1. 主编按语
Why Now:在 OpenAI o1/o3 系列引发新一轮“Scaling Law”狂热的当下,市场普遍认为通过强化学习(RL)的扩展,AGI 将在 2-3 年内降临。然而,随着模型落地应用时的“手感”与宏大叙事出现偏差,我们需要冷静的冷思考。
Who & Conflict:本期内容源自一著名AI播客博主Dwarkesh基于 2025 年视角的复盘。核心冲突在于“短期极速派”与“技术现实主义”的对撞:前者认为通过 RLVR(基于可验证结果的强化学习)可以迅速通往 AGI;后者则尖锐指出,目前各大实验室疯狂进行“技能注入(Skill Baking)”的行为,恰恰暴露了模型缺乏核心的泛化与自学能力。
Value:这篇研报将为你祛魅。它指出了目前 AI 商业化受阻的真正原因并非“市场采用滞后”,而是“能力缺失”。同时,它提出了判断 AGI 真正的北极星指标——不是刷榜分数的提升,而是持续学习(Continual Learning)能力的突破。
2. 深度拆解·核心议题
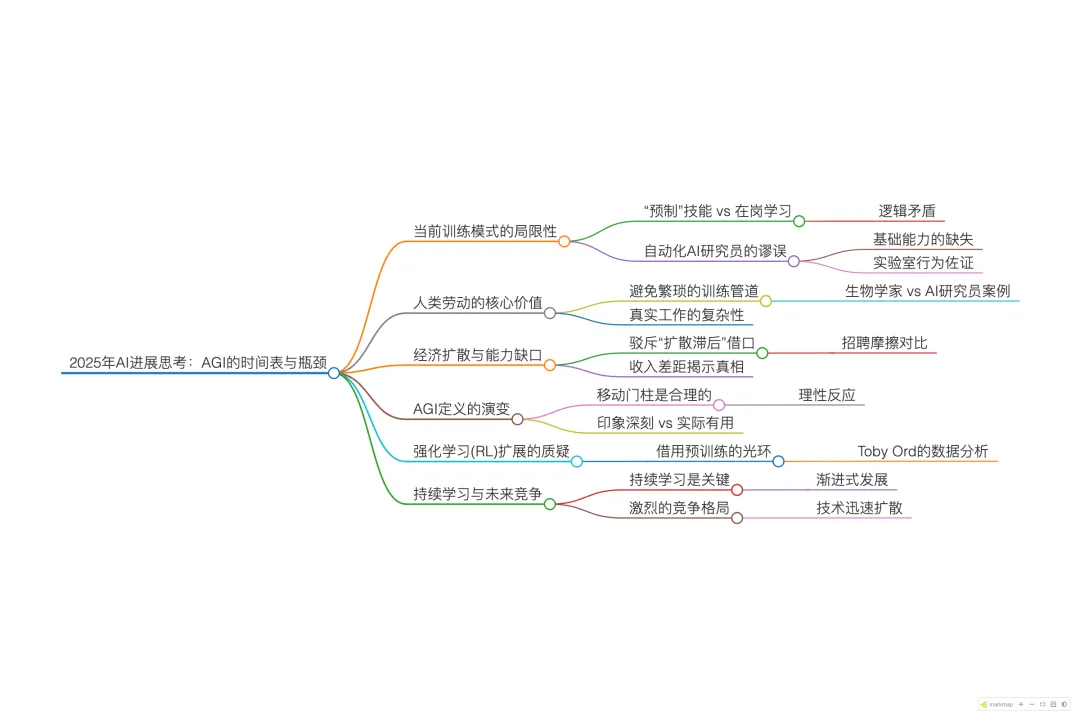
📌 议题 1:「技能注入」悖论——RL 扩展的虚假繁荣
- 核心论点各大实验室目前通过“Mid-training(中特训)”向模型硬塞 Excel、浏览器操作等技能,这并非通往 AGI 的捷径,而是模型缺乏类人学习能力的铁证。
- 逻辑推演
- 现状目前 AI 供应链中存在大量公司,专门构建 RL 环境来教模型如何浏览网页或构建金融模型。
- 悖论如果模型真的接近人类智能(AGI),它们应该像人类员工一样,通过“在岗学习(On-the-job learning)”掌握这些工具,而不需要预先“烘焙(Bake in)”所有可能用到的软件技能。
- 成本黑洞实验室正在花费数十亿美元聘请 PhD 和专家编写问题和推理步骤。这实际上是在用人力堆砌出的“伪智能”来掩盖模型无法自主归纳经验的缺陷。
- 类比这就像机器人领域,如果有了类人学习器,机器人本该通过算法解决通用操作;但因为没有,我们被迫去一千个不同的家庭收集数据,教它如何折叠衣服。
- Nuance(微妙之处)
- 反方观点认为,这种笨拙的 RL 训练是为了培养出一个“超级 AI 研究员”(自动化 Ilya),然后由它去解决更难的学习问题。
- 但作者反驳:一个连基本“儿童级”自学能力都没有的模型,如何能解决人类研究了一个世纪的 AGI 算法难题?这不符合逻辑。
- 精彩原话
“人类不需要经历一个特殊的训练阶段,去预演他们未来可能用到的每一个软件。如果模型真有那么聪明,这种预烘焙就是毫无意义的。”
📌 议题 2:经济扩散的谎言——“采用滞后”是能力不足的遮羞布
- 核心论点AI 尚未在大规模商业中产生万亿级收入,原因不是“技术扩散慢”,而是“模型能力不够”。
- 逻辑推演
- 反驳“扩散滞后论”高技能移民(人类)进入新经济体时,几乎可以立即整合并创造价值。如果 AI 真的是“服务器上的高智商人类”,它们的整合速度应该比人类更快(几分钟读完公司所有 Slack 和 Drive)。
- 柠檬市场(Lemon Market)消失招聘人类存在信息不对称(不知道谁是好员工),但部署经过验证的 AGI 模型不存在这个问题。因此,AI 的扩散摩擦力本应极低。
- 数据证伪全球知识工作者的年薪总和是数十万亿美元。如果模型能力达标,企业会毫不犹豫地花费数万亿购买 Token。然而,目前实验室的收入与此相差 4 个数量级。
