PART 1 · 现状与路线
五个困境,三条路线
跟企业聊完之后,卡住的点高度集中:
FRICTION · 五个反复出现的企业困境
01
做完了,但不能用
品牌色不对、字体不对、Logo 位置不对。客户一看就知道是 AI 做的,不是因为内容差,是因为"长得不像我们公司的东西"。个人分享无所谓,企业发出去就是品牌事故。
02
AI 编数据
测试了国内一个工具,上传合同模板让它做培训 PPT,结果它把"15 个工作日内支付"改成了"15 天内付款"。AI 在"帮你写得更通顺",但企业场景里准确比通顺重要。提案里出现一个编造的案例、一个不存在的数据来源,这份 PPT 就是风险来源。
03
改一个字就要重来
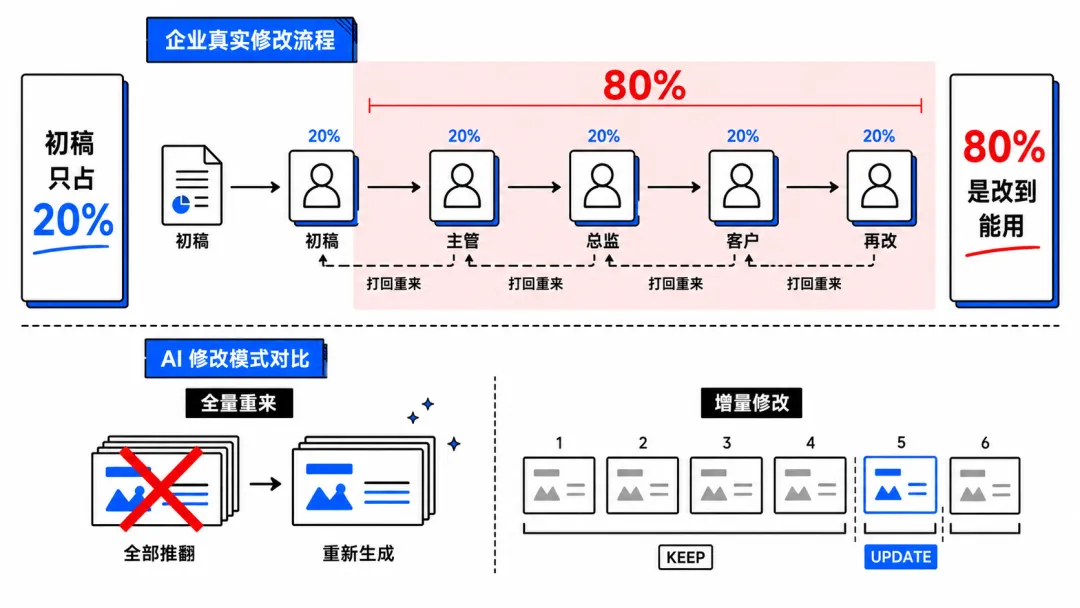
企业做 PPT,初稿只占 20%,80% 是改到能用:主管看→改方向→总监看→又改→客户看→再改。现有 AI PPT 的改动逻辑是"重新生成",花 30 分钟调好的第 3、7、12 页,改一次结构就全丢了。
04
使用门槛高,企业合规也是问题
Skill 型方案视觉很好,但使用者需要熟悉命令行、配置开发环境、选模板、跑验证脚本。企业里真正大量做 PPT 的是销售经理、市场主管、行政助理,不是技术团队。更现实的问题:这些方案大多依赖海外平台(如 Claude Code),Anthropic 2025 年封禁中国 IP,企业在国内合规部署本身就是障碍。
05
成本线性增长
不只是输出端,输入端也是大头。全部模板规则、用户材料、上下文要塞进 prompt,动辄几万 input token。一份 20 页 deck 迭代几轮,总 token 轻松破 10 万。
