
AI阅读
核心速览
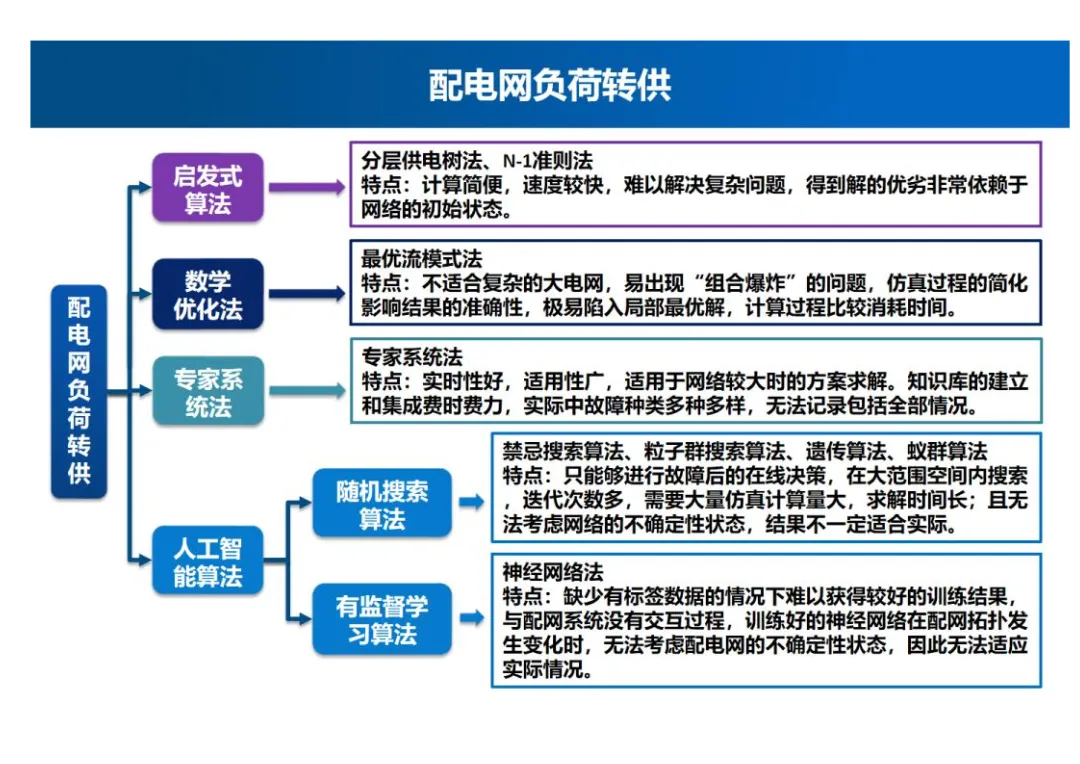
本文主要探讨了强化学习在配电网负荷转供中的应用,包括Reward实现、电压越限惩罚、智能体与配电网环境的交互过程、强化学习算法选择、模型训练及负荷转供效果等内容。
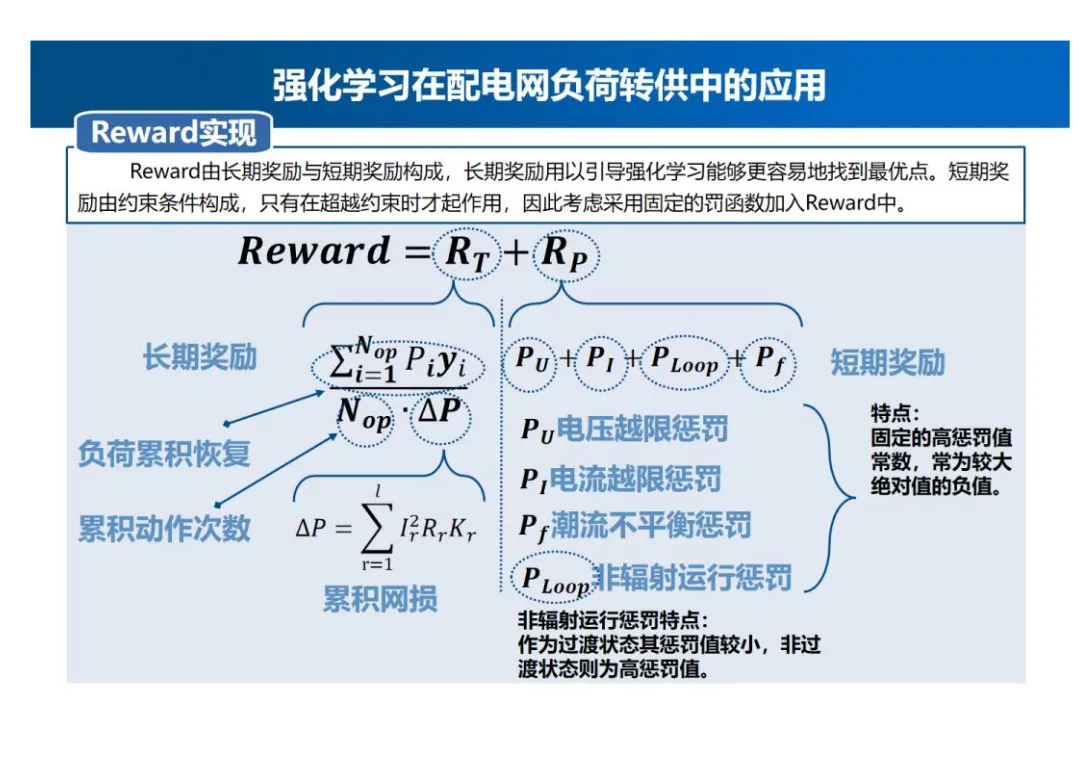
Reward实现
- Reward构成:Reward由长期奖励与短期奖励构成,长期奖励用以引导强化学习能够更容易地找到最优点。短期奖励由约束条件构成,只有在超越约束时才起作用,因此考虑采用固定的罚函数加入Reward中。
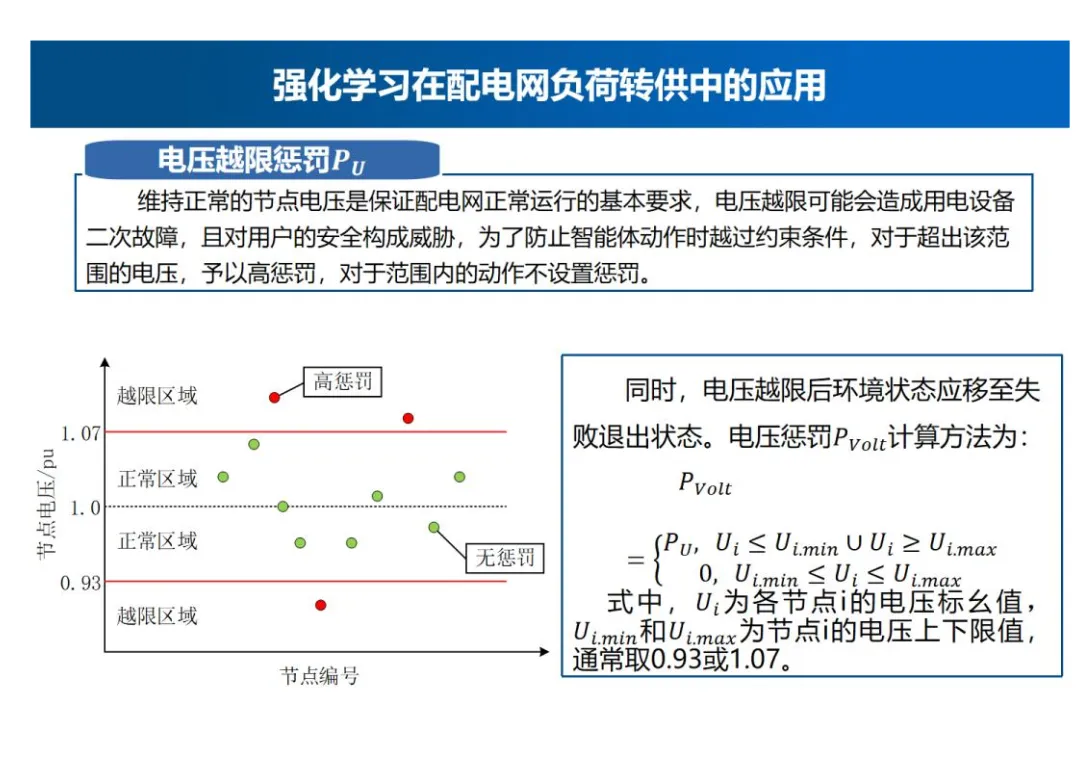
电压越限惩罚Pu
- 电压越限惩罚机制:维持正常的节点电压是保证配电网正常运行的基本要求,电压越限可能会造成用电设备二次故障,且对用户的安全构成威胁,为了防止智能体动作时越过约束条件,对于超出该范围的电压,予以高惩罚,对于范围内的动作不设置惩罚。