- 结论这种巨大的收入鸿沟,只能说明模型目前还无法替代真正的知识工作。
- 精彩原话
“如果这些模型真的是‘服务器上的人类’,它们的扩散速度会快得惊人……‘技术扩散需要时间’只是人们用来掩盖模型缺乏核心经济价值这一事实的托词(Cope)。”
📌 议题 3:终局推演——从“预训练红利”到“持续学习”的苦旅
- 核心论点真正的 AGI 爆发(Intelligence Explosion)不会来自单纯的算力堆叠,而是来自解决“持续学习(Continual Learning)”,这将是一个长达 10 年的渐进过程。
- 逻辑推演
- 偷换概念人们试图将“预训练 Scaling Law”的确定性(像物理定律一样稳固),“洗白(Launder)”嫁接到 RL 扩展上。但 RL 的扩展并没有公开、拟合良好的趋势线。Toby Ord 的研究甚至暗示,RL 需要 100 万倍 的算力增长才能获得类似 GPT 级的提升。
- 未来形态未来的 AGI 形态是无数个 Agent 被派往各行各业,在工作中学习,然后将经验“回传”给蜂巢思维(Hive Mind)进行批量蒸馏。
- 时间表解决“持续学习”不是一蹴而就的(像 GPT-3 并没有彻底解决 In-context learning 一样)。这需要 5-10 年的迭代。
- 竞争格局因为没有“一夜之间”的突破,先发优势会被人才流动和逆向工程抹平。各大实验室将继续轮流坐庄,不会出现单一寡头垄断。
- 精彩原话
“人们正在试图‘洗白’预训练扩展的声望,用它来为 RLVR 的看涨预测背书……但当我们试图从稀缺的数据点中拼凑真相时,结果相当悲观。”
3. 思维模型与框架
1. The "Schlep" Filter(繁琐过滤器)
- 定义Schlep (Yiddish) 指繁琐、令人不快但必须做的工作。人类劳动的核心价值,在于处理那些无法被标准化、需要实时判断的“非标准化繁琐事务”。
- 应用场景当你评估一个 AI 产品是否能替代人工时,问自己:这个任务是否需要为每个细分场景建立单独的训练循环(High Schlep)?如果是,目前的 AI 很难替代;如果 AI 能通过通用逻辑解决,才是真正的 AGI。
2. Prestige Laundering(声望洗白)
- 定义利用一个已验证趋势(如 Pre-training Scaling)的权威性,去论证另一个尚未验证、机制完全不同的趋势(如 RL Scaling/推理侧扩展),从而制造确定性的假象。
- 应用场景投资人在看 AI 项目 BP 时,需警惕创始人是否用 GPT-4 的成功路径,来强行推导 Agent 或机器人的必然成功。
3. Hive Mind Distillation(蜂巢思维蒸馏)
- 定义一种未来的 AI 学习架构。边缘端的 Agent 在具体任务中获取“隐性知识”,然后定期同步回中央大模型,中央模型通过“批量蒸馏”吸收经验并更新,再分发给所有 Agent。
- 应用场景判断 AI 应用公司的护城河——不仅看模型多强,要看是否建立了“端侧执行 -> 经验回流 -> 中央模型迭代”的闭环。
4. Decision Signals(决策信号·高价值判断)
🔴 看空/风险:短期 AGI 泡沫
🟢 看多/机会:持续学习(Continual Learning)基础设施
💡 非共识:AI 招聘的“反柠檬市场”效应