企业真实修改流程 vs AI 修改模式对比
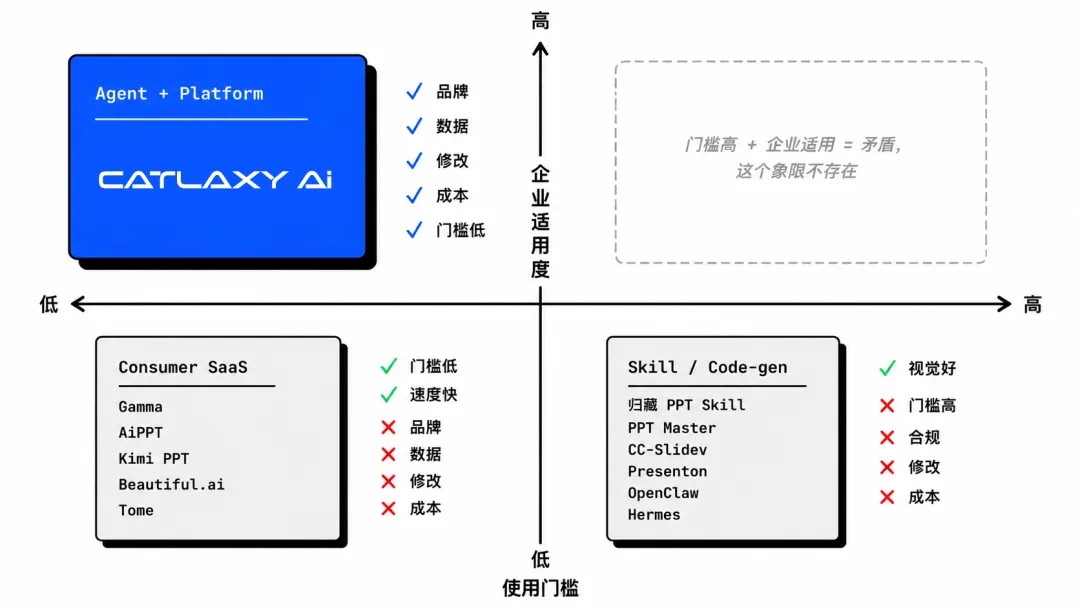
市场上有三条主流路线,各自解了一部分问题。
路线一:Consumer SaaS
GAMMA · AIPPT · KIMI PPT · BEAUTIFUL.AI
● 做对了什么:把"从零到有"的门槛降到最低。一句话出一份 deck,Gamma 做到 1 亿美金 ARR、7000 万用户。需求是真实的。
天花板:Tome 的死亡是最好的证据:2500 万用户,年收入不到 400 万美金。"生成初稿"用户愿意用,不愿意付费。方法论锁在黑箱,每次从零猜你要什么。一旦需要精细调整,就回到手动模式。品牌无法锁定,修改只能重来。五个困境一个都没解。
适合:个人用户、快速原型、不需要品牌一致性的内部分享。
路线二:Skill / Code-gen
归藏 PPT SKILL · PPT MASTER · CC-SLIDEV · PRESENTON
● 做对了什么:证明了 LLM 直写 HTML 可以做出媲美设计师的视觉效果。归藏的 PPT Skill 用瑞士国际主义风格、22 种锁定布局和验证脚本来保证美学一致性,"保护美学优先于自由"这个设计哲学我完全认同。这条路线在开发者社区得到了强烈认可,说明市场确实需要超越传统 PPT 的视觉表现力。
天花板:LLM 同时承担方法论 + 内容 + 渲染三件事。来看真实消耗:
TOKEN ANATOMY · Skill 路线的真实消耗
输入
模板规则 + 用户材料全文 + 上下文 = 海量 input