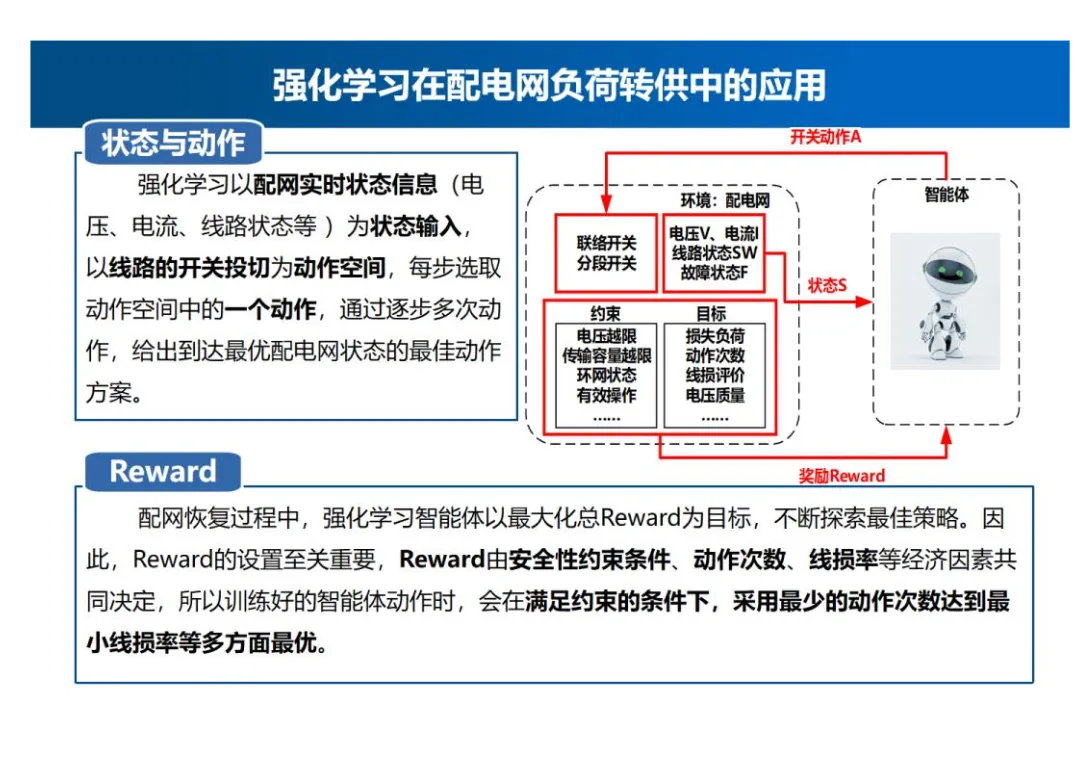
智能体与配电网环境的交互过程
- 交互流程:Agent从配电网中获得当前所处的状态S,即系统实时量测量;循环至完成本次故障恢复,对于动作空间的每个动作即所有的线路投切,Agent根据该状态下每个动作的评价值Q,选取其中一个最佳的动作A,即改变其中一条线路的状态;当Agent所选择的动作作用于配电网时,配电网发生变化,即配电网转移至新状态并对Agent的动作进行奖励或惩罚Reward;智能体通过Reward进行学习并更新评价值Q。以上为进行一次动作的过程,若操作一条线路无法完成恢复,循环进行多次动作构成有先后顺序的动作序列,即给出负荷转供的决策结果。
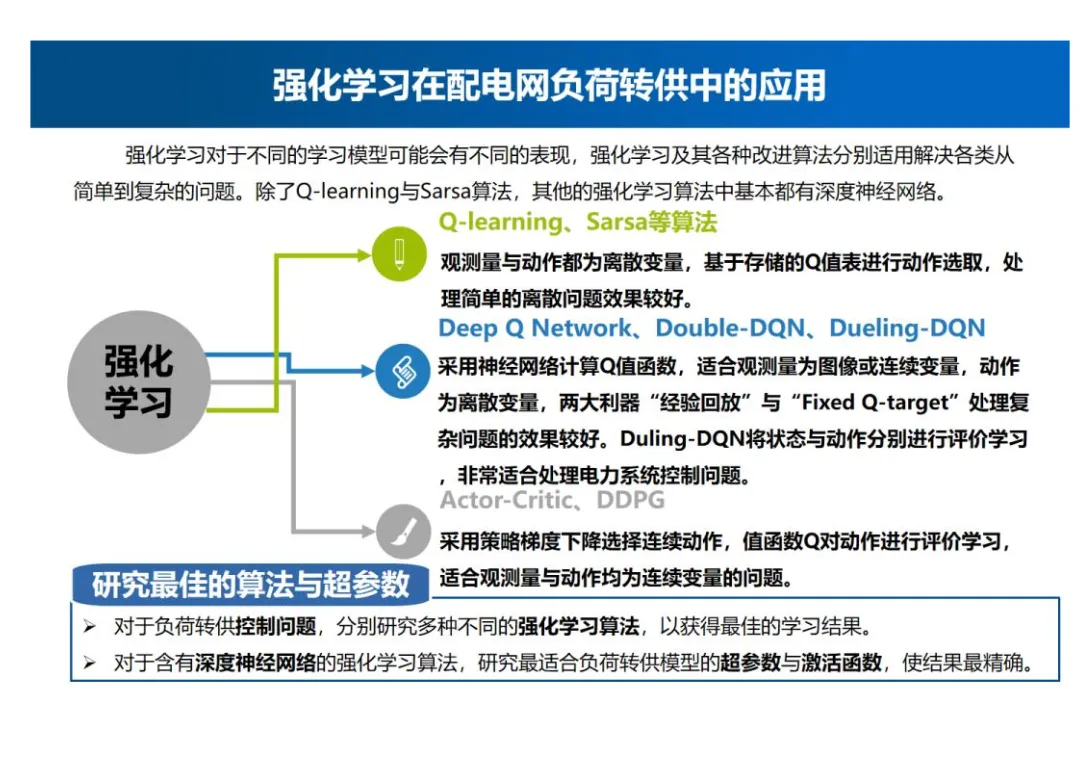
