图片PPT变可编辑?我试了十几款工具后的真相
- 2026-04-06 19:16:31
市面上没有一个工具能做到100%原样复刻,但80%的还原度+20%的人工调整,已经能让你省下重做PPT的90%时间。
前天晚上11点,盯着NotebookLM刚生成的PPT发呆。AI把我的想法可视化得相当漂亮:配色、排版、配图都挑不出毛病。问题来了:这玩意儿...是张图片,想改个标题都得重新生成。我开始翻遍全网找「图片PPT转可编辑」的工具,从免费网站到付费SaaS,从在线服务到本地软件,折腾到凌晨3点。这篇文章,就是我这场「寻宝之旅」的复盘。

⭐点击『极客精益』→『...』→ 设为星标,觉得不错就点赞👍分享🔄推荐❤️
01. 为什么「原样复刻」是个伪命题?
先说结论:市面上没有任何一款工具能做到100%一键原样复刻图片PPT。
这不是技术不行,而是这个需求本身就是个「薛定谔的完美」:你既要它保留原图的每一个像素细节,又要它把所有元素变成可编辑对象。这两个目标在技术上是矛盾的。
举个例子。你有张图片PPT,上面有个渐变色的圆角矩形,里面写着「核心观点」四个字,字体是某个设计师自定义的艺术字体。要「原样复刻」,工具需要做到:
1. 识别出这是个圆角矩形(而不是四条弧线拼成的形状) 2. 提取出渐变色的RGB值和渐变方向 3. 识别出「核心观点」四个字(OCR) 4. 判断出这是什么字体(字体识别) 5. 计算出文字相对于矩形的精确位置 6. 把这些信息重组成PowerPoint的原生对象
现实是什么?大部分工具只能做到前三步。第四步的字体识别,目前只有极少数商业API能做,而且准确率堪忧。第五步的精确定位,在复杂排版下误差能达到几十个像素。第六步的重组,更是依赖大量的规则和启发式算法。
所以,当你看到某个工具宣称「一键还原」,实际上它做的是:
• 把整张图片当背景 • 用OCR识别出文字,生成文本框浮在背景上 • 把明显的图片区域裁剪出来,作为独立图片插入
这能叫「可编辑」吗?能。你确实可以改文字了。但这离「原样复刻」还差得远:改不了背景色、调不了图标位置、留不了字体样式。
但这里有个好消息:对于绝大多数场景,80%的还原度已经够用了。
想想看,你真的需要100%像素级一致吗?大部分时候,你只是想:
• 改几个字 • 调整一下数据 • 换个配图 • 微调一下布局
这些需求,80%还原度的工具完全能满足。剩下的20%,花15-20分钟人工精修,总比从零重做PPT(至少2-3小时)强太多了。
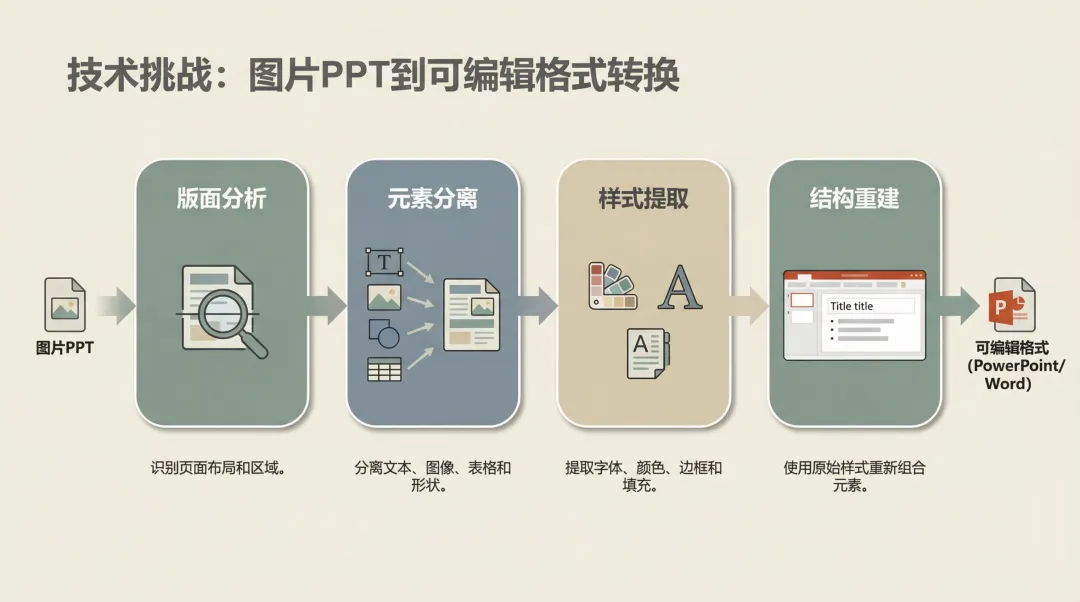
02. 转换的三大核心步骤(技术拆解)
说白了,把图片PPT变成可编辑版本,本质上是个「逆向工程」的过程。原本的PPT是从结构化数据(文本框、形状、图片)渲染成图像的,现在你要反过来,从图像中还原出结构化数据。
这个过程可以拆成三个阶段:
版面分析(Layout Analysis)
第一步是让机器「看懂」这张图片的布局。哪里是标题?哪里是正文?哪里是图表?哪里是装饰性元素?
