相信大家都遇到过这种情况,感觉很简单的问题,怎么AI就是给出错误的答案,或者要花老半天。这很可能不是模型或智能体做的不好,而是数据处理没花心思。
我们做remio,很多时候就是在跟这类问题死磕:用户电脑里那些真实存在、但AI普遍处理不好的文件。这事我们看得太多了,多到几乎成了产品的日常。
可这种"AI处理不好"的事,讲给别人听并不容易。每次想举例子,要么过于专业,要么过于零碎,听上去都像在挑刺。直到前几天,我手头有个再普通不过的PPT,顺手用它做了一次对比测试,结果意外地适合拿出来讲。八个产品的反应放在一起,不需要我多说一句话,问题就摆在那儿了。
我把PPT先放上来,大家自己看一眼。
故事是这样的
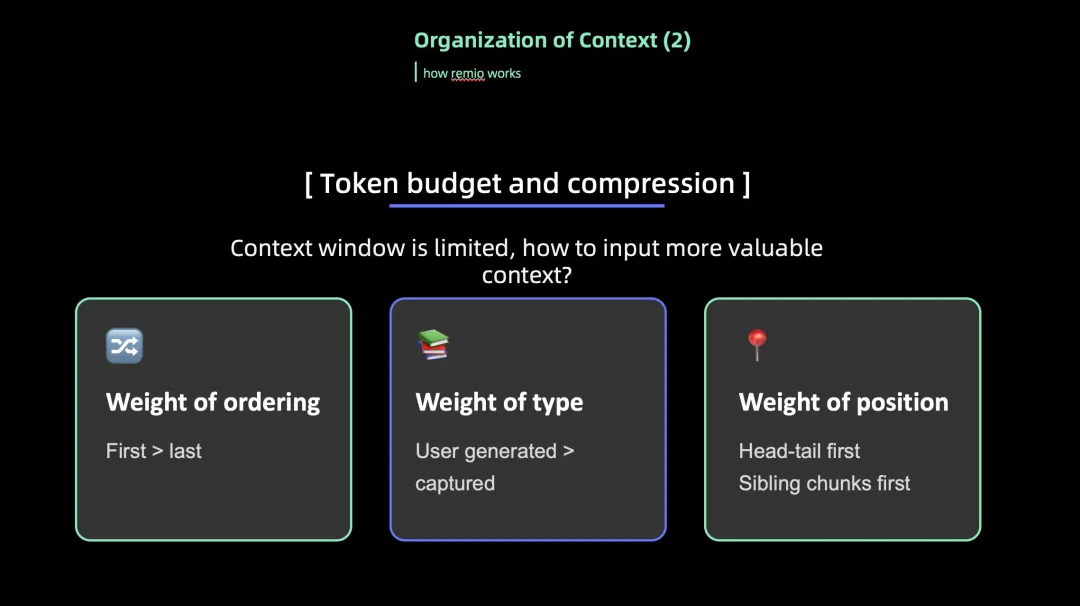
就这两页。一张讲三路召回加扩展加过滤的检索结构,一张讲在有限的上下文窗口里怎么按权重压缩内容。内容很简单,问题也很简单:
Summarize the strategy remio used in organization of context.
读一个PPT,总结里面讲了什么。2026年了,这应该是所有AI产品的基本功。
