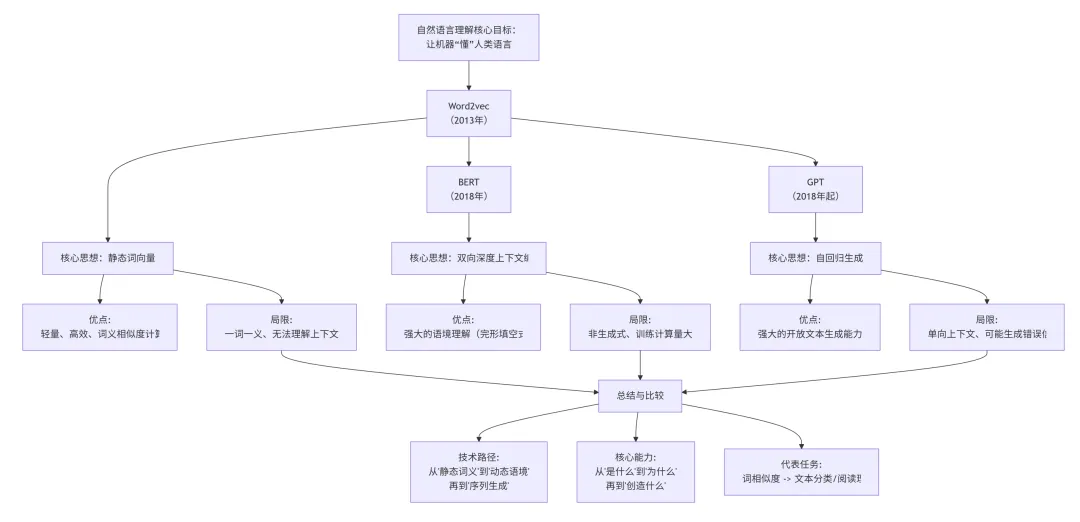
Word2vec、BERT 和 GPT 是自然语言处理领域中三个里程碑式的模型,分别代表了不同的技术范式。下图清晰地展示了它们之间的演进关系和核心区别:以下是它们的详细介绍:
1. Word2vec
核心思想:将单词转换为固定维度的稠密向量,使得语义相似的词在向量空间中的位置也相近。
技术:它是一个简单的浅层神经网络。通过两种训练方式(CBOW:用上下文预测中心词;Skip-gram:用中心词预测上下文)来学习词向量。
关键特点:
典型应用:词义相似度计算、作为更复杂模型(如文本分类、推荐系统)的输入特征。
简单比喻:给字典里的每个词分配一个唯一的、有意义的“身份证号”,意思相近的词,其“身份证号”也相似。
2. BERT
核心思想:通过在海量文本上进行预训练,学习深层的、双向的上下文词语表示。
技术:基于Transformer编码器。采用“掩码语言模型”进行预训练,即随机遮盖句子中的一些词,让模型根据双向的上下文来预测这些被遮盖的词。
关键特点:
动态上下文:同一个词在不同句子中会有不同的向量表示,解决了多义词问题。
强大特征提取:生成的向量能够很好地捕捉语法和语义信息。
微调驱动:预训练后的模型,只需在特定任务(如分类、问答)上用少量数据微调,即可取得极佳效果。
典型应用:文本分类、命名实体识别、智能问答、情感分析。
简单比喻:一个精通“完形填空”的语言大师。给它一个带空格的句子,它能根据整个句子的前后意思,最准确地填出空格里的词。
3. GPT
核心思想:基于海量数据,训练一个自回归的、生成式的预训练语言模型。
技术:基于Transformer解码器。采用“自回归语言模型”进行预训练,即根据上文逐词预测下一个词。
关键特点:
生成能力:专长为根据给定的上文,生成连贯、合乎逻辑的下文。
零样本/小样本学习:强大的GPT模型(如GPT-3/4)无需或仅需极少的任务示例,就能理解指令并执行新任务。
单向性:在生成每个词时,理论上只能看到它之前的词(虽然实际有优化),这与BERT的双向理解不同。
典型应用:文本创作、对话系统、代码生成、翻译、内容摘要等任何需要生成语言的任务。
简单比喻:一位极其博学的“接龙作家”。给它一个开头,它就能基于所学知识,将故事、对话或文章延续下去,并且文笔流畅。
核心对比摘要
| Word2vec | BERT | GPT |
|---|
| 出现年代 | | | |
| 核心架构 | | Transformer 编码器 | Transformer 解码器 |
| 上下文视角 | 无 | 双向 | 单向 |
| 核心训练任务 | | 掩码语言模型 | 自回归语言模型 |
| 主要优势 | | | 强大的开放式文本生成 |
| 主要输出 | | | 连贯的文本序列 |
| 典型任务 | | | |
演进关系
可以简单理解为一次“范式升级”:
Word2vec:解决了“词如何数字化表示”的问题,但表示是静态的。
BERT:解决了“句子上下文如何被理解和表示”的问题,实现了动态的深层语义编码。
GPT:解决了“如何基于所学知识和上下文生成人类语言”的问题,将NLP从“理解”推向“创造”。
如今,BERT及其变体是理解类任务的基石,而GPT系列及其追随者(如ChatGPT)已成为生成式AI的主流。它们共同构成了现代大语言模型的技术基础。