这一步通常用目标检测模型来做,比如YOLO或Detectron2。模型会在图片上画出一堆边界框(Bounding Box),每个框标注一个类别:Title、Text、Image、Table、List等。
好的版面分析模型,能识别出复杂的层级关系。比如一个标题下面有三个并列的文本块,每个文本块旁边还有个小图标。这种嵌套结构,如果识别不准,后面的步骤就全乱套了。
PaddleOCR的PP-DocLayoutV2在这方面表现不错。它基于RT-DETR目标检测,在多种文档类型下对标题、段落、表格、公式等结构元素的检测精度都很高。而且它是开源的,GitHub上有 71.5k+ stars(截至到2026年3月3日),是目前最受欢迎的OCR开源项目之一。
视觉分离(Element Extraction)
第二步是把各个元素「抠」出来。这里又分两个子任务:
文本OCR:对版面分析识别出的文本区域,用OCR引擎提取文字内容。这一步技术已经很成熟了,PaddleOCR、Tesseract等开源工具在中文场景下准确率都能达到95%以上。
难点在于 样式提取。不光要知道写的是什么字,还要知道用的什么字体、多大字号、什么颜色、加粗还是斜体。目前只有少数工具(如Gemini 2.5及以上版本的Standard模式)能做到这一点,而且也只是「接近」,不是「完全一致」。
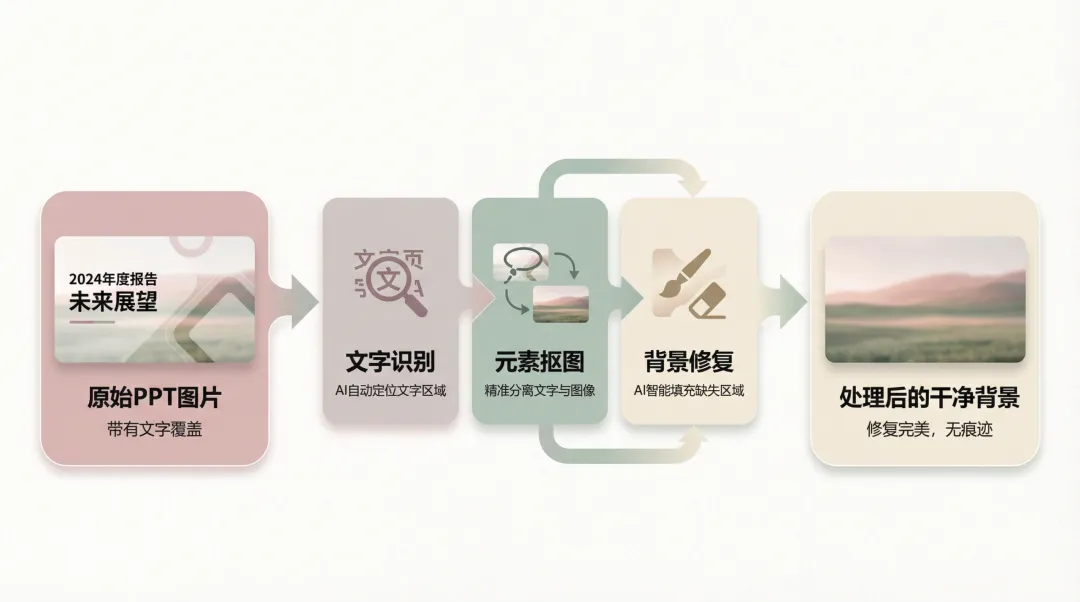
视觉元素分割:对图片、图标、图表等非文本元素,需要用图像分割技术(如SAM模型)把它们从背景中「抠」出来。
Meta推出的 SAM 3(Segment Anything Model 3)在这方面是个突破。它能识别 400万种概念,可以自动区分哪些是装饰性元素、哪些是核心图表。这意味着,系统可以更智能地判断哪些元素需要单独提取,哪些可以留在背景里。
这里有个技术难点:背景修复。当你把文字从图片上移除后,原来文字覆盖的地方会留下空白。要让背景看起来「干净」,需要用AI Inpainting技术填补这些空洞:分析周围的纹理和颜色,生成合理的填充像素。
结构回填(Structure Reconstruction)
第三步是把提取出的元素重新组装成PPTX文件。这一步看似简单,实则最考验工程能力。
你需要:
• 根据坐标信息,在PPT的幻灯片上精确定位每个元素 • 把文本内容填入文本框,并尽可能还原字体、字号、颜色 • 把图片、图标插入到对应位置 • 处理表格结构(如果有的话) • 设置背景图片
这一步通常用python-pptx这样的库来实现。但问题是,PPT的坐标系统和图片的像素坐标系统不是一回事,需要做坐标转换。而且PPT里的「形状」概念(Shape)和图片里的「视觉对象」也不完全对应,需要大量的映射规则。
03. 我实测了十几款工具的真实表现
理论讲完了,来点实战。我拿着同一份NotebookLM生成的图片PPT(10页,包含标题页、目录页、内容页、图表页),分别用不同工具转换,看看效果如何。
WPS AI:中文场景的性价比之选
还原度评分:7.5/10处理速度:约5秒/10页价格:¥25/月(会员)
WPS AI是我试的第一个工具,因为它在国内用户群体里口碑不错。上传图片后,大概5秒钟就给出了结果。
优点很明显:
• 文字识别准确率高,中文几乎没有错别字(实测准确率约96%) • 基本的段落结构保留得不错,标题、正文、列表都能区分 • 操作简单,网页端直接用,不用装软件 • 价格友好,¥25/月无限次转换
但问题也很突出:
• 图标和连接线识别很弱。我的PPT里有个流程图,三个圆角矩形用箭头连接,转换后箭头全没了,三个矩形的位置也偏了 • 图文混排处理不佳。有一页是左边文字、右边配图的布局,转换后文字跑到了配图下面 • 背景处理粗糙。它把去除文字后的图片直接当背景,但文字原来的位置有明显的「鬼影」
