【开源】从 PDF、邮件到 Excel,Docs2KG 统一建图,80% 企业知识困在非结构化文档里?这个开源项目用图谱帮你“捞干货”
- 2026-07-16 10:45:07
Docs2KG 是怎么来的?
它到底好在哪?
和别的类似工具比,它适合谁、不适合谁?

🤔 Docs2KG 是怎么
来的?
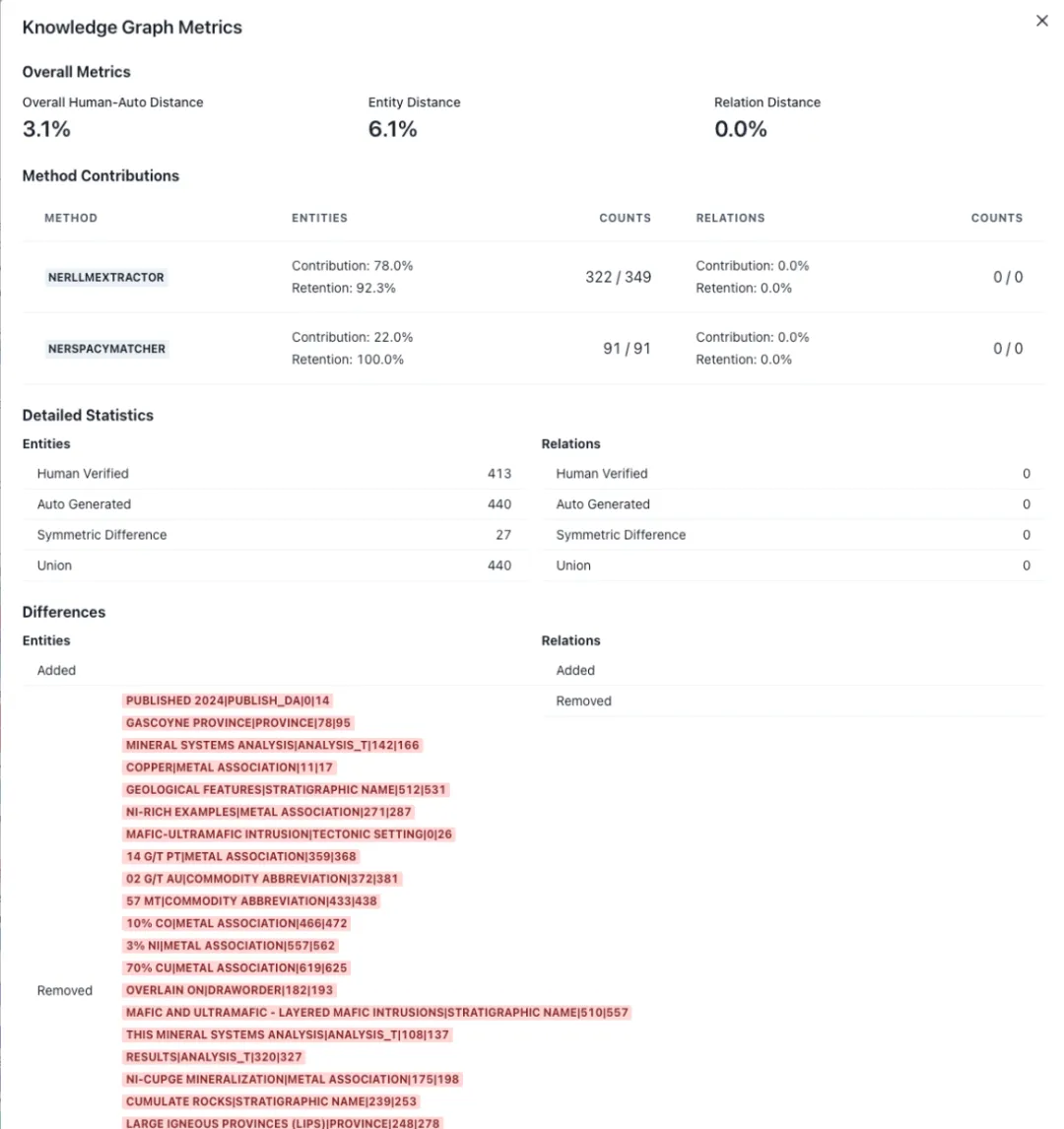
企业里 80% 的数据是非结构化文档,但这些文档散落在各处,格式各异,传统方法难以整合。
