Excel透视表功能受限,用 DuckDB 的 PIVOT / UNPIVOT 一次性解决(SQL版透视表实战)
- 2026-06-20 11:26:46
在日常数据分析中,Excel 的透视表几乎是最常用的功能之一。
它可以快速完成:
分类汇总 多维统计 数据对比分析
但当数据规模变大,统计维度有条件筛选,透视结果还须进行下一步处理时,透视表就有点不够用了
比如:
每次分析都需要手动拖拽字段 多指标对比时结构容易混乱 透视结果无法直接进行二次运算 更重要的是同样的数据结构,每次处理,操作都要重复一遍
在 DuckDB 中,其实已经提供了对应的两个能力:
PIVOT(行转列) + UNPIVOT(列转行)
它不仅可以在数据库层直接完成类似 Excel 透视表的能力,并且还能继续参与后续的筛选、计算和规则分析。
这篇文章主要用最直接的方式,把这两个函数的使用方法整理出来,并结合 Excel 透视表做对照,方便快速理解和上手。
透视表函数PIVOT
示例SQL代码
--创建一个方法,把excel中数值型日期转回真实的日期CREATEORREPLACE MACRO excel_value_date_to_normal_date(k) ASDATE'1899-12-30' + TRY_CAST(k asINTEGER) ;--读取excel中的数据源,放到临时表中CREATEORREPLACE TEMP TABLE temp_源数据 ASSELECT excel_value_date_to_normal_date(日期) 真实日期, * EXCLUDE(日期)FROM read_xlsx('F:\测试中转数据\透视与逆透视数据实例.xlsx', header = true, sheet = 'Sheet4', stop_at_empty = true, all_varchar = true, ignore_errors = true);--查看数据源SELECT * FROM temp_源数据;--使用透视表,重点场景类型分类统计流量,同时在统计时进行条件聚合SELECT *FROM (PIVOT ( select"真实日期","流量GB","重点场景类型"from temp_源数据 )ON"重点场景类型"USINGROUND(SUM("流量GB"::DOUBLE),2) as 总流量,ROUND(SUM(CASEWHEN"流量GB"::DOUBLE > 100THEN"流量GB"::DOUBLEELSE0END),2) as 流量大于100G求和,COUNT(*) as 总小区数,SUM(CASEWHEN"流量GB"::DOUBLE > 100THEN1ELSE0END) as 流量大于100G的小区数 GROUPBY"真实日期");--使用透视表,重点场景类型分类统计用户数,同时在统计时进行条件聚合SELECT *FROM (PIVOT ( select"真实日期","RRC连接最大数","重点场景类型"from temp_源数据 )ON"重点场景类型"USINGSUM("RRC连接最大数"::INTEGER) as 总用户数,SUM(CASEWHEN"RRC连接最大数"::INTEGER > 150THEN"RRC连接最大数"::INTEGERELSE0END) as 用户数大于150的小区求和 ,COUNT(*) as 小区数,SUM(CASEWHEN"RRC连接最大数"::INTEGER > 150THEN1ELSE0END) as 用户数大于150的小区数 GROUPBY"真实日期");_表名_[原数据,流量统计,用户数统计]
输出结果
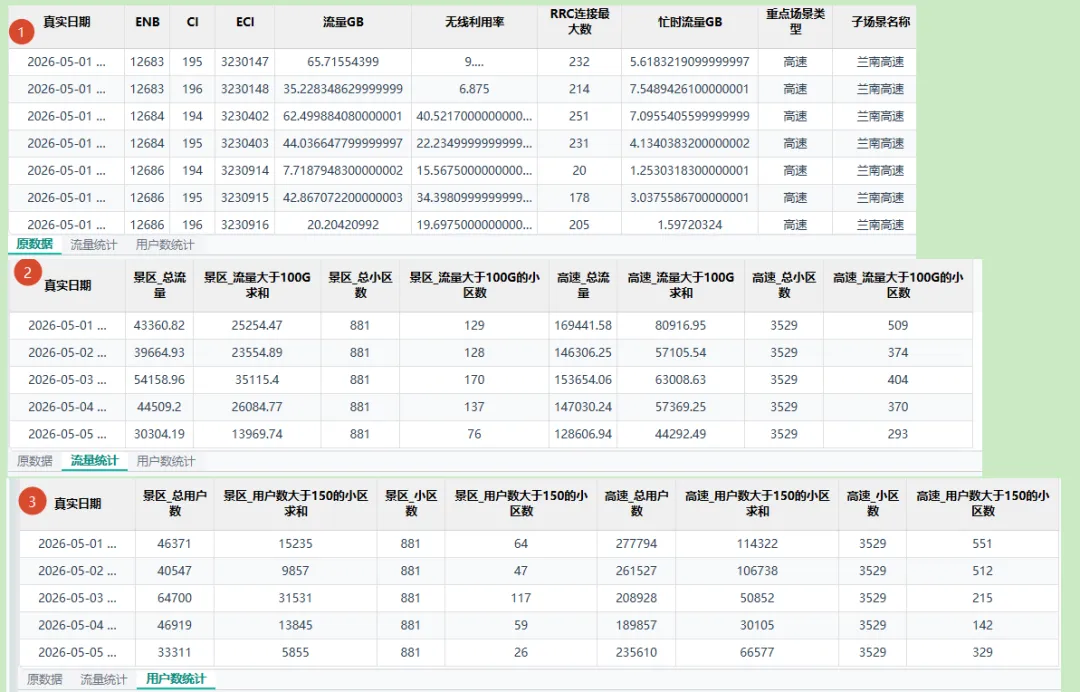
SQL脚本功能说明
从指定Excel文件中读取表中内容并保存到临时表中 按重点场景类型对流量进行统计,分整体统计和条件统计 按重点场景类型对用户数进行统计,分整体统计和条件统计
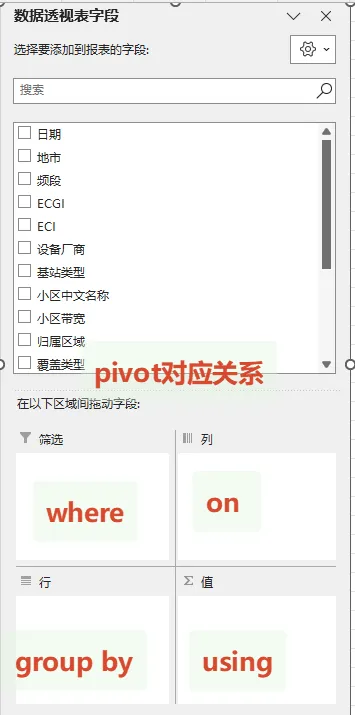
透视表函数通用模板,与EXCEL中透视表对应关系如下图所示
SELECT *FROM (PIVOT (数据源)ON xxxUSING 聚合函数GROUPBY xxx);PIVOT后面可以是一个表名,也可以是一个SELECT子查询,拿哪份数据做透视,注意不要放原始大表,因为没有没参与 ON / USING 的列,DuckDB 会自动当成 GROUP BY 列,导致结果被拆得特别碎ON指定:“哪一列的值,要横向变成列名”,比如示例中重点场景类型中的景区、高速,自动去重后,横向变成列名USING指定:“透视后如何聚合计算”,USING后跟的一定是聚合函数,不同聚合函数以逗号分隔重点扩展--条件聚合
有时希望:既统计整体数据,又统计满足某条件的数据 用于: 整体 vs 特定条件对比分析。这里的条件:仅作用于某个聚合函数,不会像 WHERE那样过滤整个数据源经测试 FILTER方法在这里做筛选时未生效,建议使用CASE WHENGROUP BY指定:“按哪些字段保留行维度”
逆透视表函数UNPIVOT
示例代码