说白了,WPS AI适合处理 简单排版的商务PPT,纯文字+少量配图那种。如果你的PPT设计感很强、元素很多,它就力不从心了。
deckedit.com:版面还原度更好的选择
还原度评分:8/10处理速度:约8秒/10页价格:免费(浏览器本地处理)
这是个专门针对NotebookLM等AI生成PPT的工具。我试用后发现,它在版面还原上确实比WPS AI强。
最大的优点是 保留了原始布局的完整性。它不会像WPS那样把元素位置搞乱,而是尽可能按原图的坐标放置文本框和图片。
而且它强调 100%本地浏览器处理,数据不上传云端,对隐私敏感的用户很友好。
但它也有个明显的妥协:把去除文字后的整张图片作为背景。这意味着,你能编辑的只有文字,图标、形状、装饰元素全都「冻结」在背景里了。
这种方案的好处是稳妥,至少视觉效果不会崩。坏处是灵活性差,你想调整某个图标的位置?对不起,那是背景的一部分,动不了。
CopySlides:追求像素级还原的商业方案
还原度评分:8.5/10处理速度:约10-15秒/10页价格:Freemium(免费起步,更多转换需付费)
CopySlides是我测试的工具里,还原度最高的一个。它的核心卖点是「pixel-perfect 1:1 conversion」(像素级1:1转换)。
它的技术亮点在于:
• Layered Extraction(分层提取):能将背景、图片与文字拆成不同图层,每层都可以单独编辑 • Font & Color Matching(字体与配色匹配):会尝试识别并还原原始字体和配色 • Layout Analysis(布局分析):保留网格、对齐、间距等细节
实测效果确实不错。我的10页PPT,转换后有8页基本达到了「肉眼看不出区别」的水平。剩下2页是复杂的图表页,需要少量人工调整。
但它也有局限:
• 算法闭源,无法自托管或在私有环境部署 • 在高度定制化企业模板上(自定义字体、品牌色、复杂SmartArt),颜色/字体匹配更多是「接近」而非完全一致 • 批量处理需要付费,免费版有转换次数限制
PPT GPTSci / Edit in PPT:AI驱动的内容重构
还原度评分:6.5/10处理速度:约20-30秒/10页价格:每月5次免费,更多需付费
这个工具的思路和前面几个不太一样。它不追求「像素级复刻」,而是用GPT-5等多模态大模型「理解」图片内容,然后 重新生成一份结构化的PPT。
具体来说,它会:
1. 先生成一页包含原图的幻灯片 2. 再生成若干页将文本、图表拆分重排的幻灯片 3. 所有内容完全可编辑,包括图表(会转成PowerPoint原生图表对象)
这种方案的优点是:
• 图表处理能力强,能将图片中的柱状图、折线图转为可编辑的原生图表 • 支持自然语言继续编辑,比如「把第三页的标题改成...」
缺点是:
• 不是「原样复刻」,而是「内容重构」,视觉风格会有较大变化 • 处理速度慢,因为要调用大模型进行深度理解 • 对复杂混合图的处理不佳(图文叠加、截图内含小图表)
其他工具的简评
| iLoveOCR | ||||
| Online2PDF | ||||
| Gemini + Canvas | ||||
| lovart |
实测数据汇总
| 文字准确率 | ||||
| 版面还原度 | ||||
| 元素分离能力 | ||||
| 处理速度(10页) | ||||
| 价格 |
04. 开源方案:技术流的自建路径
如果你有一定的编程能力,或者需要批量处理大量PPT,那么自建工作流是更好的选择。虽然前期投入大,但长期来看性价比更高,而且可控性强。
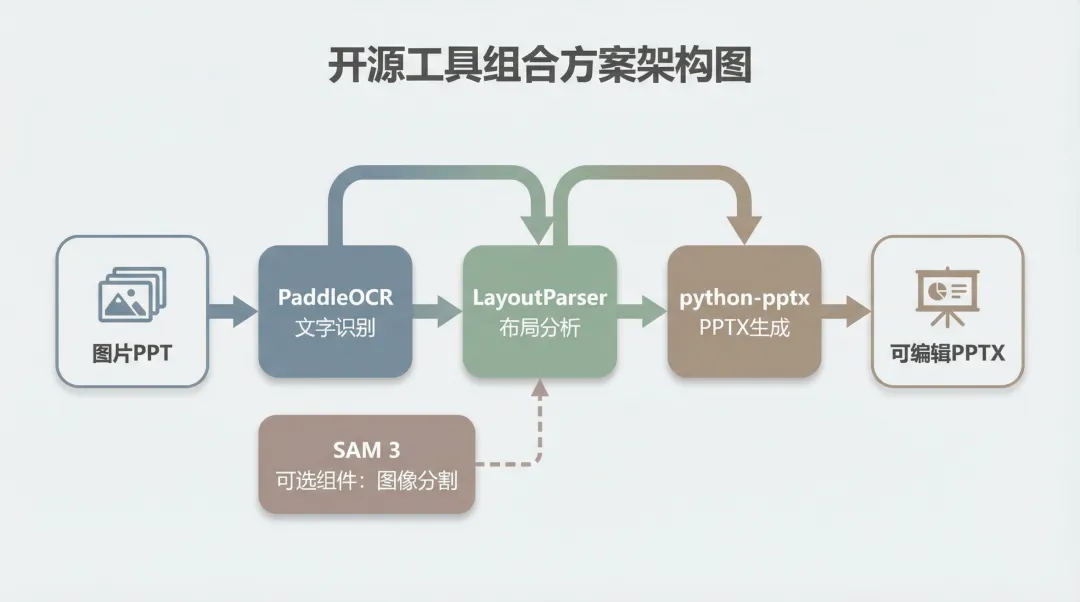
方案一:PaddleOCR + LayoutParser + python-pptx
这是我认为 最实用的开源组合。
PaddleOCR 负责文字识别,它在中文场景下的表现是开源工具里最好的,而且提供了PP-Structure模块,可以做版面分析和表格识别。它在GitHub上有 71.5k+ stars,是最受欢迎的OCR开源项目之一。
