如果说AlexNet让机器学会了“看见”世界,那么自然语言处理则一直在寻找解读词语的法则。2013年初,题为《Efficient Estimation of Word Representations in Vector Space》的论文,为这个难题提供了一把优雅的钥匙——将每个词语映射为高维空间中的一个点。从此,“国王”减去“男人”加上“女人”约等于“女王”不再只是语言游戏,而是可计算的数学现实。Word2Vec的诞生,标志着自然语言处理从“符号处理”时代迈入了“语义理解”时代。
(一)背景:在稀疏高维里迷航
在 Word2Vec 点亮灯塔之前,自然语言处理(NLP)领域正受困于 “维度的诅咒”。想象一下,如果我们用传统的One-hot编码来表示英语词汇,每一个词都是一个长达数万甚至数百万维的向量,其中只有一位是 1,其余全为 0。在这个极度稀疏的高维空间里,算法就像是在一片漆黑的真空中航行,四周空无一物。
这种旧范式的困境主要体现在三个维度:
N-gram 的算力天花板:传统的统计语言模型依赖 N-gram(如 3-gram 或 5-gram),试图通过统计词序出现的概率来理解语言。然而,随着上下文长度 N 的增加,参数量呈指数级爆炸,数据稀疏问题让模型在面对从未见过的词组时束手无策。
语义相似性的缺席:在 One-hot 的世界里,“灯泡” 与 “灯光” 是两个完全正交的向量,它们的距离与 “灯泡” 和 “香蕉” 的距离没有任何区别。计算机无法理解词与词之间的内在联系,因为它们被作为孤立的原子符号(atomic units)处理。
计算规模的不对称:当时的神经网络语言模型(NNLM)虽然已经提出,但受限于非线性的隐藏层(Hidden Layer)带来的巨大计算开销,往往需要数周时间才能在几百万词的语料上训练。而互联网产生的海量文本(数十亿级别)正如潮水般涌来,现有的工具却像是一个拿汤勺舀海水的孩子,无力招架。
(二)核心贡献:连续向量让语言有了经纬
回到论文本身,其摘要和结论清晰地宣告了新范式的到来:
摘要核心:“我们提出了两种新颖的模型架构,用于从非常大的数据集中计算词的连续向量表示。这些表示的质量通过词语相似度任务进行衡量,我们将结果与此前基于不同类型的神经网络(NNLM、RNNLM)的最佳技术进行了比较。我们观察到,在更低的计算成本下,可以大幅提高准确性,只需不到一天的时间即可从 16 亿词的数据集中学习到高质量的词向量。……此外,我们还发现这些向量揭示了大量的句法和语义规律。”
结论核心:“我们的主要目标是介绍学习高质量分布式词向量的技术。我们展示了,使用非常简单的模型架构就可以实现这一点,只要模型在足够大的数据集上训练...我们的架构显著降低了计算成本,同时词向量质量反而提升。”
核心贡献可以概括为三点:
1、架构极简主义
提出了CBOW和Skip-gram两种去除了非线性隐藏层的架构。这种 “做减法” 的工程智慧,直接移除了神经网络中计算最昂贵的瓶颈。
2、工业级扩展性
"Less than a day... 1.6B words"。在那个算力昂贵的年代,这意味着词向量训练从 “实验室玩具” 变成了 “工业流水线产品”。
3、语义的可计算性
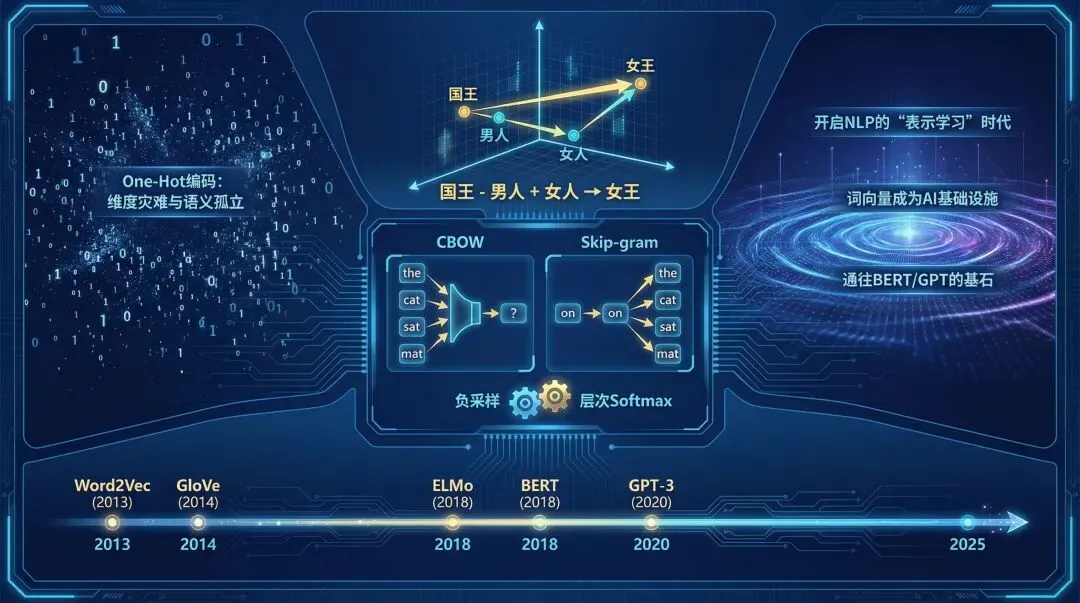
论文骄傲地宣称达到了 SOTA(State-of-the-art),不仅在句法上,更在语义相似度上取得了突破。这意味着机器开始 “读懂” 了语言的深层结构。著名的 King - Man + Woman ≈ Queen 就此诞生,证明了语义是可以被计算和推演的。
(三)怎么做到的:解剖“语义映射仪”的双引擎
Word2Vec 的成功,一半源于模型设计的精简,另一半源于训练技巧的打磨。核心是一个优雅的预测任务:用一个词预测它的上下文,或用上下文预测中间的词。