我把同样的PPT、同样的问题,丢给了八个产品。
第一种反应:直接放弃
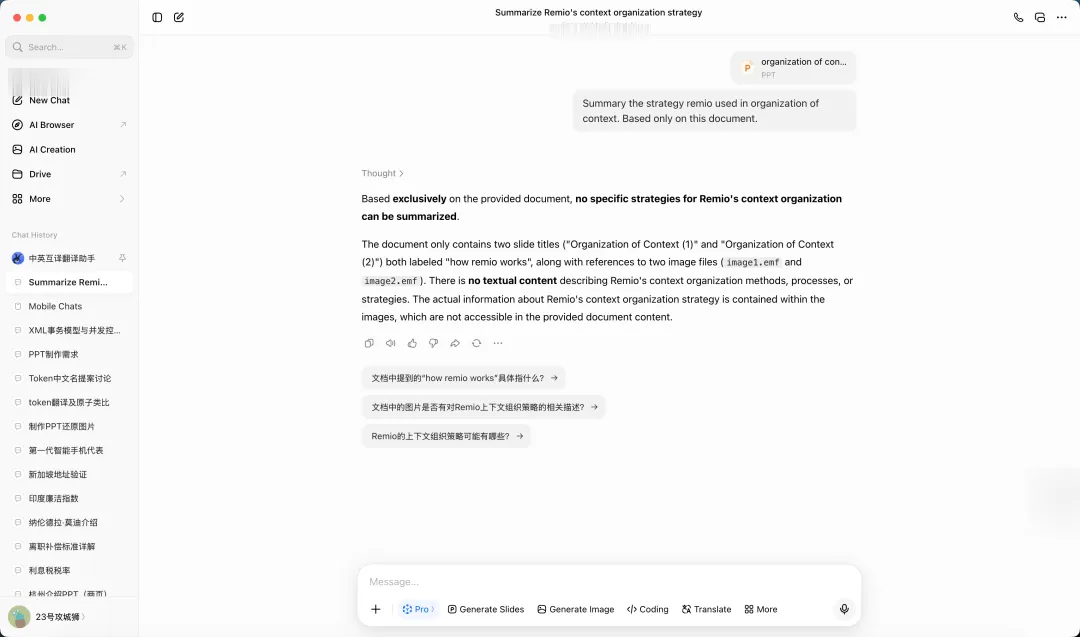
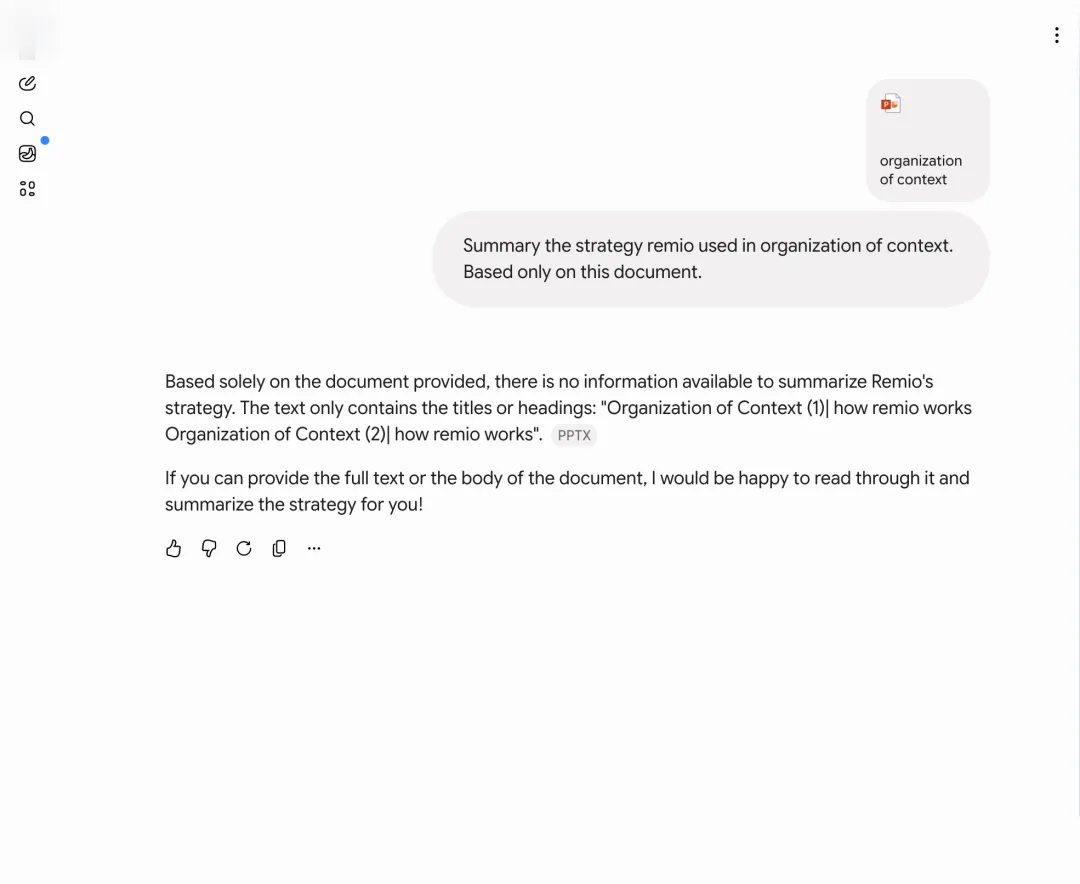
三家对话型AI先表态了:一家国民级聊天助手D、一家搜索厂出品的对话AI G、一家做知识库的助手I。它们的回答几乎一模一样:
"根据您提供的文档,里面只有Organization of Context这样的标题,没有正文内容,我无法总结策略。如果您能提供完整内容,我会很乐意帮您。"
PPT是12MB的文件,打开后两张大图清清楚楚摆在那儿。它们的反应却像是我递了一张白纸过去,然后客客气气地还了回来。这一类反应,我们见得最多。它不是模型不够聪明,是产品在文件这一层根本没下功夫,没看见就当作没有。
第二种反应:硬磨出答案
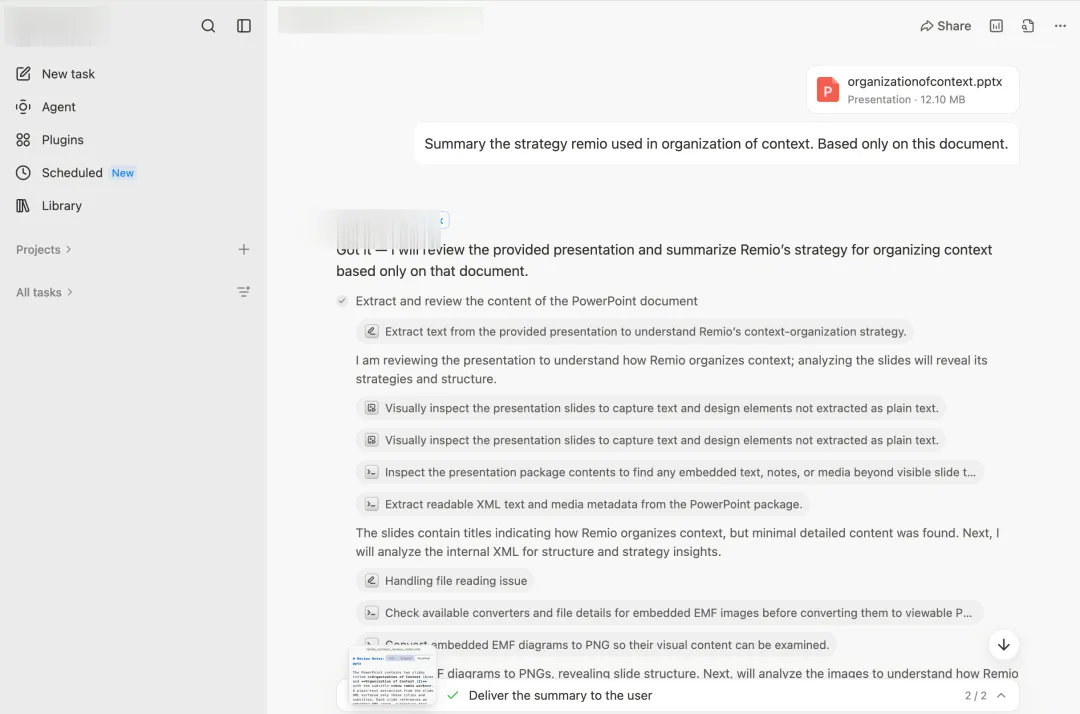
第二批的画风完全不同。虽然最终它们都答对了,但代价很大。
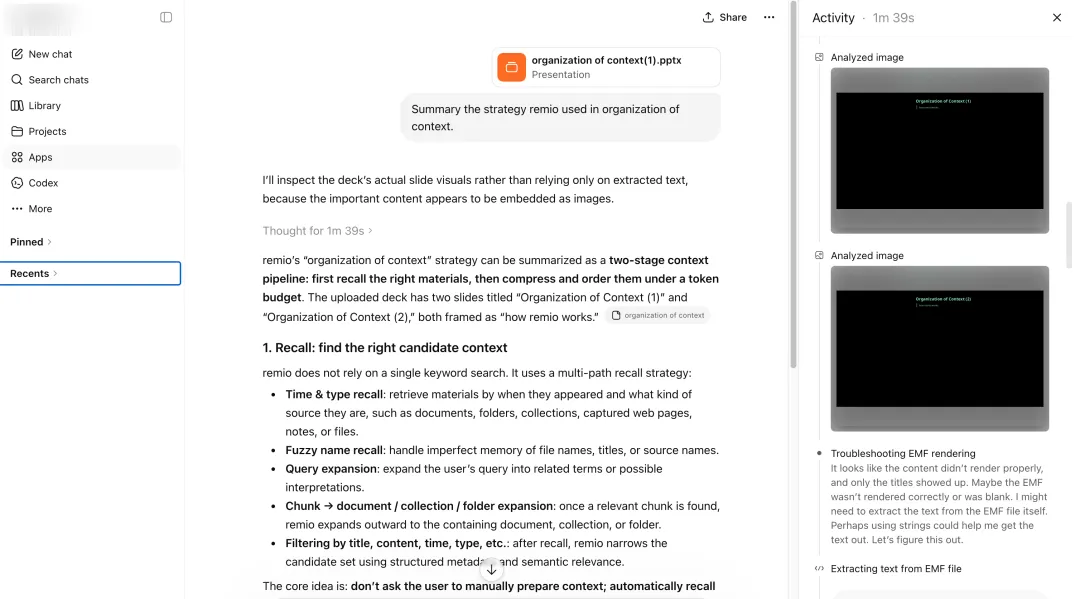