强化学习算法选择
- 不同算法特点:Q-learning、Sarsa等算法观测量与动作都为离散变量,基于存储的Q值表进行动作选取,处理简单的离散问题效果较好。Deep Q Network、Double-DQN、Dueling-DQN采用神经网络计算Q值函数,适合观测量为图像或连续变量,动作为离散变量,两大利器“经验回放”与“Fixed Q-target”处理复杂问题的效果较好,Duling-DQN将状态与动作分别进行评价学习,非常适合处理电力系统控制问题。Actor-Critic采用策略梯度下降选择连续动作,值函数Q对动作进行评价学习,适合观测量与动作均为连续变量的问题。
- 研究方向:对于负荷转供控制问题,分别研究多种不同的强化学习算法,以获得最佳的学习结果。对于含有深度神经网络的强化学习算法,研究最适合负荷转供模型的超参数与激活函数,使结果最精确。
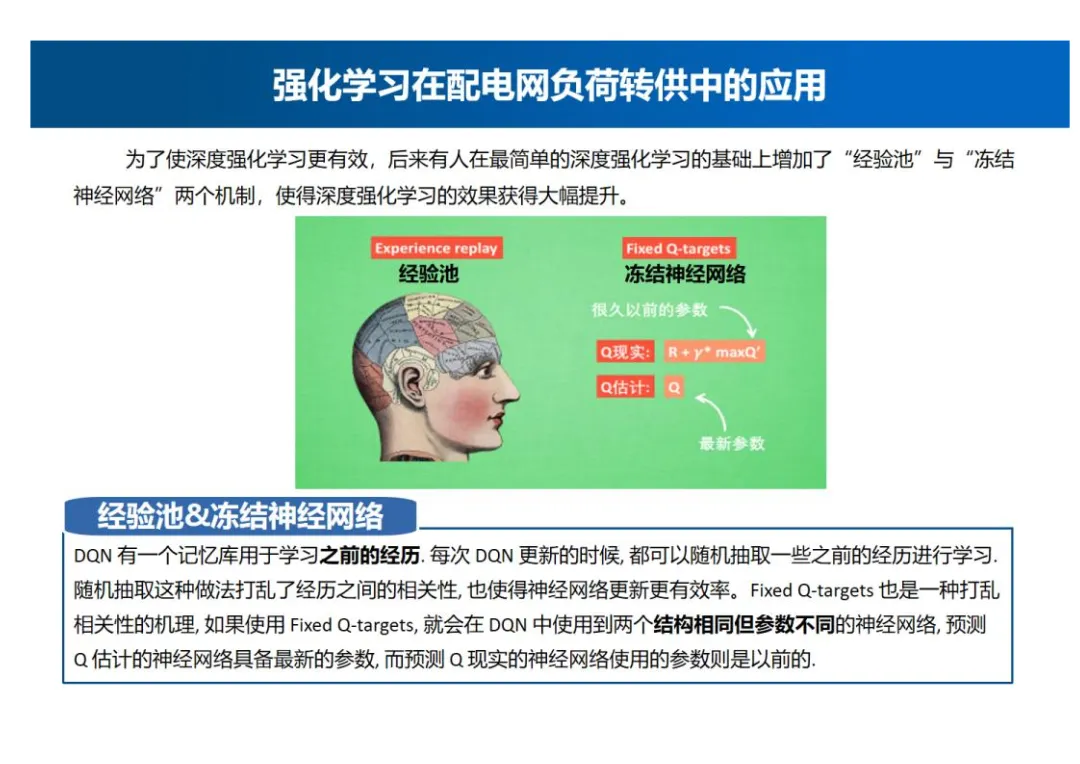