多模态数据提取:文本、表格、图片、图形,要从各种格式里都抽得出来。 多模型统一集成:不同模态要用不同的模型处理,怎么把它们塞进一个统一框架? 语义表示与溯源:不仅要理解内容,还要保留“这句话来自哪份文档、哪个段落”,否则无法追溯,也无法减少 LLM 的“幻觉”。
输入:各种文档(邮件、网页、PDF、Excel 等)。 输出:一张统一的知识图谱,既保留结构,又保留语义,还能追溯到原文。 特点:自动化、可扩展、支持人机交互,并且开源可用。
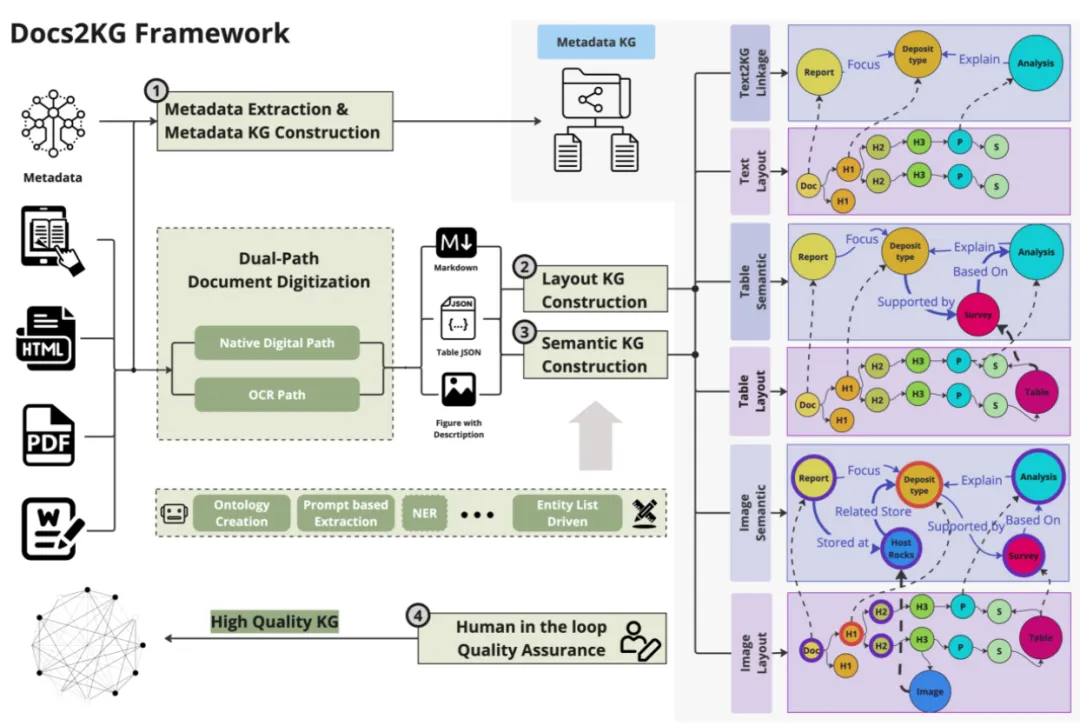
✨ Docs2KG 到底好在哪?