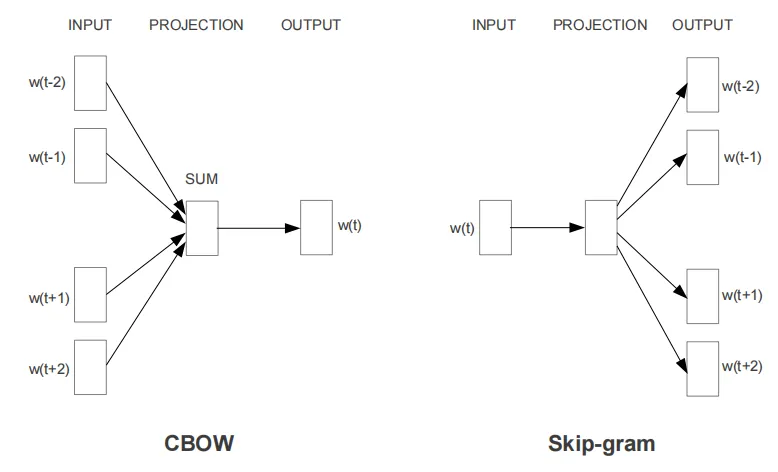
双引擎架构:CBOW与Skip-gram
Mikolov 抛弃了传统神经网络语言模型中昂贵的 “N-gram 输入 -> 投影层 -> 隐藏层 -> 输出层” 架构,直接移除了非线性的隐藏层。每个词由上下文定义。
CBOW (Continuous Bag-of-Words):“完形填空”,利用上下文词(Context)的向量平均值,来预测中心词(Target),适合常见词。给定一个词的周围上下文(如“猫 坐在 垫子 上”),模型需要猜出中间缺失的词(“?”)。这迫使模型学习到,某些词(“坐在”、“垫子”)经常共同指向某个中心词(“猫”)。
Skip-gram:“以点带面”,利用中心词(Target),来预测一定窗口内的上下文词(Context),对 生僻词 (Rare Words)效果更好。给定中心词“咖啡”,模型需要预测它可能出现的上下文(“喝”、“一杯”、“香浓的”)。Skip-gram通常能学到更精细的语义,尤其擅长处理稀有词。
这两种方法都不需要人工标注的数据——它们从原始文本的天然顺序中自动生成海量(中心词,上下文词)训练对。
关键技术:负采样与层次Softmax
如果在预测每个词时都要计算它在整个词表(比如 100 万个词)中的概率,计算量将是天文数字。Word2Vec 引入了两种极具工程智慧的近似方法:
通过改变问题的表述方式,而非单纯提升算力,来实现数量级的效率突破。
(四)意义与回响:语言的几何学
Word2Vec的影响迅速超越了自然语言处理领域,成为整个AI发展的思想催化剂。
技术范式层面,它完成了NLP从“特征工程”到“表示学习”的决定性转向。研究者不再需要手工设计词语特征,而是设计让模型自动学习更好表示的结构和目标。
产业应用层面,Word2Vec开源发布的预训练词向量,成为了全球NLP工程师的“标准零件”。几乎所有涉及文本的AI应用,都开始将词向量作为第一层处理。它极大地降低了NLP应用的门槛。
社区与科学层面,词向量空间呈现出的优美数学结构(语义线性、类比关系),为理解“神经网络学到了什么”提供了罕见的透明窗口。它让神秘的“表示”变得可视、可计算、可验证,增强了人们对深度学习可解释性的信心。
最深层的哲学启示在于两点:
简单性的胜利:Word2Vec的模型结构简单到令许多专家起初难以置信。最具影响力的突破,有时不是创造了最复杂的技术,而是找到了将复杂问题转化为简单可计算形式的优雅路径。
预测,而非标注:通过设计巧妙的自监督任务(预测上下文),模型从未标注的原始数据中学习到了丰富的语义知识。这为大模型时代的预训练范式(如BERT的掩码语言模型、GPT的下一个词预测)指明了方向。
(五)走向未来:从词嵌入到万物嵌入
Word2Vec 并非终点,而是一个伟大的起点。在它之后,GloVe 试图融合全局统计信息,FastText 进一步深入到了子词(sub-word)级别。然而,Word2Vec 最大的遗憾在于它的 “静态性”——在这个空间里,“苹果” 无论是水果还是手机,都只能拥有一个固定的坐标。
历史的车轮继续向前,ELMo 和 BERT 随后登场,引入了 “上下文相关” 的动态向量,将语言的坐标系折叠进了更深维度的 Transformer 空间。但无论大模型(LLM)如何进化,那个在 2013 年被点亮的信念依然未变:将人类的语言与世界的知识,压缩进数学的向量空间,是通往通用人工智能的必经之路。
在AI理解人类的漫长征途中,Word2Vec是让机器真正“读懂”文字的第一块基石。
— 全文完 —
【下期预告】(03)[2014]:GAN——对抗的智慧
2014 年,在酒吧的灵感时刻,将 “博弈论” 引入了深度学习。关于 “真与假”的史诗级对抗即将拉开序幕,是生成式 AI(Generative AI)真正的寒武纪大爆发前夜。