--读取excel中的数据源,放到临时表中CREATEORREPLACE TEMP TABLE temp_源数据 ASSELECT *FROM read_xlsx('F:\测试中转数据\透视与逆透视数据实例.xlsx', header = true, sheet = 'Sheet2', stop_at_empty = true, all_varchar = true, ignore_errors = true);--查看源数据SELECT * from temp_源数据;--逆透视后转成长表SELECT *FROM temp_源数据UNPIVOT ( 参数值FOR 参数名 IN ( "参数1","参数2","参数3","参数4","参数5" ));_表名_[源数据宽表,逆透视后长表]输出结果
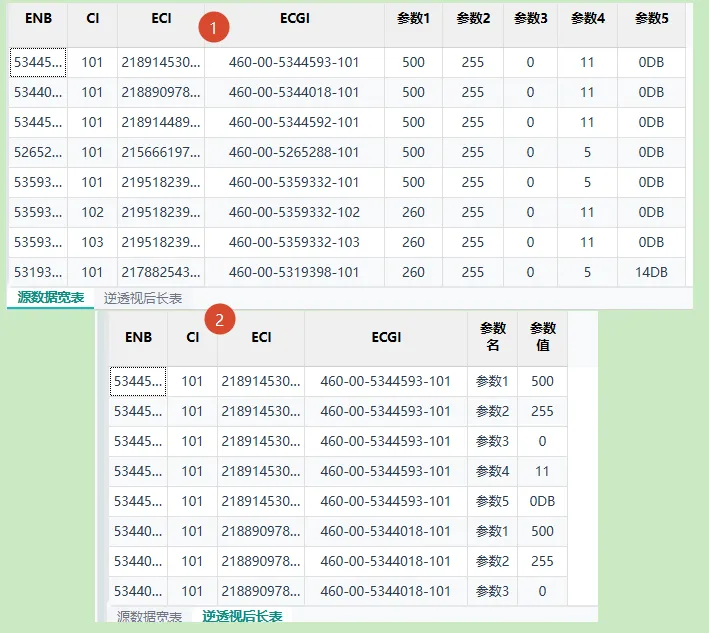
SQL脚本功能说明
从指定Excel文件中读取表中内容并保存到临时表中 使用逆透视表函数保留小区信息,参数转成长表,每行中包含参数名与参数值,这个数据结构很像MML参数修改工单模板
通用模板说明
SELECT *FROM 表UNPIVOT ( 值列FOR 名称列 IN (列1, 列2, 列3));值列存放“原来的数值”,对应源数据中的参数值名称列存放“原来的列名”IN指定“要拆的列”
总结
一句概括:PIVOT 用于“展示结构”,UNPIVOT 用于“整理结构”。
前者对比Excel中的透视表更灵活,尤其是条件聚合,无须重新整理数据源,而且透视结果可以直接进行下一步处理,比如添加环比、同比指标、解决率、占比、排名等
后者用于结构化数据,之前说的MML参数自动化,底层逻辑就是UNPIOVT整理的长表,结构统一,指定参数建议值后,后期可以实现批量参数核查, 思路分享:从“大规则”到“小规则”:一种基于小区结构的参数规则建模方法,实现MML参数自动化
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Excel 批量加前缀完整教程,自定义格式 + Ctrl+E + 连接符 + TEXT,4 招全搞定
- 把PPT炼成“力量”,让IP精准落地|湾区女科创家协会商学院第七期培训圆满举办
- 主任用AI做全院夸的PPT,只花了10分钟
- 我用AI准备了一场完美汇报:从数据到PPT只用2小时
- 华为问界M9——新品发布会全案PPT,豪华生活方式成交案例
- 李想说一年16场发布会看麻了:从2小时PPT到交车周期,普通人该怎么筛车
- PPT副业月入3000,他是怎么做的
- 看课堂PPT我们是怎么制作的,也不是那么简单
- 嘴上“不想干了”,身体:PPT干到凌晨
- 脂肪肝逆转综合干预PPT模板I27页