深度强化学习改进机制
- 经验池与冻结神经网络:为了使深度强化学习更有效,在最简单的深度强化学习的基础上增加了“经验池”与“冻结神经网络”两个机制。经验池是DQN的记忆库,用于学习之前的经历,每次更新时随机抽取一些之前的经历进行学习,打乱经历之间的相关性,使神经网络更新更有效率。Fixed Q-targets会在DQN中使用两个结构相同但参数不同的神经网络,预测Q估计的神经网络具备最新的参数,而预测Q现实的神经网络使用以前的参数,也是一种打乱相关性的机理。
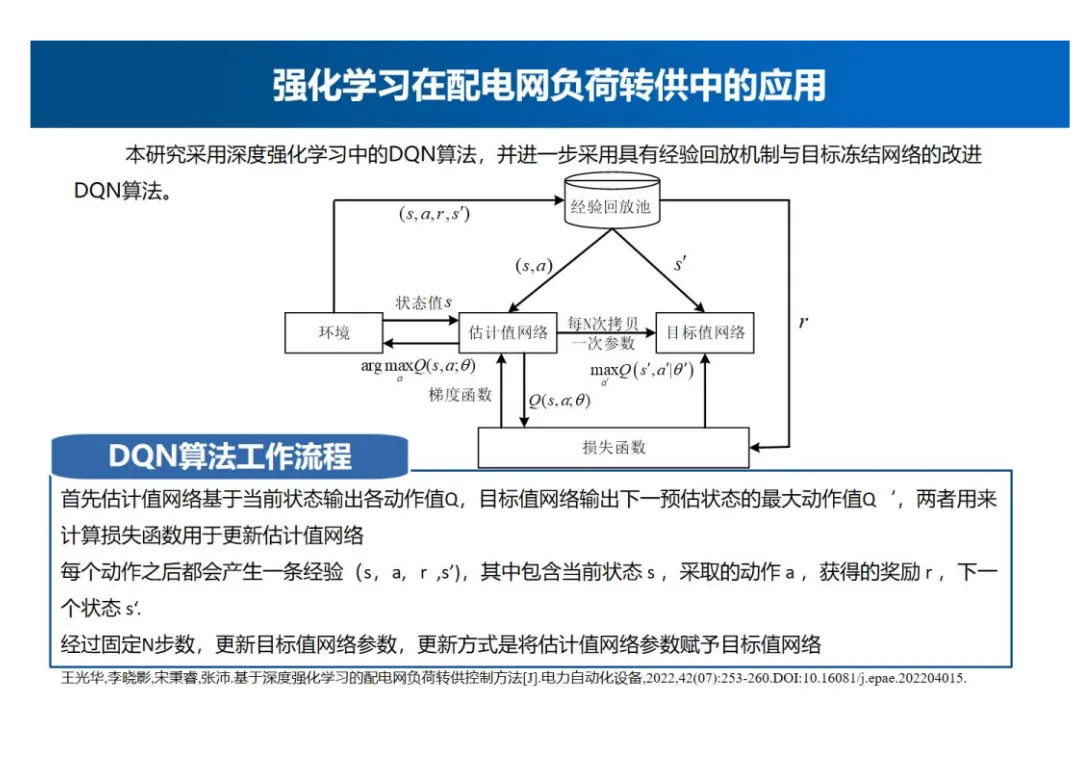
模型训练
- 采用算法:本研究采用深度强化学习中的DQN算法,并进一步采用具有经验回放机制与目标冻结网络的改进。首先估计值网络基于当前状态输出各动作值Q,目标值网络输出下一预估状态的最大动作值Q′,两者用来计算损失函数用于更新估计值网络。