Skill 的 prompt 要塞进完整模板规则(布局约束、配色规范、验证逻辑)、用户上传的原始内容、以及对话上下文。一份材料丰富的提案,input 轻松 3-5 万 token。而且用户材料是原封不动塞进去的,没有预处理,没有摘要提取。
输出
每页 500-1500 token 的完整 HTML / CSS / SVG
20 页 deck,output 1-3 万 token。迭代三轮,每轮全量重新生成(没有增量修改),output 总量 3-9 万。
实测
公开 benchmark:同一个任务,成本差 9 倍
V2EX 公开测试(OpenClacky 1.0),四个 Agent 用同一模型(Claude Opus)生成同一份 10 页 deck,OpenRouter 账单第三方验证:OpenClaw $5.07 · Hermes $10.96(最低的两个 Agent 分别为 $1.23 和 $1.45,但它们专门做了 token 优化,不代表典型 Skill 体验)。这还只是 10 页初稿,企业场景 20 页加三五轮修改(每轮全量重来),单份成本 $20-50。
个人偶尔做一份惊艳的 deck 完全值得,但企业把 PPT 当日常汇报工具时,周会、月报、复盘、培训全在用,体量完全不是一个量级。
Skill 路线解了品牌问题的一部分(可以锁定模板风格),但其他四个困境都还在:AI 仍然会编数据,改一个字还是要全量重新生成,只有开发者能用,而且成本随页数和迭代次数线性增长。
适合:开发者个人演讲、技术分享、Demo Day、一次性场景。
路线三:Agent + Platform(Catlaxy Deck 的选择)
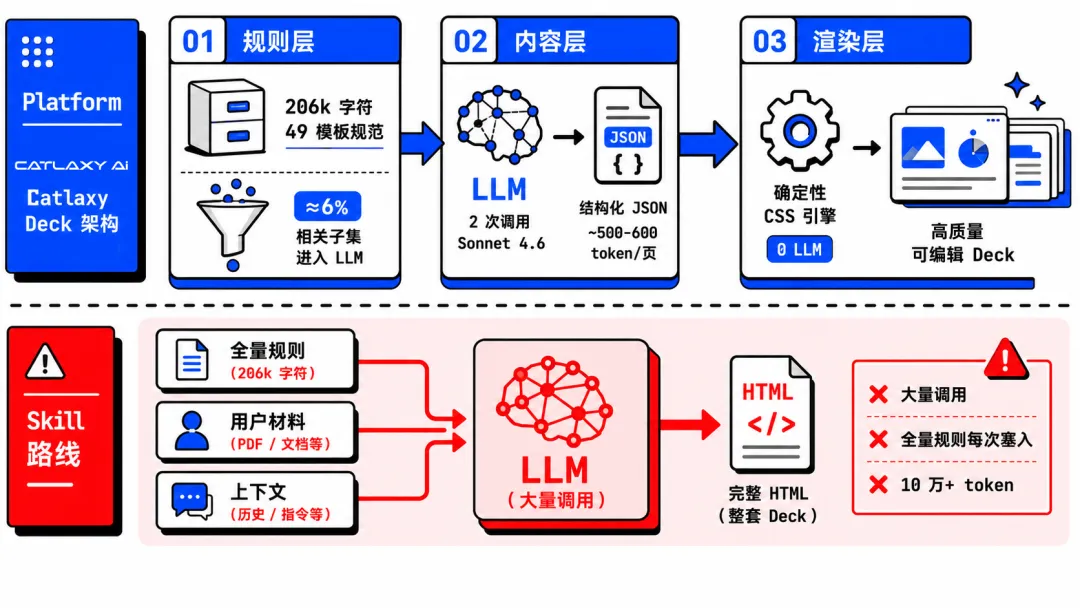