LayoutParser 负责更细粒度的布局检测。它基于Detectron2等深度学习模型,可以识别出标题、段落、图片、表格等元素的边界框和类型。
python-pptx 负责生成PPTX文件。它是个成熟的Python库,可以创建幻灯片、添加文本框、插入图片、设置样式等。
整个流程大致是这样的:
# 伪代码示例from paddleocr import PPStructurefrom layoutparser import Detectron2LayoutModelfrom pptx import Presentation# 1. 版面分析layout_model = Detectron2LayoutModel('lp://PubLayNet/faster_rcnn_R_50_FPN_3x/config')layout = layout_model.detect(image)# 2. OCR识别ocr_engine = PPStructure(table=True, ocr=True, layout=True)ocr_result = ocr_engine(image)# 3. 生成PPTprs = Presentation()slide = prs.slides.add_slide(prs.slide_layouts[6]) # 空白布局for region in layout: if region.type == 'Text': # 添加文本框 left = Inches(region.bbox[0] / 100) top = Inches(region.bbox[1] / 100) textbox = slide.shapes.add_textbox(left, top, ...) textbox.text = get_text_from_ocr(region, ocr_result) elif region.type == 'Figure': # 插入图片 image_path = extract_image(region, image) slide.shapes.add_picture(image_path, left, top, ...)prs.save('output.pptx')这个方案的优点是 高度可定制。你可以根据自己的需求调整每一步的逻辑,比如:
• 针对特定类型的PPT(学术论文、商务汇报、教学课件)训练专门的布局检测模型 • 自定义样式映射规则,让生成的PPT更符合你的品牌规范 • 批量处理时,可以并行化提速
缺点是 学习曲线陡峭。你需要懂Python、懂深度学习的基本概念、懂PPT的对象模型。对于非技术背景的用户,这个门槛太高了。(当前现在有AI Coding的加持,这个门槛已经被很大滴降低了。)
方案二:MinerU + SAM 3 + python-pptx
如果你的PPT里有大量的表格、公式、复杂图表,那么 MinerU 是更好的选择。
MinerU是专门用来解析复杂PDF的工具,它的强项是 结构化提取:能准确识别出标题层级、段落关系、表格结构、公式内容等。
它的技术亮点包括:
• 多后端支持:提供pipeline、vlm、hybrid三种后端,可以根据文档复杂度选择 • 高精度公式识别:集成UniMERNet,公式识别准确度(CDM评分)达到 0.968,接近商业级Mathpix(0.951) • 表格结构保留:学术论文表格mAP达77.6%,远超其他开源工具
配合 SAM 3(Segment Anything Model 3),可以实现更精准的图像分割。SAM 3能识别 400万种概念,可以自动区分哪些是装饰性元素、哪些是核心图表。
流程是这样的:
