大厂怎么做垂类模型?从GLM5报告PPT生成技术看垂直场景的机会和对小团队的启发
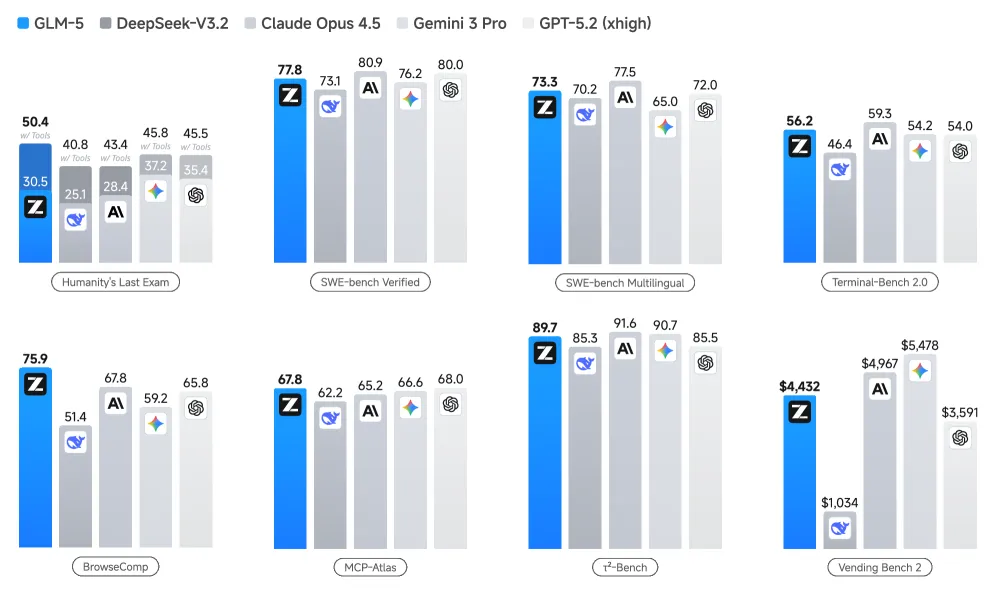
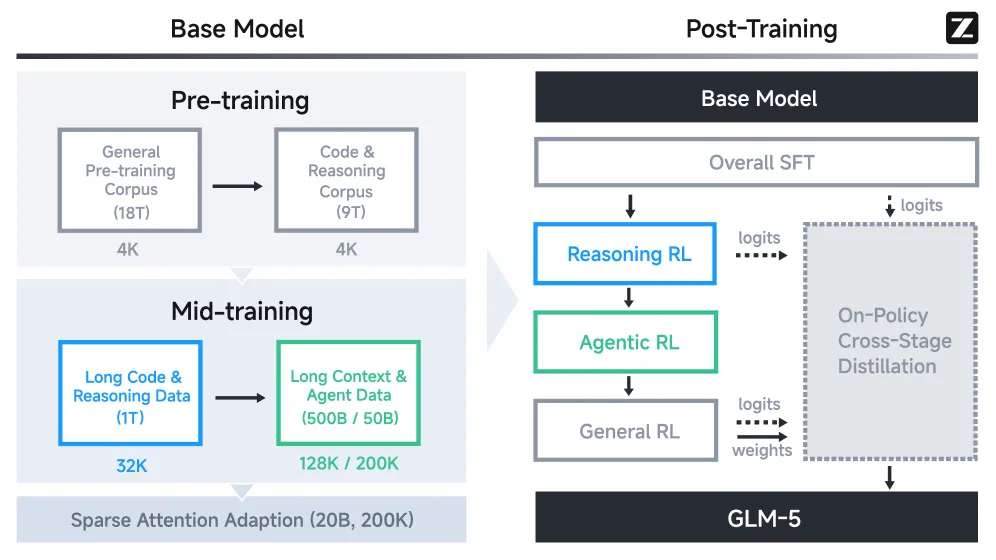
GLM5技术报告发布了,细节很多,比如Muon优化器、DSA结构等,数据和训练流程也做了具体的介绍。模型benchmark效果也很不错。智谱对PPT生成这个垂直场景做了技术层面的介绍,这在大模型技术报告中比较少见。大模型对垂类场景的影响是很多创业公司关注的问题。借助智谱的技术报告,可以看看大模型对垂类场景是怎么优化的。GLM-5采用了一种自改进的训练流程来训练模型的PPT生成能力。流程从监督微调开始,让模型掌握基本的幻灯片制作能力,之后通过强化学习配合多级奖励机制进行优化。- HTML代码层面的静态属性,包括元素定位、间距、配色、字体等样式声明,通过规则约束确保代码可解析且符合设计规范。
- 运行时动态渲染属性,DOM渲染过程中提取元素尺寸、边界框等几何指标,通过分布式渲染服务获取真实的布局数据,避免奖励作弊行为。
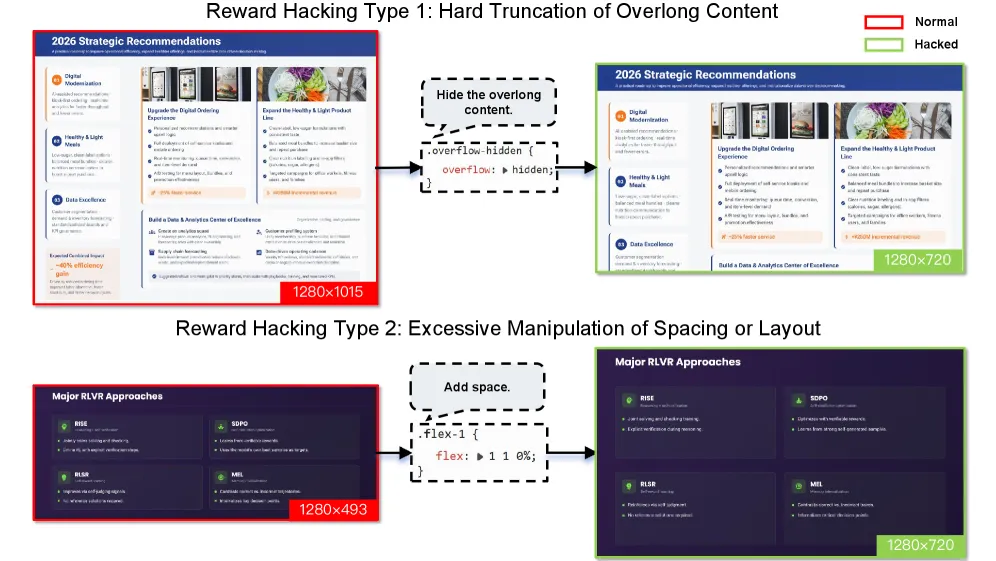
- 视觉审美,比如检测异常空白分布等模式,进一步优化整体构图平衡。
训练过程中采用了多种稳定化策略。动态采样会概率性丢弃结构简单的样本,让复杂页面得到充分训练;同一样本的不同生成结果分散到多个批次中,减少优化偏差。这些设计保障了强化学习阶段的稳定性。拒绝采样阶段将奖励函数转化为数据过滤工具。在页面层面筛选代码有效性和编译可行性,在轨迹层面检查工具执行正确性和内容多样性,最终从多个候选中选出最佳样本。这种Best-of-N策略有效提升了训练数据的质量分布。掩码机制解决了部分页面存在缺陷的轨迹处理问题。系统能够自动识别并屏蔽问题页面,保留同一条轨迹中的高质量内容,避免了因少数坏页而丢弃整批数据造成的浪费,提高了数据利用效率。实验数据显示,生成页面符合16:9标准比例的比例从40%提升至92%,页面溢出问题大幅减少。