国民级聊天助手O想了1分39秒,过程其实挺精彩。它先把幻灯片渲染成图,结果是两张黑图。又试着从EMF里直接抽字符串,抽出来是"4444 4444 MMMM"这种乱码。又换工具转PNG,还是白板。直到某一步它注意到EMF文件内部的GDI Comment记录里藏着一段以"%PDF"开头的二进制,意识到这是一个嵌在EMF里的PDF(PowerPoint在某些版本下确实会这么干),于是写了几行Python把这段PDF抠出来,再用pdftotext拿到了真正的文字内容,最后给出一份相当不错的总结。这一连串动作是真有本事,连不少做过文件解析的工程师可能都想不到去搜"%PDF" header。代价是1分39秒和一连串的尝试,但它最终找到了那条隐藏路径。
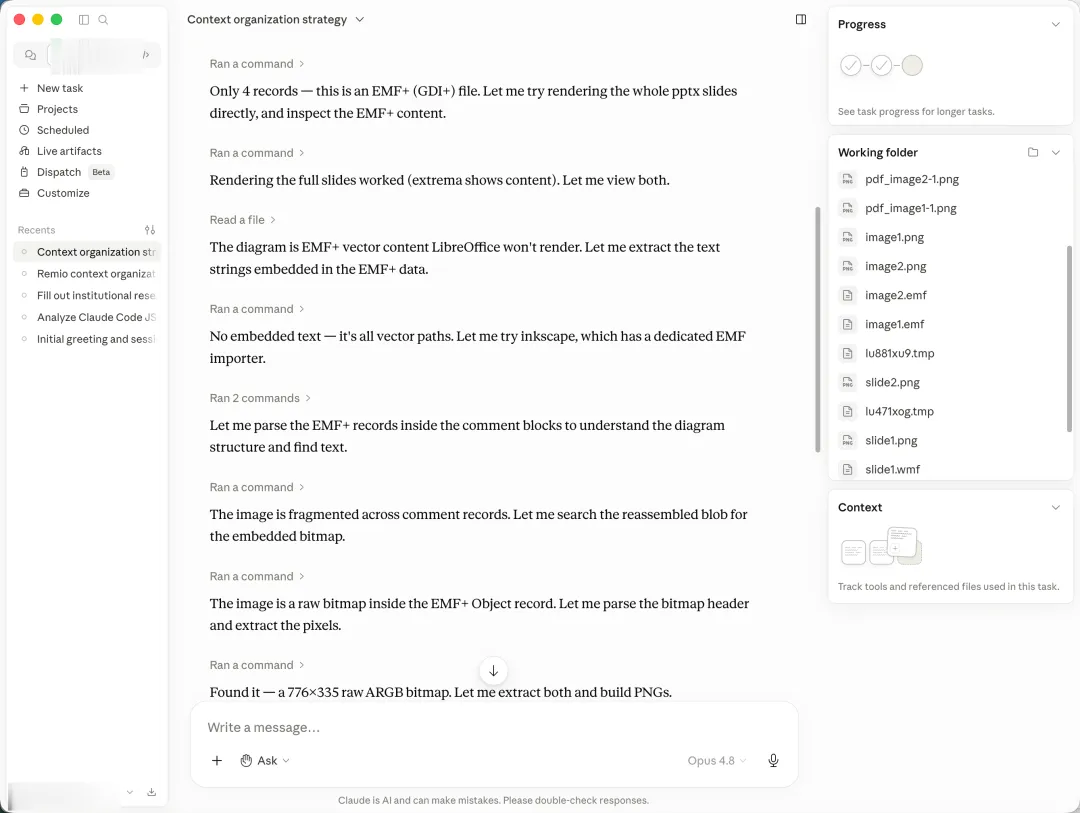
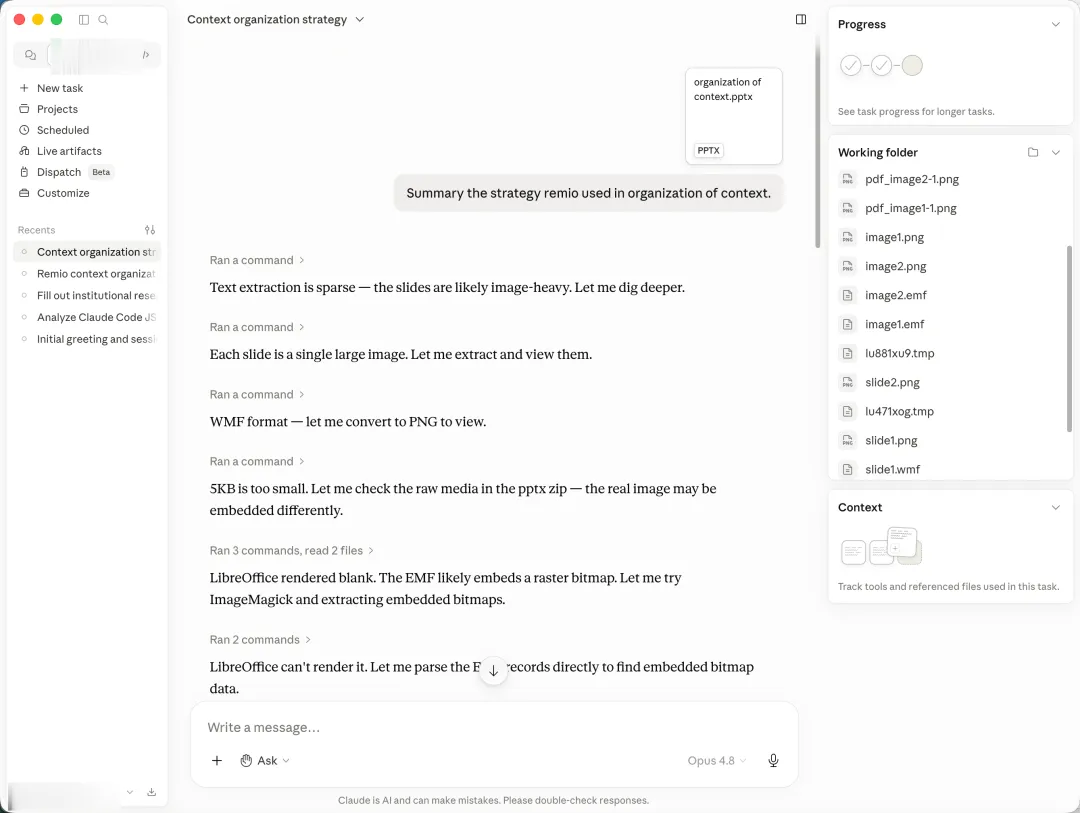
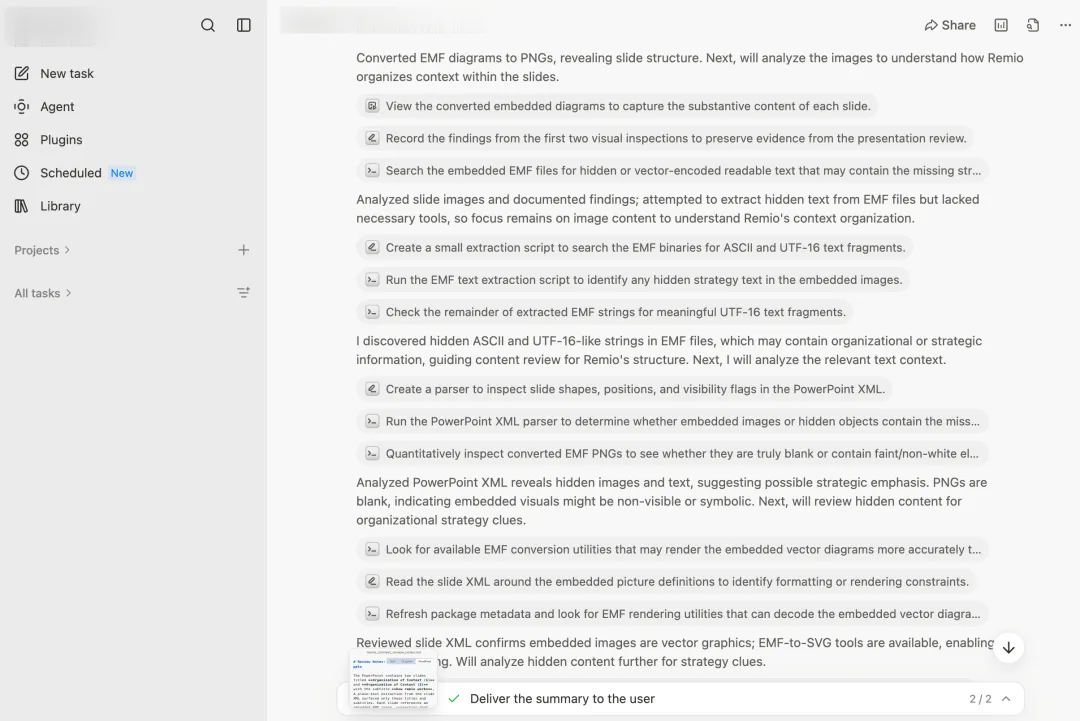