1. 把图片PPT转成PDF(或者逐页处理) 2. 用MinerU解析PDF,得到结构化的Markdown或JSON 3. 用SAM 3对图片区域做智能分割,提取独立的图标、图表 4. 用python-pptx根据结构化数据重建PPT
这个方案的优点是 对复杂文档的处理能力强,特别适合学术论文、技术报告这种内容密集型的PPT。
缺点是 资源消耗大。MinerU和SAM 3都需要GPU加速,如果你只有CPU,处理速度会很慢。而且MinerU的输出是Markdown/JSON,需要你自己写脚本转换成PPT,工作量不小。
方案三:DeepSeek-OCR + Unstructured(新兴选择)
这是我最近关注到的一个组合,虽然还没来得及深度测试,但从技术文档看很有潜力。
DeepSeek-OCR 是国内新兴的OCR引擎,在某些场景下可以作为PaddleOCR的替代选项。它的特点是:
• 对复杂排版的鲁棒性较强 • 支持多语言混合识别 • 提供云端API和本地部署两种方式
配合 Unstructured 框架,可以实现更灵活的文档解析。Unstructured提供统一的Element抽象(Title、NarrativeText、Table、Figure等),返回带有文本、类型、坐标的JSON列表。
这个组合的优势在于:
• 模块化程度高,可以灵活替换各个组件 • 适合需要同时处理多种文档格式的场景(PDF、Word、PPT等) • 社区活跃,文档完善
但它也有局限:
• DeepSeek-OCR的商业化程度不如PaddleOCR,生态还在建设中 • Unstructured默认配置更偏向论文、报表类文档,对PPT这种「偏设计化的视觉排版」需要额外调优
硬件配置与成本对比
| PaddleOCR + LayoutParser | ||||
| MinerU + SAM 3 | ||||
| DeepSeek-OCR + Unstructured |
云服务器成本参考:
• AutoDL GPU服务器(RTX 3090):约¥2-3/小时 • 阿里云GPU实例(T4):约¥5-8/小时 • 腾讯云GPU实例(V100):约¥10-15/小时
对于偶尔使用的个人用户,按需租用云服务器是最经济的选择。如果是企业级批量处理,建议自建GPU服务器,长期成本更低。
05. 不同人群的最优选择
说了这么多,到底该选哪个方案?这取决于你的需求和技术水平。
普通用户:WPS AI + 人工精修
如果你只是偶尔需要转换几页PPT,不想折腾技术,那么 WPS AI 是最省心的选择。
具体操作:
1. 上传图片到WPS AI,等待转换完成 2. 下载生成的PPTX,在PowerPoint里打开 3. 花15-20分钟做人工精修: • 调整错位的文本框 • 补充遗漏的图标(从原图里截取,手动插入) • 修正识别错误的文字 • 调整字体和配色
时间成本:
• 10页简单PPT:转换5分钟 + 精修15分钟 = 20分钟 • 30页复杂PPT:转换15分钟 + 精修60分钟 = 75分钟
费用预算:
• WPS会员:¥25/月(推荐按月订阅) • 或单次购买:¥5-10/次(部分功能)
这个方案的 性价比最高。虽然还原度只有75%左右,但剩下的25%人工调整,也就半小时的事。比起从零重做PPT(至少要2-3小时),这已经省了90%的时间。
设计师/创意工作者:CopySlides + 本地精修
如果你对视觉还原度要求较高,愿意为更好的效果付费,那么 CopySlides 是更好的选择。
具体操作:
1. 上传图片到CopySlides,等待AI分析 2. 下载生成的PPTX或直接在Google Slides打开 3. 检查分层效果,调整需要单独编辑的元素 4. 在PowerPoint中做最后的样式微调
优势:
• 分层提取功能让你可以单独编辑背景、文字、图片 • 字体和配色匹配度更高 • 适合需要保持品牌一致性的场景
费用预算:
• 免费版:有转换次数限制 • 付费版:具体价格需咨询官网(通常按月或按次计费)
