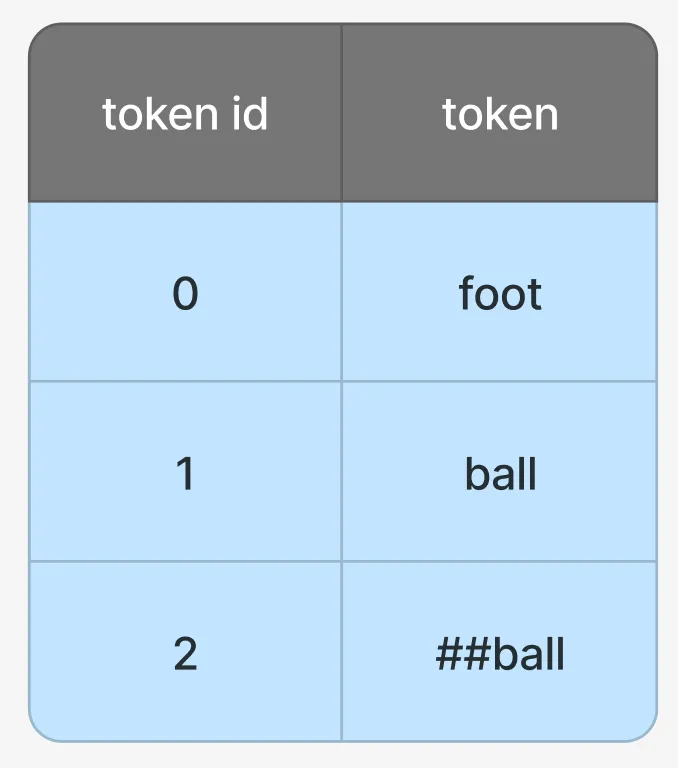
当模型输出[0,1]就是"foot","ball",如果是[0,2]则是"football"
💡
1、这里没有使用中文举例子,这是因为中文不依赖空格做分隔,解码时不需要恢复空格信息。也就是说对于中文来说后缀指示符不是必须的
2、bert-base-chinese 模型的词表对中文做了特殊处理,是直接按字拆分的也就是 character-based,对于其他语言使用的是 WordPiece,这更多是基于工程上的考虑。
3、WordPiece 本身是语言无关的,并未对中文进行特殊处理。但是为了方便理解,后文统一使用英文示例进行说明。
大致过程:
1、先初始化一个词表,并对非首字增加后缀指示符(suffix indicator)
2、然后合并出现次数最多的相邻词
3、把合并的词添加进词表
4、重复2、3,直到到达预定的词表大小
详细过程:
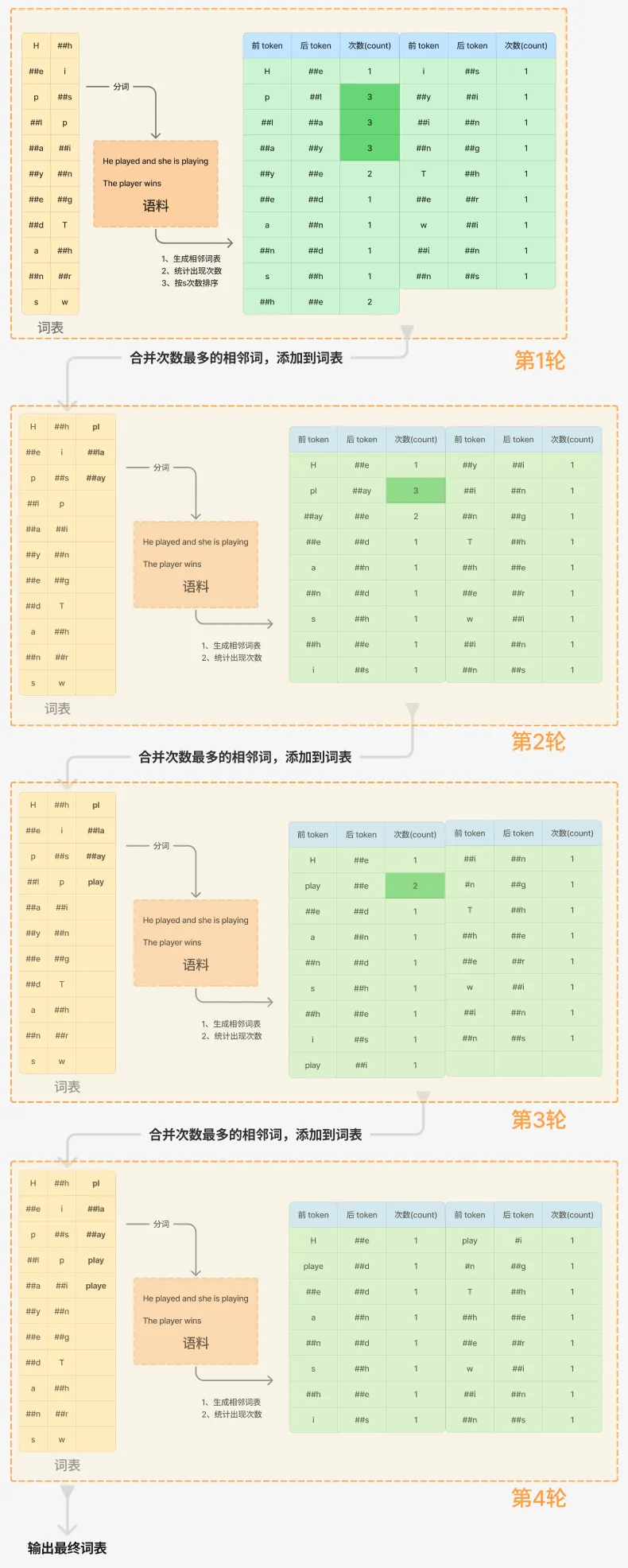
有语料:
He played and she is playingThe player wins1、初始化一个词表:
分词并添加后缀指示符:
He → H ##e played → p ##l ##a ##y ##e ##d and → a ##n ##d she → s ##h ##e is → i ##s playing → p ##l ##a ##y ##i ##n ##g The → T ##h ##e player → p ##l ##a ##y ##e ##r wins → w ##i ##n ##s 对分词去重得到初始词表:
"H", "##e", "p", "##l", "##a", "##y", "##e", "##d", "a", "##n", "s","##h", "i", "##s","p","##i","##n","##g","T", "##h", "##r", "w"2、统计相邻词出现的次数:
这一步,可以停下来仔细思考下统计过程
3、合并次数多的相邻词:
这里和论文中不一样,不需要计算score,仅合并出现次数多的相邻词:
"p" + "##l" → "pl""##l" + "##a" → "##la""##a" + "##y" → "##ay"把新合并的词加入原词表,并重新统计后再词执行合并。
看下整个过程:
希望对你有帮助
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Excel像素画生成Photo2Excel v1.0,自动识图,用格子画出你的卡通画
- 专业EXCEL 图表这么做 | 极大数与较小数之间的图形表达方式
- Excel这8个「隐藏杀招」,让我每天少加班2小时!90%的人都没用过
- Excel中超链接出现“由于本机限制,该操作已经取消,请与系统管理员联系”怎么办?
- Excel让数据提取结果自动生成编号
- 告别Excel手动记录:外贸CRM软件重构客户管理模式!
- 如何制作精准的Excel财务报表:步骤和教程
- 3个Excel隐藏技巧,效率直接拉满!
- Excel高效办公宝藏:一键复制的VBA代码库来了!
- 【Excel】用对是美观,用错是灾难~盘点合并单元格带来的灾难性事件!