前两条路线的共同问题是:AI 同时负责理解需求、组织内容、生成视觉,什么都做,什么都不够好。Catlaxy Deck 的做法是把这三件事拆开,让 Agent 只做它最擅长的判断,渲染和规则交给确定性系统。这是笔记 #1 提到的"AI 适合做判断,不适合做编排"在 PPT 场景的落地。核心是三层分离:
三层分离架构
01 ·
规则层:系统编码 + 智能筛选
49 个模板的完整规范(206k 字符)编码在系统里。Code 层按当前任务筛选相关子集,只把约 6% 的规则送进 LLM。Skill 路线则把全部规则塞进每次 prompt。
02 ·
内容层:结构化 JSON,约 500-600 token/页
Agent 产出的是结构化 JSON(每页约 500-600 token),不是完整 HTML/CSS/SVG(每页 1000-1500 token)。输出体积压缩约 50%。
03 ·
渲染层:确定性引擎,0 LLM 消耗
同一份 JSON 永远渲染出同一个视觉结果。品牌一致性由 CSS token 系统保证,不靠 LLM 判断。
关键区别:整份 20 页 deck 的核心生成只需 2 次 LLM 调用(一次规划、一次内容),总计约 6-7 万 token。Skill 路线每次生成需要大量 LLM 来回,总计 10 万+ token。
Platform 三层分离架构 vs Skill 路线
输入端也不一样。平台先用文档解析、视觉理解、数据分析等工具处理用户材料,提取结构化摘要后再给 LLM,不是把原始 PDF 整份塞进 prompt。输入筛选 + 输出压缩 + 调用次数锐减,三重降本。这是笔记 #1 里"标准化输入,个性化输出"在这个场景的落地。