技术用户:自建PaddleOCR工作流
如果你有Python基础,或者需要批量处理大量PPT,那么 自建工作流 是更好的选择。
推荐的技术栈:
• PaddleOCR PP-Structure:版面分析 + OCR • LayoutParser:细粒度布局检测 • python-pptx:PPT生成 • (可选)SAM 3:图像分割
前期投入:
• 环境搭建:2-4小时 • 脚本开发与调试:8-16小时 • 模型调优:视具体需求而定
长期收益:
• 单次转换(10页):5-8分钟(自动化后) • 批量转换(100页):30-50分钟 • 可定制化程度高,适配各种特殊需求
硬件成本:
• 最低配置:GTX 1660 (6GB) + 16GB RAM,约¥2000-3000(二手显卡) • 推荐配置:RTX 4060 Ti (16GB) + 32GB RAM,约¥5000-6000 • 云服务器:AutoDL GPU服务器,约¥2-3/小时(按需使用)
这个方案适合:
• 企业技术团队(需要批量数字化历史PPT档案) • 教育机构(批量处理课件) • 自动化办公产品开发者
混合方案:在线工具打底 + 开源工具精修
还有一种折中的方案:用在线工具快速处理80%的常规页面,用开源工具针对性处理20%的复杂页面。
具体流程:
1. 先用WPS AI或deckedit转换整份PPT 2. 识别出转换失败或效果不佳的页面 3. 对这些页面,用PaddleOCR重新识别文字,用SAM重新切割配图 4. 手动调整和拼装
优势:
• 效率和质量的平衡 • 大部分页面自动化处理,复杂页面深度优化 • 最后人工审核10-15分钟
成本:
• WPS会员:¥25/月 • 偶尔使用GPU云服务器:约¥2-3/小时 • 总成本可控,适合中小团队
06. 真正的难点在哪里?
聊了这么多工具和方案,咱们回到最本质的问题:为什么「原样复刻」这么难?
难点不在文字识别,OCR技术已经很成熟了。真正的难点在于:
难点一:元素分离
一张设计精美的PPT,往往是多层元素叠加的结果:
• 最底层是背景(可能是纯色、渐变、图片、纹理) • 中间层是装饰性元素(图标、线条、形状) • 顶层是内容元素(文字、图表、配图)
要「原样复刻」,你需要把这些层次完全拆开,然后在PPT里重新叠加。
但现实是,这些元素在图片里已经「融合」了。你很难判断某个像素到底属于背景还是属于前景,属于装饰还是属于内容。
目前的图像分割技术(如SAM),虽然能做到「抠图」,但对于半透明元素、阴影效果、模糊边缘等复杂情况,还是会出错。
难点二:样式还原
即便你成功提取出了所有元素,还有个更棘手的问题:样式信息。
一个文本框,不光有文字内容,还有:
• 字体(可能是系统字体,也可能是自定义字体) • 字号、行距、字间距 • 颜色(可能是纯色,也可能是渐变) • 加粗、斜体、下划线等效果 • 对齐方式(左对齐、居中、右对齐、两端对齐)
一个形状,不光有轮廓,还有:
• 填充色(纯色、渐变、纹理、图片) • 边框样式(粗细、颜色、虚实) • 阴影、反射、发光等特效 • 3D效果、旋转角度
这些样式信息,在图片里是「隐式」的:你能看到效果,但提取不出参数。
目前只有极少数工具(如Gemini 2.5以以上版本的Standard模式)尝试用多模态大模型来「理解」这些样式,但准确率还远远不够。
难点三:背景修复
当你把文字从图片上移除后,原来文字覆盖的地方会留下空白。要让背景看起来「干净」,需要用AI Inpainting技术填补这些空洞。
对于纯色或简单渐变背景,AI修复几乎能达到肉眼不可见的效果。但对于复杂的摄影底图、纹理背景,修复效果就参差不齐了,可能会出现纹理错位、色彩不连续等问题。
而且,Inpainting本身就是个计算密集型任务,需要GPU加速。如果你要批量处理几百页PPT,光是背景修复这一步,就可能要跑好几个小时。

07. 未来会怎样?
