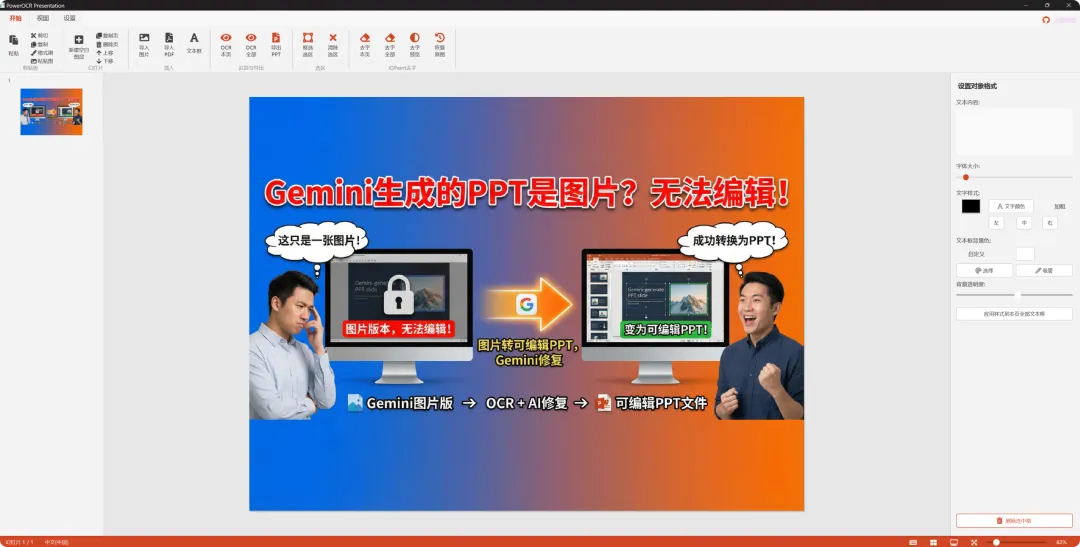
不知道你们有没有这种经历:老板甩过来一个扫描版的PDF或者一堆图片,让你做成一份可编辑的PPT。
 我的天,那种对着图片一个字一个字敲进文本框的日子,现在想起来都觉得手腕疼。要是页数少还能忍忍,一旦碰上几十页的,那简直是灾难。
我的天,那种对着图片一个字一个字敲进文本框的日子,现在想起来都觉得手腕疼。要是页数少还能忍忍,一旦碰上几十页的,那简直是灾难。
所以我一直在找,有没有那种既能识别图片里的文字,又能把这些文字直接变成PPT里可编辑文本框的工具。说实话,试过不少,但很多要么识别出来是一堆乱码,要么就是纯图片转PPT,根本没法编辑文字。
直到我发现了这个叫 OCRPDF-TO-PPT 的开源小工具,我才感觉“得救了”。它的核心思路特别巧妙,不是简单地把图片贴进PPT,而是把每张图片作为幻灯片的背景,然后用OCR识别出来的文字,会变成一个个独立的、可以随意编辑的文本框,精准地覆盖在原来文字的位置上。
有个细节我特别喜欢,就是它支持 “选区识别” 。有时候图片上可能只有一小段文字是你需要的,其他部分都是无关紧要的装饰或者表格。这时候你可以直接在图片上框选一个区域,告诉它“只识别这一块地方”,既省时间又减少错误。
更贴心的是,它还想到了一个PPT里常见的“尴尬”场景:那就是原图上有文字,你识别出来的文本框也在同样的位置,导出后两层文字叠在一起,看着会有点乱。
这个工具提供了一个解决方案,可以调用一个叫IOPaint的接口,先智能地把背景图上的原文字“擦掉”,生成一张干净的背景图,再把你识别出的文本框放上去。这样一来,导出的PPT背景是纯净的,文字又是可编辑的,完美避开了“双层文字”的烦恼。
整个操作流程也很符合直觉:导入图片或PDF,点一下OCR识别,文字框就自己生成了。你可以像在PPT里一样,随意拖拽、调整文本框大小,甚至双击修改识别错的字。全部搞定后,一键导出PPT,再用PowerPoint打开,每个字都是可以编辑的。
虽然它的安装需要一点简单的Python环境配置(毕竟是给开发者用的工具),但项目作者把步骤写得很清楚,跟着做基本没问题。而且它在GitHub上已经收获了几百颗星,说明用过的朋友都觉得不错。
对我来说,这个工具最大的价值就是“省事”。它把“识别文字”和“制作PPT”这两个原本割裂的步骤无缝衔接起来了,让我能把精力更多地放在内容本身,而不是机械地搬运文字。如果你也经常被PDF和图片转PPT折磨,不妨去试试这个工具,相信我,你会回来感谢我的。https://github.com/Tansuo2021/OCRPDF-TO-PPT