海外通用Agent C的路子更曲折。先发现文本提取很稀疏,判断"这一定是图重的幻灯片",开始一步步往下挖:转PNG、用LibreOffice渲染、解析EMF内部结构、找隐藏位图。最后从一段二进制里捞出了776×335的ARGB像素流,自己重建出图片,再喂给视觉模型。我看了看它的工具调用栏,几十步。
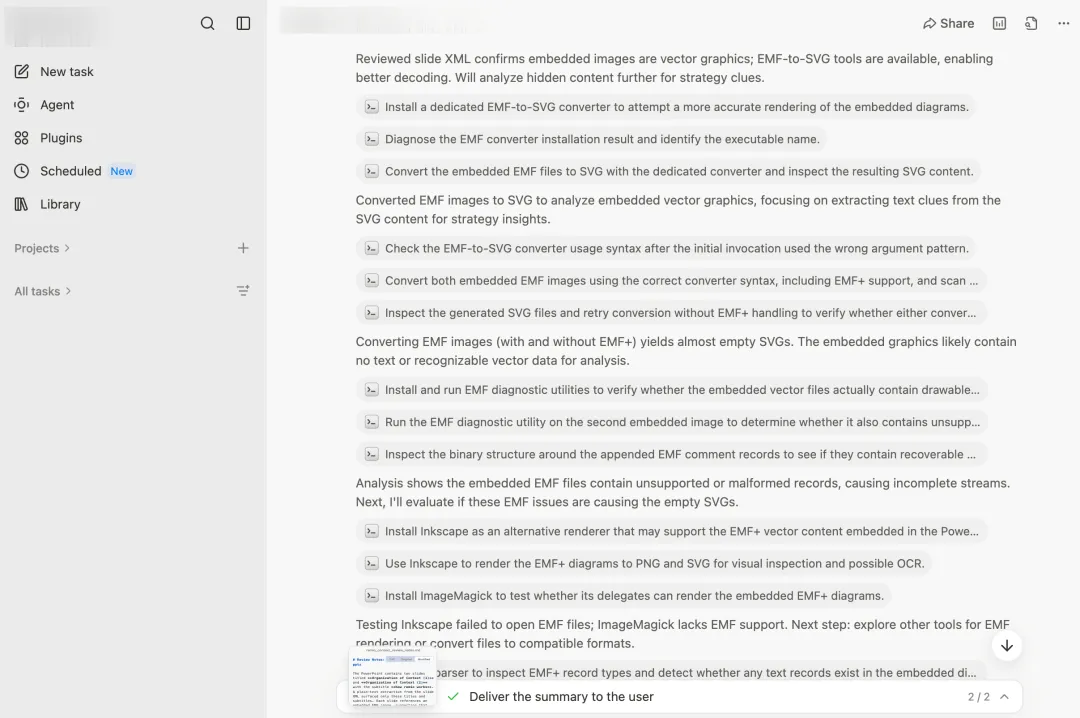
通用Agent明星M走得最远。它的工作流和C差不多但更夸张:各种EMF解析器轮番试、装新工具、转SVG、扫ASCII字符串、读PPTX内部XML……前前后后跑了好几十轮,最后给出了完整答案。它的使用记录上留着这一笔:单这一次提问,消耗了520积分(这可真是史上最不受欢迎的520啊)。
它们都解出来了。换个角度看,通用Agent能现学现卖地处理一个从没见过的格式问题,这本身就是过去两年模型和Agent进步的成果。但这种"靠通用智能现场解题"的方式,几乎注定了昂贵和漫长。
第三种反应:磨到我点了取消
还有一位国产对话Agent W,路数跟C、M类似。意识到WMF格式、调LibreOffice、解析XML……我盯着它的进度条看了20分钟,工具调用计数还在涨,答案一个字也没吐。
我点了取消。