适合:企业重复生产场景:销售提案、季度汇报、客户复盘、培训材料。需要品牌一致、数据准确、多人修改、成本可控的场景。
PART 2 · CATLAXY DECK 落地实践
Catlaxy Deck 怎么过这五关
Agent 是终局形态(笔记 #1 聊过了),但不是所有 Agent 都能在企业用。以下是 Catlaxy Deck 的做法。
企业场景下编造数据的后果比"PPT 丑一点"严重得多。Catlaxy Deck 的做法是:数据先经过后端的分析模型处理和验证,AI 只负责解读已验证的结果,不直接从原始材料里"猜"数字。用户上传的文件、数据分析结果、搜索结果、对话中确认过的信息,这四类是 Agent 唯一可用的信息源。缺数据?写"待补充"。不编。
举个具体的例子:用户只给了起点、终点和增长率,系统不会硬画一张年度趋势图(中间的数据是编的),而是用数据卡片直接呈现已有数据。数据不够就不画,而不是"猜一个看起来合理的"。
这不是一条 prompt 能解决的。数据来源追溯、前端来源标注、敏感内容合规拦截,都是系统层面的硬约束,不依赖模型的"自觉"。
Agent 的修改逻辑不是"重新生成 20 页",而是四种动作:
修改协议 · KEEP / UPDATE / ADD / DELETE
● KEEP:没人说要改,保留原样。
● UPDATE:只重写用户说要改的字段。
● ADD:新增一页,放到指定位置。
● DELETE:删掉这一页,前后衔接。
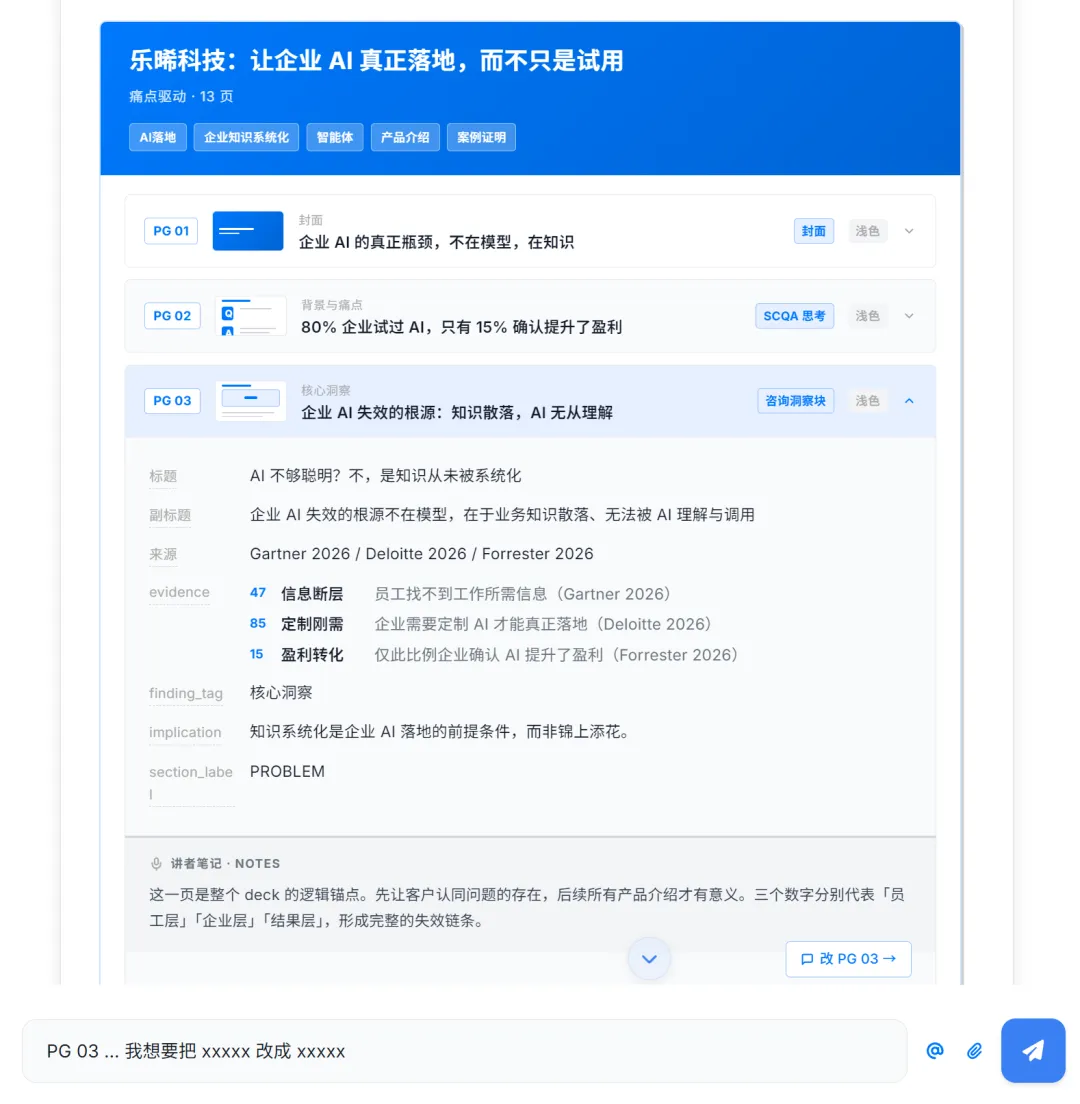
Catlaxy Deck Planning 界面:用户在卡片上直接修改内容,不碰模板