1. 全:支持多种文档类型
电子邮件(.eml) 网页(HTML) PDF(包括扫描件) Excel表格
2. 通:双路径数据处理
Markdown Converter 路径:对于 HTML、结构化较好的 PDF/Excel,先转成 Markdown/JSON,再用 XPath 等方式提取文本、表格、图片,同时保留文档树结构。 Image Converter 路径:对于扫描件、复杂排版的 PDF,先用深度学习模型做文档布局分析,识别出文本块、表格、图片及其位置,再分别提取内容。
3. 准:多模态统一知识图谱
模态内关系:比如标题和段落的“父子”关系,句子之间的“同时发生”、“支持”等语义关系。 跨模态关系:比如“这句话解释了这张图”、“这个表格补充了那段文字”等。
4. 开:开源且可扩展
🆚 和其他类似工具比,它适合谁?
项目 | 核心定位 | 优点 | 缺点 | 适合谁 |
|---|---|---|---|---|
Docs2KG | 从异构非结构化文档构建多模态知识图谱 | 支持多种文档类型、双路径处理、保留布局和来源、开源可扩展 | 上手有一定门槛,需要理解知识图谱和 LLM 的基本概念 | 企业知识管理、RAG 增强、多模态文档分析 |
Connected Papers | 文献引用关系可视化 | 专注于学术文献,图谱直观,适合文献调研 | 只处理学术论文,不支持其他文档类型 | 科研人员、学生 |
iText2KG | 从文本构建增量知识图谱 | 专注于文本,增量构建,适合动态更新知识 | 不支持多模态,对非文本信息(如表格、图片)处理能力有限 | 文本密集型场景,如合同、报告分析 |
LangChain+KG | LLM 与知识图谱的集成框架 | 灵活,可定制性强,适合构建复杂的 LLM 应用 | 需要自己整合文档解析、知识图谱构建等组件,开发工作量大 | 有较强开发能力的团队 |
传统 ETL+KG | 企业数据集成与知识图谱构建 | 成熟稳定,适合结构化数据处理 | 对非结构化文档处理能力有限,依赖大量人工规则 | 以结构化数据为主的企业 |
🚀 最后,给想动手的你一点建议
先跑通 Demo:去 Docs2KG 的官网或 GitHub,按照文档跑通一个简单的例子,比如处理一份 PDF 和一份 Excel,看看生成的知识图谱是什么样的。 再集成到现有系统:如果你有 RAG 系统,可以尝试用 Docs2KG 替换掉原来的文档解析和索引模块,看看效果有没有提升。 最后深入源码:当你熟悉了基本流程,再去看它的源码,理解双路径处理、多模态知识图谱构建等核心概念,相信你会对“文档智能”有更深的理解。
开源地址
关注公众号 回复 20260205 获得
猜您喜欢:
绝了!轻松做出媲美游戏级的数字孪生3D可视化效果!深度融合3D场景+物联网实时数据+多维UI图表
【开源】开箱即用的一体化后台,以SpringBoot3为底座,低代码 + 零 Controller:让后台系统飞起来
绝了!轻松做出媲美游戏级的数字孪生3D可视化效果!深度融合3D场景+物联网实时数据+多维UI图表
6元解锁620+优质开源项目!技术会员群上线,包括70+低开平台,50+AI平台
添加微信进相关交流群,
备注“微服务”进群交流
备注“低开”进低开群交流
备注“AI”进AI大数据,数据治理群交流
备注“数字”进物联网和数字孪生群交流
备注“安全”进安全相关群交流
备注“自动”进自动化运维群交流
备注“试用”可以申请产品试用
备注“定制”可以定制项目,全源码交付

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 效率黑盒:别再当人肉打字机了,截图即Excel,这个动作只用 0.1 秒
- 【52款】供应商考核评定表,Excel电子版免费下载!
- 【260款】报价单电子模板excel(免费分享,内容可编辑)
- 康复基本知识(PPT)
- 【19款】课时统计表(Excel电子版下载!)
- 【工具箱】告别手动拆分!这款免费 Excel 拆分小工具,帮你 10 秒搞定批量分表
- Excel2024中美化多类别多指标图表,适合呈现多周期多同环比的场景
- 扔掉Excel!用10行文字,画出让老板“一眼懂”的项目进度表
- 2026增值税新政培训课件(PPT可自行修改版)
- Excel 党看了也心动,Glide Data Grid 把表格交互细节卷到离谱