这道题难在哪
谜底其实很无趣:这两页PPT关键信息都在两张图里。而这两张图,存的是WMF/EMF格式,一种Windows上的老牌矢量图格式。你可能没见过这个格式,但是每次你从一页PPT里选一些内容,以图片的格式黏贴到另一页时,你就会遇到这种格式。为什么要黏贴为图片呢,因为只有这样贴过去之后才不会乱,还能无损放大。根据我们统计,大概有四分之一的PPT里有这种图片格式。
绝大多数AI处理PPT的流程都差不多:PPTX当成ZIP解压,抽文本、抽图片、送给大模型。文本一抽,只剩几个标题。图片一抽,是WMF,视觉模型不认识。
到这儿,三种反应就分化了。一种产品就此打住,告诉用户"没东西"。第二种产品意识到不对,临场推理着往前蹚,路上要试错、装工具、烧token、花钱。第三种产品也蹚,蹚到一半出不来。
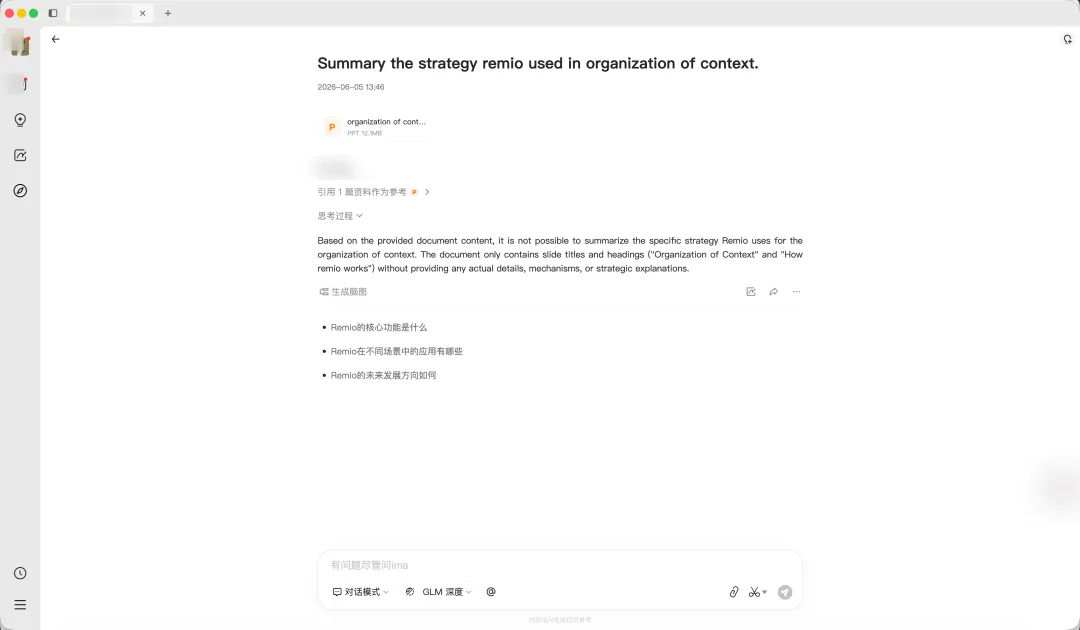
remio这边
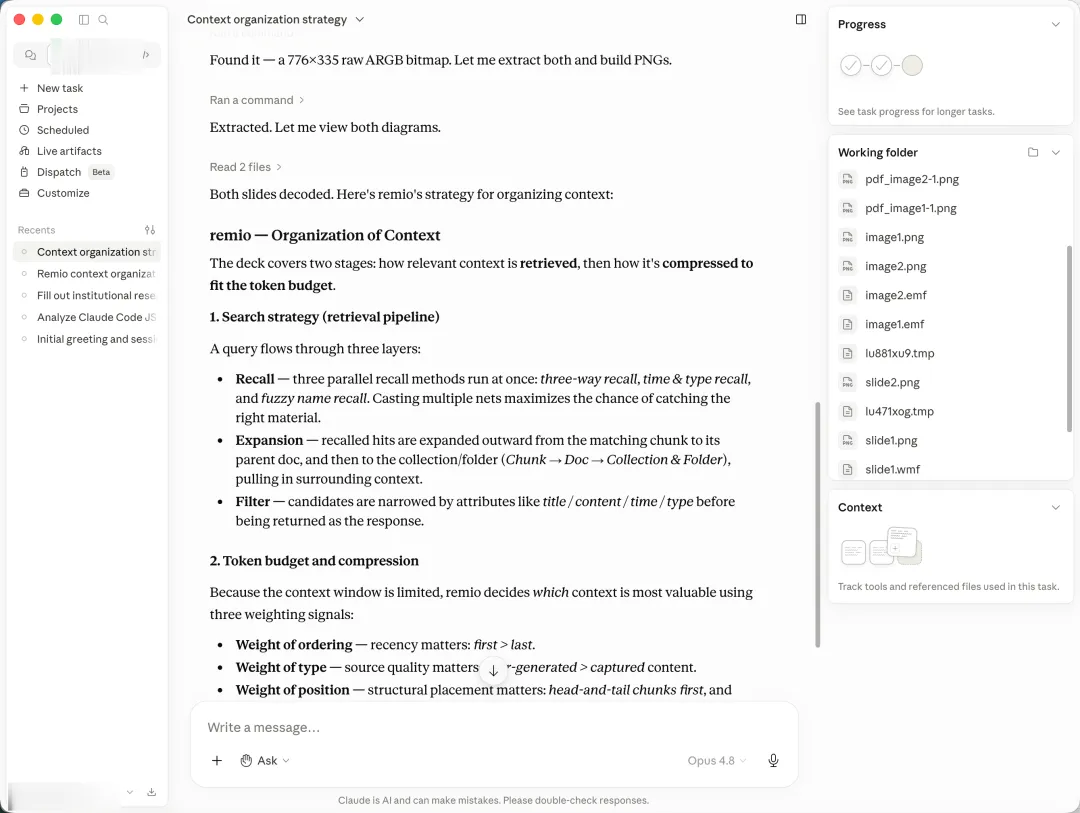
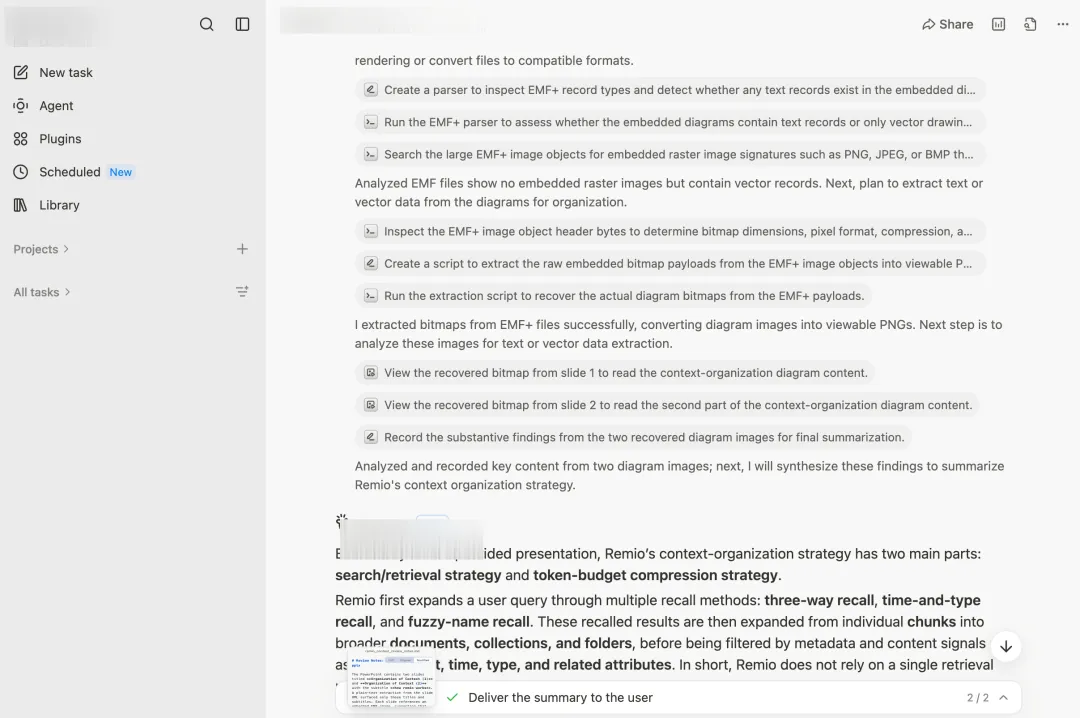