改了第 5 页的标题,第 3 页和第 12 页不会被动。用户只改内容,不碰模板和排版,平台自动处理布局,改内容不会破坏设计。
除了对话式修改,平台还提供可视化编辑器,可以直接在 deck 上改文字、调结构。对话做大改,编辑器做微调,两种方式配合使用。
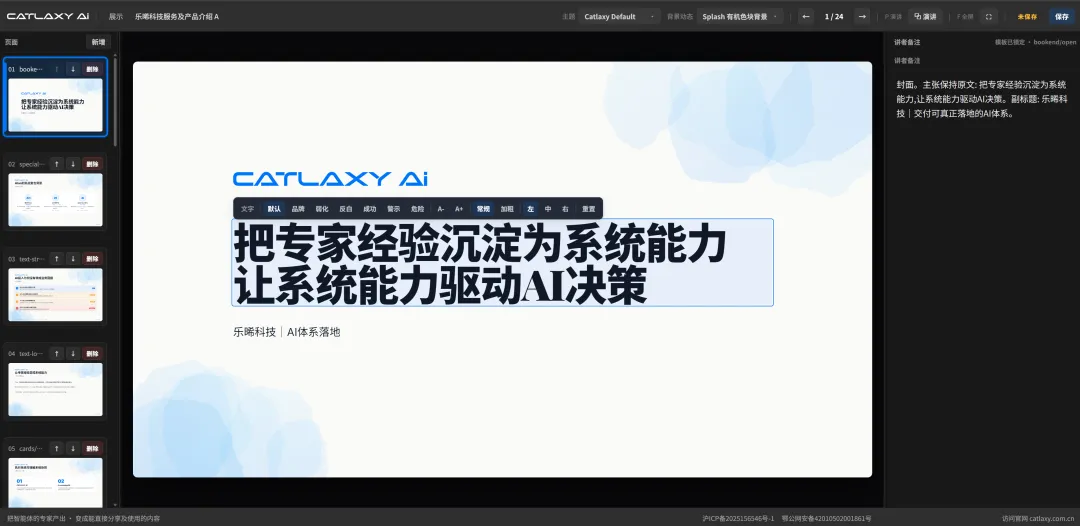
Catlaxy Deck 可视化编辑器
Catlaxy Deck 内置 49 个模板,覆盖 11 个场景族:首尾页、数据卡片、流程图、对比矩阵、时间线、长文排版、图文混排等。每个模板都经过设计验证,Agent 根据内容自动匹配最合适的布局,不需要你自己选。
企业可以根据自身需求定制品牌色、字体、Logo 和视觉风格,配置一次之后所有产出自动套用。不需要每次生成时反复调整,品牌一致性由平台保证。
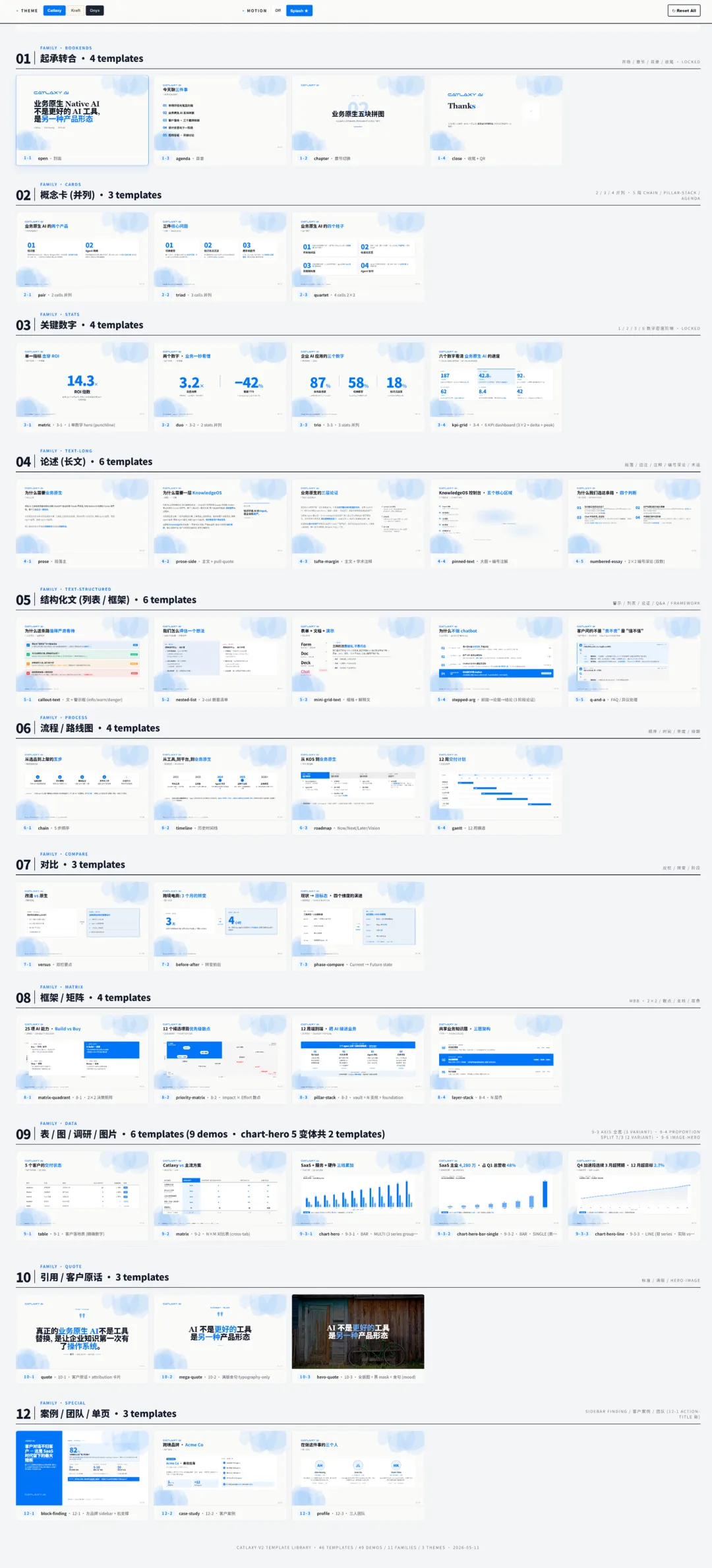
Catlaxy Deck 部分模板展示
Agent 做 PPT 的信息来源不只是"你打的那句话"。Catlaxy Deck 支持四类信息源:
● 上传文件:PDF、Word、Excel、图片都行,平台自动解析提取关键信息。
● 数据分析结果:平台内置真正的数据分析能力(不是 AI 读数字猜结论),分析结果可以直接作为 PPT 的数据来源。
● 其他 Agent 的产出:在 Catlaxy 平台上完成的分析、研究、洞察,可以直接引用到 Deck Agent 作为内容来源。一个平台内完成从研究到演示的完整链路。
● AI 搜索:Agent 可以主动搜索行业数据和竞品信息,搜索结果遵守事实边界规则,标明来源。