每个动作之后都会产生一条经验(s,a,r,s'),其中包含当前状态s,采取的动作a,获得的奖励r,下一个状态s'。经过固定N步数,更新目标值网络参数,更新方式是将估计值网络参数赋予目标值网络。
- 训练环境:采用OpenDSS搭建仿真训练环境,OpenDSS是美国电科院研发的开源三相配电网潮流仿真软件,拥有丰富的COM接口,支持Matlab、Python等编程语言,调用响应速度快。使用Python语言对OpenDSS的COM接口进行调用,共同搭建复杂仿真训练环境。使用OpenDSS软件模拟人工对开关的操作,并读取电网中的电压、电流、相角等实时状态量,以模拟SCADA系统。通过电压质量、电流越限、操作次数、负荷切除量、线损、环网孤岛判断等原则计算Reward,其中负荷切除量、线损、环网孤岛不可直接读取,需要设计相关算法。
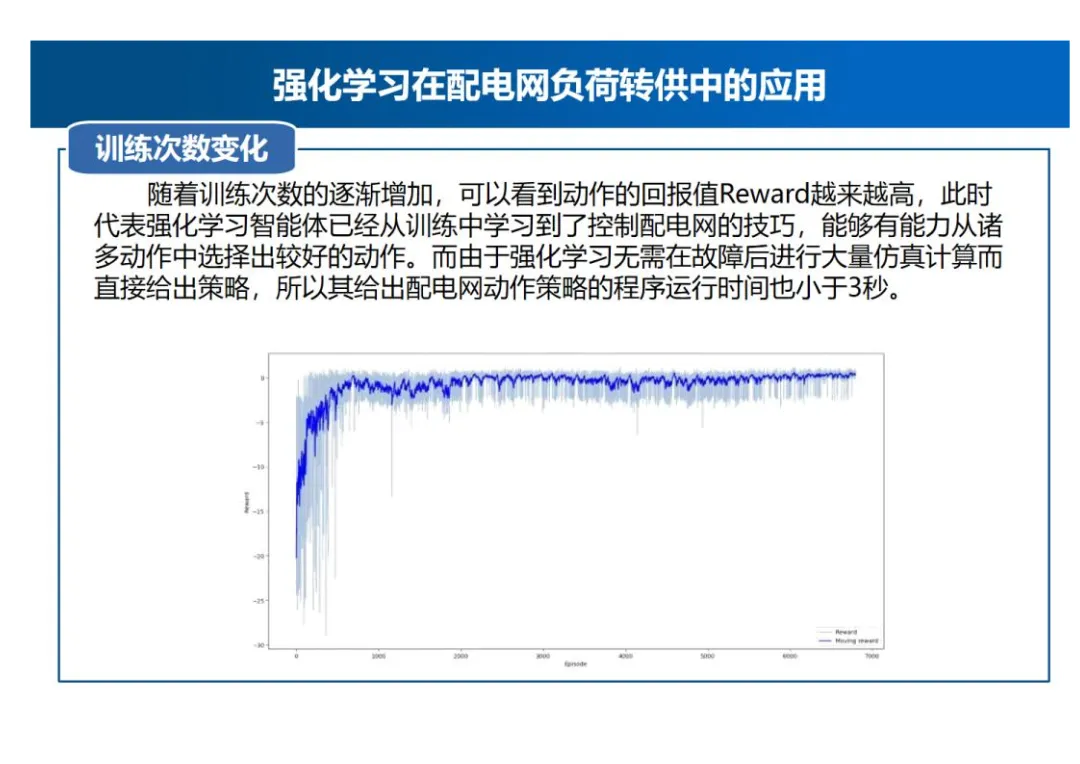