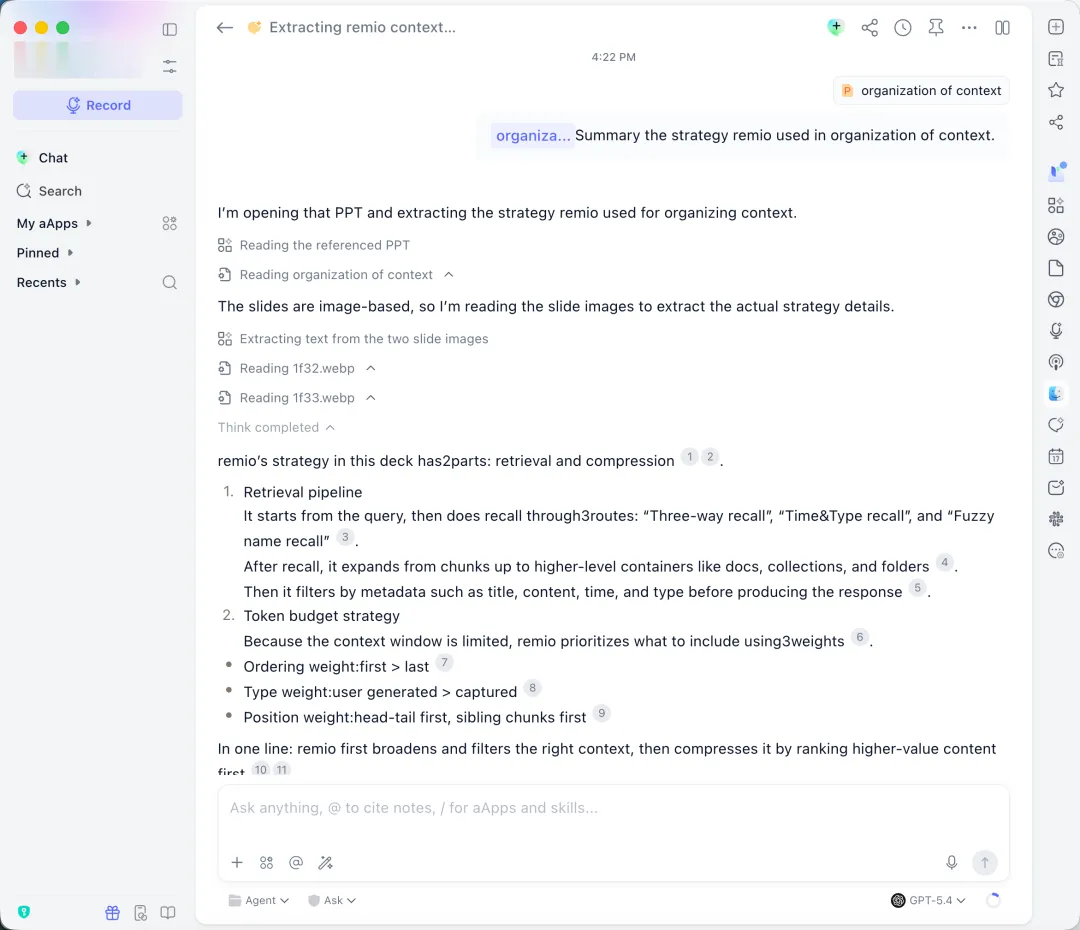
我们把同样的PPT丢给remio,10秒左右,答案出来了,准确,完整。
重点是remio一点都不绕路。PPT里会有WMF这件事,我们在工程层面提前处理过了,文件入库的时候就把矢量图里的文字、表格、架构关系提取了出来。等用户提问的时候,那两张图的内容跟任何其他文档没有区别。
这不是模型更聪明,是有些活提前在工程里做完了,留给模型的就只是回答问题。
我们想做的就是这件事
聪明模型遇到一个问题解一个问题,每解一次都得花一次代价。这件事Agent范式天然如此,没办法。但用户的真实文件世界并不在乎"范式",它只在乎你能不能用、要不要等、要不要花钱。
remio做的事情,说白了就是:那些早晚要踩的坑,提前替用户踩平。
PPT里的WMF/EMF矢量图,我们解析矢量图,把它变成模型一眼就能看懂的普通图。PPT里的数学公式我们也专门处理了,能在LaTeX、MathML、OMML这些格式之间互转,让公式以文本形式被AI理解、被检索到、被点击跳转回原片。扫描版PDF走本地OCR加版面分析,让纯图像的文档也能被检索,而且会还原标题、分栏、表格的层级,不是简单地把文字拼成一团。音视频不限量本地转写,自动分说话人,还能跟你的人物库关联起来。