上传一份文件,3 分钟第一版 deck 就出来了。PDF、Word、Excel、图片都行,说一句"给客户做产品 pitch,10 分钟"就够了。接下来是两阶段工作流:
两阶段工作流 · 先规划,再执行
01 ·
规划
Agent 先做判断:选叙事框架(痛点驱动、金字塔、故事型、数据型、方案型),定节奏(10 分钟 ≈ 10-15 页),从 49 个模板里选最匹配的布局。方案给你过目,不满意可以调。
02 ·
内容
确认规划后,Agent 直接完成每页内容。如果信息不够,会用结构化表单向你补问,不是开放式的"你想怎么做",而是具体的选择题。
数据可视化也是结构化的。Agent 写简化的图表描述(类型、数据、标签),平台渲染成可交互图表。Agent 不碰像素。
全程不需要写代码、不需要懂 HTML。
Catlaxy Deck Agent 对话界面
以下数据来自 Catlaxy Deck 生产环境实测,Skill 路线参考 V2EX 公开 benchmark(10 页 deck $5-11):
| | |
|---|
| | |
| 完整 HTML/CSS/SVG1000-1500 token | |
| | |
| | |
| | |
差距超过 25 倍。以上是核心生成链路的成本(规划 + 内容生成),不含文档解析、搜索、视觉理解等前置处理。即便加上这些,总成本仍然远低于 Skill 路线,因为前置处理是一次性的,不随迭代次数线性增长。
而且这个成本是在使用当代主流模型(Sonnet 4.6)的前提下实现的,不是靠降级模型省钱。核心的规划和内容生成用 Sonnet 4.6,辅助任务用轻量模型,多模型混合调度。Skill 路线要求全程使用顶级模型才能写出合格的 HTML,模型选择没有弹性。