在与GLM-4.5的对比中,GLM-5在内容质量、布局合理性和视觉美感三个维度分别取得60%、57.5%和65%的胜率,总体胜率达到67.5%,验证了训练框架的有效性。智谱这次技术报告的价值,展示了PPT生成的技术细节,也揭示了一个趋势:通用大模型的竞争会逐步下放到垂直领域,解决核心垂直领域的共性问题。对创业公司来说,通用模型的垂类能力增强是压力,也存在机会。特定场景下建立定义标准的能力,仍然是小团队可以构建的护城河。知道什么是好的往往比怎么生成更难,智谱的技术路线,或许给所有做垂类应用的团队提供了一个可参照的优化框架。奖励函数设计比模型架构更重要
别急着改网络结构,先把"什么是好的"定义清楚。智谱的三层奖励机制说明,垂类优化关键是建立从代码正确性到视觉审美的递进标准。小团队资源有限,更要把精力放在设计合理的评估体系上,而不是盲目追新架构。SFT和强化学习的标准流程值得跟
监督微调打基础,强化学习做优化,这个套路是通用的。智谱的特别之处在于强化阶段的多级奖励和稳定化策略,这些工程细节不耗算力但效果实在。小团队可以直接照搬这个流程,重点是根据自己的业务场景调整奖励函数的具体指标。业务理解要转化成算法语言
智谱能把PPT生成做好,不是因为懂设计,而是把设计规则翻译成了代码层面的约束。小团队的优势就在业务理解深,关键是把这种理解变成可量化的指标。比如做电商文案生成,"促销感强"这个模糊概念,可以拆解为感叹号数量、emoji使用密度、紧迫感词汇占比这些具体规则。用计算换数据质量
拒绝采样和Best-of-N策略的核心是用推理阶段的计算来筛选训练数据。小团队采数据难,更要在筛选上下功夫。与其爬一百万条脏数据,不如用奖励函数筛出十万条干净的,训练效果往往更好。先解决"能用"再追求"好用"
智谱的数据从40%合规率提到92%,说明垂类优化是分阶段的。小团队别一上来就追求生成完美作品,先把基础功能做扎实:格式不报错、布局不溢出、内容不跑偏。这些底线问题解决了,再往上加审美层的要求。既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧。谢谢你看我的文章,我是FlowAI,分享AI相关干货与观点,我们下次再见。