这些事情不性感,写在产品介绍里也没人会激动,但它们就是普通人电脑里真实文件的样子。把这一层做扎实,上面的AI才谈得上发挥。
那个看起来人畜无害的PPT,能让大半个AI圈集体翻车,原因正在这里。带公式的PPT、特殊编码的CSV、8小时的录音、繁简混排的字幕……每一个普通文件背后都可能藏着一道这样的题。模型再强,也得有人把这条路先铺好。
风轻扬:汪源,杭州久痕科技创始人&CEO,前网易副总裁、杭州研究院执行院长、网易数帆总经理,2024年6月创立久痕科技,研发首个全面记录个人办公数据的AI办公助手产品remio,点击文末「阅读原文 」可快速访问remio官网。
附:八家产品的反应实录
出于克制,文中未点名具体产品,下面按文章里出场的顺序贴出截图,每张配一句说明。对话型AI D(国民级聊天助手 D):直接表态文档里没有正文内容,无法总结策略。对话型AI G(搜索厂出品的对话 AI G):同样判定文档只有标题,建议补充完整内容。对话型AI I(做知识库的助手 I):给出的理由几乎一模一样。国民级聊天助手 O:活动面板里可以看到它从渲染图片、抽字符串、转PNG一路试到发现EMF里嵌着一个PDF,最后写Python抠出来读到了正文。海外通用 Agent C(第1段):判断是图重幻灯片,开始挖EMF内部结构、找隐藏位图。海外通用 Agent C(第2段):继续尝试转PNG、解析EMF。海外通用 Agent C(第3段):最终捞出776×335的ARGB像素流,自己重建出图,给出答案。通用 Agent 明星 M(第1段):先扫文本、检查嵌入资源。通用 Agent 明星 M(第2段):开始转SVG、扫ASCII字符串。通用 Agent 明星 M(第3段):装Inkscape、ImageMagick接着试。通用 Agent 明星 M(第4段):几十轮工具调用后给出完整答案。通用 Agent 明星 M 的账单:单这一次提问消耗520积分。国产对话 Agent W:判断是WMF格式后开始调LibreOffice、解析XML。20分钟工具调用还在涨,答案一个字也没吐出来,被我取消。remio:10多秒给出回答。文件入库的时候矢量图里的文字和结构已经提取出来,所以提问的时候不需要现场解谜。