说了这么多局限性,是不是意味着「图片PPT转可编辑」这个需求永远无法完美解决?
不是的。我认为,在可预见的一两年内,这个问题会有质的突破。
关键在于 多模态大模型的进化。
现在的工具,本质上还是「管道式」的:先做版面分析,再做OCR,再做元素分割,最后拼装。每一步都是独立的模型,彼此之间缺乏协同。
但新一代的多模态大模型(如GPT-4V、Gemini 3、Claude 4.6等),已经展现出了「端到端理解」的能力。它们不是简单地识别文字和图像,而是能理解文档的 语义结构 和 视觉层次。
举个例子。你给GPT-4V看一张PPT截图,它不光能告诉你上面写了什么字,还能告诉你:
• 这是个标题页还是内容页 • 标题和正文的层级关系 • 哪些元素是重点(用了大字号、亮色) • 哪些元素是装饰(用了小图标、淡色)
有了这种「理解」,模型就能更智能地重建PPT。不是机械地复制像素,而是根据语义和视觉规律,生成符合PPT设计规范的结构化文档。
技术演进的三个阶段
第一阶段(2024-2025):管道式工具成熟
• 以PaddleOCR、MinerU为代表的开源工具持续优化 • 商业SaaS(如CopySlides、WPS AI)在特定场景下达到85%+还原度 • 但仍需人工精修,无法做到完全自动化
第二阶段(2026-2027):多模态大模型介入
• GPT-5、Gemini 3等新一代模型具备更强的视觉理解能力 • 出现真正「端到端一键高保真PPT复刻」的商用工具 • 在 语义保真 和 视觉保真 上达到95%以上的水平 • 普通人看不出区别,但像素级对比仍有差异
第三阶段(2028+):生成式重建成为主流
• 不再追求「像素级复刻」,而是「语义级重建」 • AI理解图片PPT的内容和意图,生成更符合设计规范的新版本 • 用户可以通过自然语言指令调整风格、布局、配色 • 「图片PPT转可编辑」的需求被「AI辅助PPT设计」取代
我预测,到2027年左右,会出现真正「端到端一键高保真PPT复刻」的商用工具。它可能不是100%像素级一致,但在 语义保真 和 视觉保真 上,会达到95%以上的水平,也就是说,普通人看不出区别。
到那时,咱们今天讨论的这些技术细节,都会变成「黑盒」。你只需要上传图片,等几秒钟,就能得到一份完全可编辑、高度还原的PPTX文件。
但在那一天到来之前,咱们还是得老老实实地用现有工具,配合人工调整,一点一点地把图片PPT变成可编辑版本。
08. 实用建议与避坑指南
最后,给几条实用建议,帮你少走弯路。
提高转换成功率的技巧
1. 图片预处理很重要
• 确保分辨率≥1920×1080(过低影响OCR效果) • 调整对比度和清晰度,让文字更清晰 • 裁剪掉页眉页脚等无关内容 • 如果是手机拍照,尽量保持垂直拍摄,避免透视变形
2. 分页处理复杂PPT
• 不要一次性上传几十页复杂PPT • 先转换简单页面,识别出工具的「能力边界」 • 对复杂页面单独处理,或者直接人工重做
3. 善用对比工具
• 同一份PPT,可以用2-3个工具分别转换 • 对比结果,取各家之长 • 比如:WPS AI识别文字,deckedit保留布局,CopySlides提取图层
4. 建立自己的「修复模板」
• 总结常见的识别错误(如某些字体总是识别错) • 建立快速修复的流程(如批量替换字体、统一调整间距) • 对于经常处理的PPT类型,可以预设样式模板
常见问题与解决方案
Q1:为什么转换后的文字有错别字?
• 原因:OCR识别精度受图片清晰度、字体复杂度影响 • 解决: • 提高原图分辨率 • 使用WPS或百度OCR(中文准确率更高) • 转换后使用Word拼写检查功能批量修正
Q2:为什么布局错位严重?
• 原因:复杂多列排版、文字环绕图片等场景识别困难 • 解决: • 将复杂页面拆分为多个简单区域分别处理 • 使用CopySlides的版面分析功能 • 手动调整文本框位置(使用对齐工具)
Q3:配图质量变差怎么办?