训练效果与负荷转供效果
- 训练次数变化:随着训练次数的逐渐增加,动作的回报值Reward越来越高,强化学习智能体从训练中学习到了控制配电网的技巧,能够从诸多动作中选择出较好的动作。由于强化学习无需在故障后进行大量仿真计算而直接给出策略,所以其给出配电网动作策略的程序运行时间小于3秒。
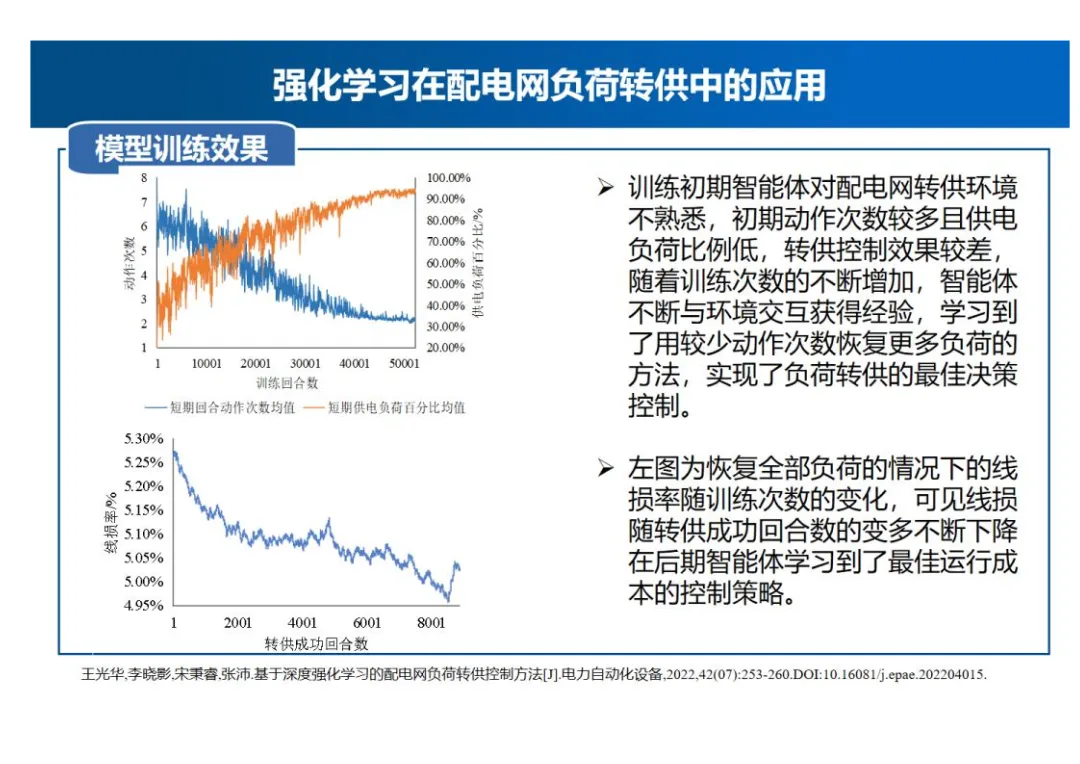
- 模型训练效果:训练初期智能体对配电网转供环境不熟悉,初期动作次数较多且供电负荷比例低,转供控制效果较差,随着训练次数的不断增加,智能体不断与环境交互获得经验,学习到了用较少动作次数恢复更多负荷的方法,实现了负荷转供的最佳决策控制。左图为恢复全部负荷的情况下的线损率随训练次数的变化,可见线损随转供成功回合数的变多不断下降,在后期智能体学习到了最佳运行成本的控制策略。
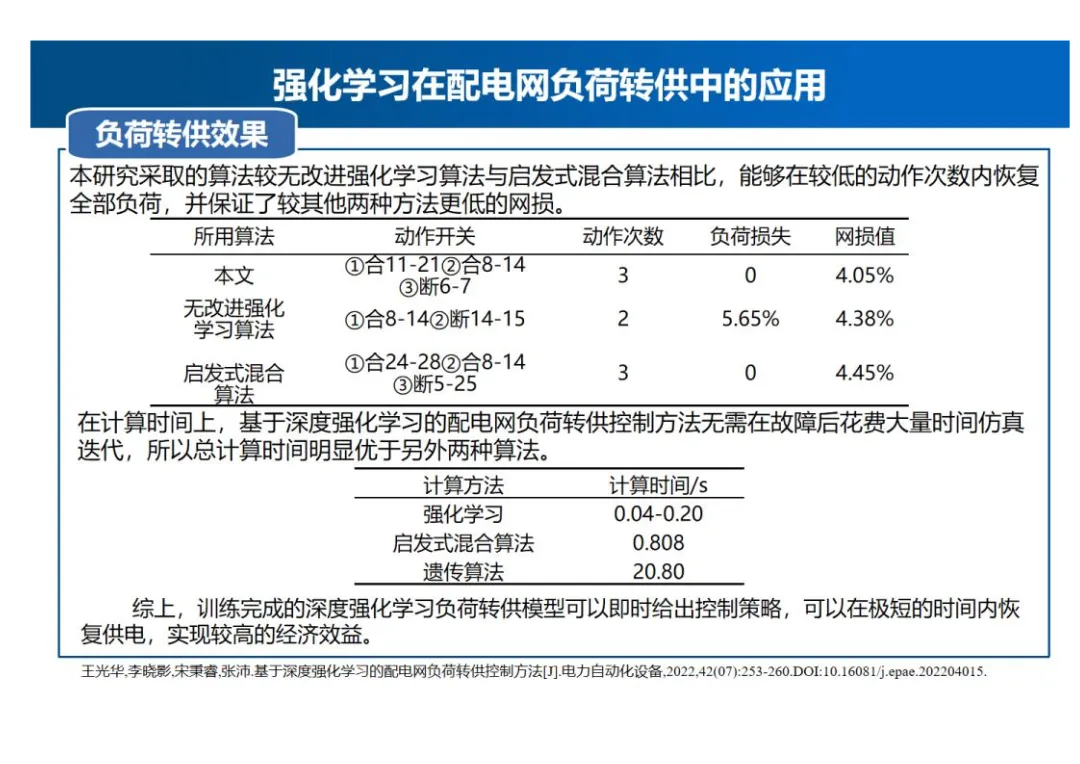
