日常使用表格,拆分文本是很常见的事。毕竟它不是数据库,限制不严格,内容也就五花八门。为了便于分析统计,不得不进行拆分。
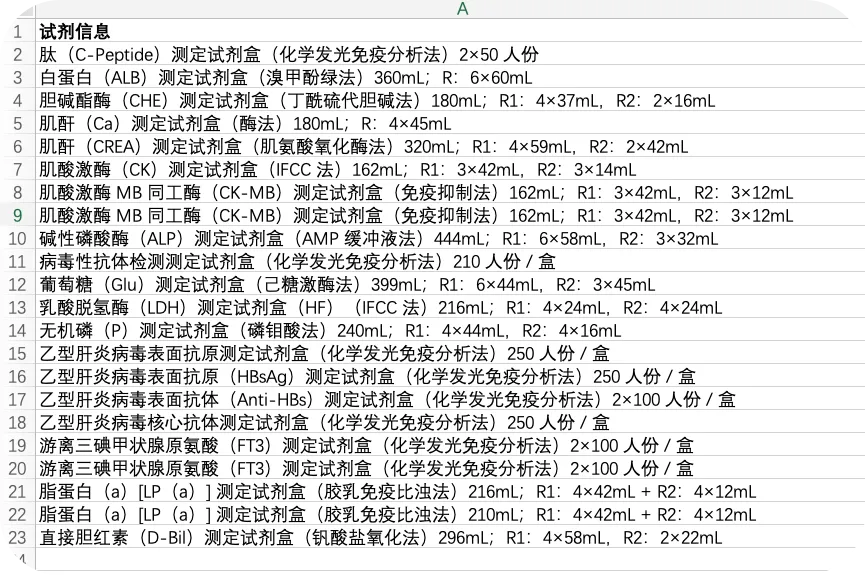
下面是一份试剂信息表,是一份不合格的表格。所有的品名和规格都填在一个单元格中。
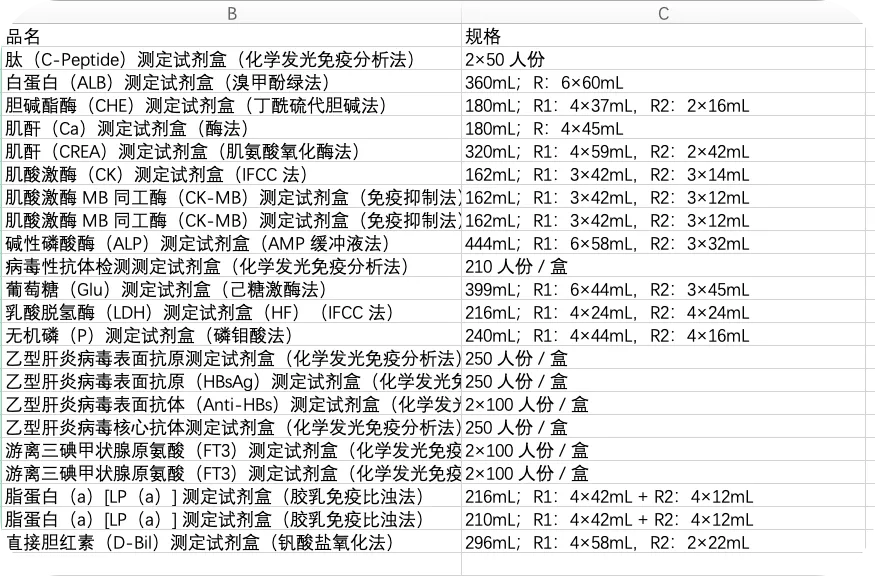
这样的表格,别说统计分析,光看着就够烧脑。所以需要进行拆分,拆分效果如下。
拆分思路
虽然原始信息看着非常混乱,但是仔细分析一下,依然有规律可寻。规格在最后一个“)”后面。只要把这个符号前后内容拆分出来即可。
用mid/textsplit/textbefore/textafter也不是不行,只是这里面有多个“)”,处理起来会比较复杂。而正则表达式则在处理这种情况有天然优势。所以用正则公式可以轻松拆分。
公式
=REGEXEXTRACT(A2,"(.*\))(.*)",2)
公式解析
A2:需要拆分的源文本单元格。
"(.*\))(.*)":这是正则表达式。• 第一个括号 (.*\)):利用 *的贪婪匹配特性,从头一直抓取直到遇到最后一个中文右括号 “)”。抓取到了“肽(C-Peptide)测定试剂盒(化学发光免疫分析法)”。
注意
(.*\))这里有个"\",它是转义符,因为括号在正则表达式中有特定用途,所以如果需要匹配的内容是括号,则需要用"\"将括号变成括号字符本身,而不是特定用途的括号。这个文本中用的是全角括号,因此,这里不加"\"也是可以的。如果是半角括号,那么就一定要加上转义符。
• 第二个括号 (.*):抓取括号后的所有剩余字符。抓取到了剩下的“2×50 人份”。
2:这是实现拆分的核心参数!在 Excel 中,参数 2代表“以数组的形式返回第一个匹配项中的捕获组”。它会把正则表达式中用 ()括起来的每一部分,分别输出到相邻的列中。
假如,我只想取头尾文本,中间的抛弃。例如“肽(C-Peptide)测定试剂盒(化学发光免疫分析法)2×50 人份”中,取“肽(C-Peptide)”和“2×50 人份”,那么就需要修改一下公式。
公式
=REGEXEXTRACT(A2,"(.*?\)).*\)(.*)",2)
公式解析
这个公式的核心在于三段式的设计,把不需要的部分“吃掉”: • 这里的 .*?是非贪婪匹配。它从字符串开头往后找,一碰到第一个右括号 )就立刻停下并捕获。 • 提取结果:肽(C-Peptide) • 这一段没有加圆括号,所以它负责匹配文本,但 Excel 不会把它输出出来。 • 这里的 .*是贪婪匹配。它紧接着第一段的结果往后找,会一直抓取到整个字符串中的最后一个右括号 )为止。• 吃掉并丢弃的内容:测定试剂盒(化学发光免疫分析法) • 既然上一段已经把进度条推到了最后一个 ),这最后的 (.*)只需要顺理成章地把剩下的所有字符全都捕获即可。 • 提取结果:2×50 人份(这就完美实现了“返回最后一个 )后面的内容”)。提示
在Excel365中有数组溢出功能,因此只用这个公式,就可以将原文本拆分成两个列。没有数组溢出功能,则没有这个效果。
- 数组溢出:从 Excel 365(2020)/Excel 2021开始支持。
- 正则函数:从 Excel 365(2406+,2024)/Excel 2024开始支持。
如果你觉得这篇文章对你有帮助的话,不妨关注一下公众号👇
也可以分享给你的朋友。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