• 原因:原图分辨率低,或工具压缩了图片 • 解决: • 从原始PPT中单独导出高清图片 • 使用AI超分辨率工具(如Topaz Gigapixel、Waifu2x) • 重新替换PPT中的低分辨率图片
Q4:开源工具部署失败?
• 常见错误: • CUDA版本不匹配:检查显卡驱动和PyTorch版本对应关系 • 依赖冲突:使用虚拟环境隔离(conda/venv) • 模型下载失败:使用国内镜像源(如清华源) • 解决: • 查看GitHub Issues区的解决方案 • 使用Docker镜像一键部署 • 寻求社区帮助(如飞桨论坛、PaddleOCR微信群等)
Q5:批量转换100+页PPT,如何提高效率?
• 建议: • 使用GPU云服务器(如AutoDL、恒源智算) • 编写批处理脚本,夜间自动运行 • 设置断点续传机制,避免中途失败重新开始
避坑清单
❌ 不要做的事:
1. 不要期待100%完美还原:这是技术上不可能的,会让你失望 2. 不要在免费工具上传敏感文档:隐私风险不可控 3. 不要忽略人工审核:即便是最好的工具,也可能出错 4. 不要在低配电脑上跑大模型:会卡死,浪费时间 5. 不要一次性处理太多页面:分批处理更稳妥
✅ 应该做的事:
1. 先用免费工具试水:了解工具的能力边界 2. 保留原始图片:万一转换失败,还能重来 3. 建立版本管理:每次修改都保存一个副本 4. 记录踩坑经验:下次遇到类似问题能快速解决 5. 加入技术社区:遇到问题有人帮忙
读者互动:如果你也在折腾图片PPT转可编辑的问题,欢迎在评论区分享你的经验和踩过的坑。或者,你有什么更好的工具推荐?咱们一起交流。

局限性说明:
1. 文中对各工具的评分基于个人实测,样本量有限(仅测试了10页PPT),不同类型的PPT可能有不同表现 2. 开源方案的技术细节基于公开文档和社区实践,但具体实施效果会因环境配置、数据质量而异 3. 对未来技术的展望(如2027年的端到端方案)属于基于当前趋势的合理推测,非确定性预测 4. 部分工具(如deckedit、lovart、DeepSeek-OCR)的评价基于有限的试用体验或文档研究,可能存在个人偏见 5. 文中提到的「80%还原度」是针对常规商务PPT的经验值,设计类PPT的还原度会显著降低 6. 价格信息可能随时间变化,建议以官网最新信息为准 7. 硬件配置和性能数据基于特定测试环境,实际表现可能因硬件差异而不同
建议:在实际应用前,建议先用自己的PPT样本测试各工具,选择最适合自己场景的方案。技术方案的实施需要一定的编程基础和调试能力。对于企业级应用,建议进行充分的POC测试和安全评估。
延伸阅读
• MinerU官方文档[1] - 如果你想深入了解PDF结构化解析,这是最好的起点 • PaddleOCR GitHub仓库[2] - 开源OCR工具的标杆,中文文档详尽 • python-pptx官方教程[3] - 想用代码生成PPT?从这里开始 • Segment Anything Model (SAM) 论文[4] - 了解图像分割技术的前沿进展 • LayoutParser文档[5] - 版面分析的利器,适合技术用户
相关标签
#PPT转换 #OCR #文档解析 #NotebookLM #PaddleOCR #图像处理 #办公自动化 #深度学习 #多模态大模型
引用链接
[1] MinerU官方文档: https://opendatalab.github.io/MinerU/[2] PaddleOCR GitHub仓库: https://github.com/PaddlePaddle/PaddleOCR[3] python-pptx官方教程: https://python-pptx.readthedocs.io/[4] Segment Anything Model (SAM) 论文: https://github.com/facebookresearch/sam3[5] LayoutParser文档: https://layout-parser.github.io/
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 高中化学必修二ppt | 03 硫酸
- 慢性腰痛PPT模板
- 【PPT】1000+套PPT和简历模板汇总(3.4更新),免费下载
- 255套工作计划Excel表格模板【免费下载】
- 【软件插件】专业Excel插件—ASAP Utilities v9.2.0.0安装教程及下载
- python操作本地Excel通过微信机器人通知推送
- 26年春新版《四年级下册科学课件ppt+教案+练习+视频素材》+(科教版)电子版可编辑
- 必看!《全员安全生产责任制》PPT,筑牢企业安全基石
- 26年春新版《五年级下册科学课件ppt+教案+练习+视频素材》+(科教版)电子版可编辑
- 别再用鼠标拖了!Excel Ctrl+X 隐藏用法,效率直接翻倍