- 负荷转供效果对比:本研究采取的算法较无改进强化学习算法与启发式混合算法相比,能够在较低的动作次数内恢复全部负荷,并保证了较其他两种方法更低的网损。在动作开关方面,本文算法为①合11-21②合8-14③断6-7,动作次数3次,负荷损失0,网损值4.05%;无改进强化学习算法动作开关为①合8-14②断14-15,动作次数2次,负荷损失5.65%,网损值4.38%;启发式混合算法动作开关为①合24-28②合8-14③断5-25,动作次数3次,负荷损失0,网损值4.45%。在计算时间上,基于深度强化学习的配电网负荷转供控制方法无需在故障后花费大量时间仿真迭代,总计算时间明显优于另外两种算法,强化学习计算时间为0.04-0.20S,启发式混合算法为0.808S,遗传算法为20.80S。综上,训练完成的深度强化学习负荷转供模型可以即时给出控制策略,可以在极短的时间内恢复供电,实现较高的经济效益。
调用OpenDSS自动恢复线路与配电网负荷转供演示
- 调用OpenDSS自动恢复线路:使用Matlab、Python等编程调用与操作电力系统仿真软件OpenDSS,并完成实时电流、电压、相角等电气信息量的读取与处理输出。三步演示负荷转供过程,首先载入正常运行电网使其中一个辐射网发生故障,再合上联络开关,出现部分电压偏低,切除部分负荷后恢复正常。
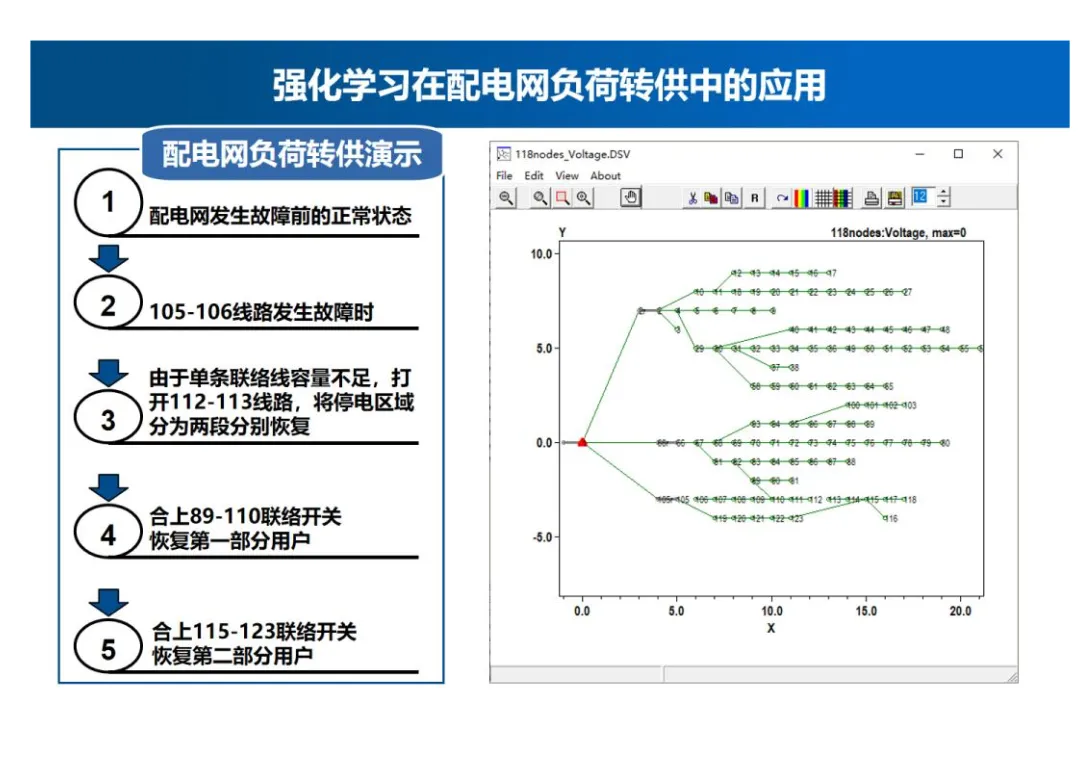
- 配电网负荷转供演示:配电网发生故障前处于正常状态,105-106线路发生故障时,由于单条联络线容量不足,打开112-113线路,将停电区域分为两段分别恢复,合上89-110联络开关恢复第一部分用户,合上115-123联络开关恢复第二部分用户。








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
