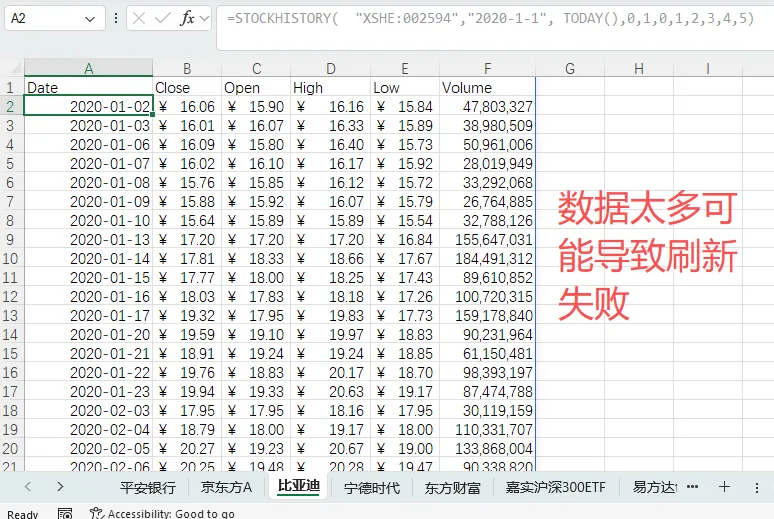
当你用Excel里的STOCKHISTORY公式,跑完了2020年至今的日线级别交易数据后,老板提出了一个极具远见的问题:“每天就新增1天数据,却要刷新整个文件,速度会不会很慢?”
老板不是BI出身,却一下戳中了Excel作为数据源的天生短板:非数据库文件天生只能全量刷新——哪怕你只新增了0.01%的数据,它也要把100%的数据全部重新读取、计算一遍,这对Power BI来说,就是巨大的性能浪费。
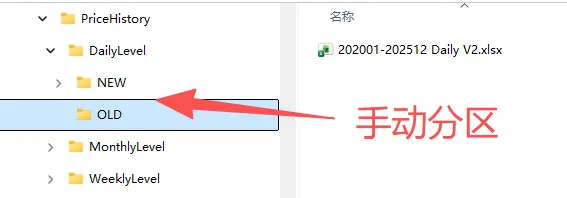
核心解法:手动分区,新旧数据分离
最直接的优化方式,就是人为把数据拆成两个独立的「分区」:
- 旧数据分区(历史快照)把2020年-2025年的所有日线数据,单独存为一个文件。这些数据已经是“过去式”,不会再变化,只需要刷新一次,之后就可以永久固定,完全不用再参与日常刷新。
- 新数据分区(增量更新)把2026年至今的数据单独存放,每天收盘后,只需要刷新这个分区的数据,再和旧数据合并即可。
为什么用「年分区」,而不是更细的月/日分区?
你也可以按月、按季度拆分数据,但从性能和维护成本的平衡来看,按年分区是最优解:
- 对日线数据来说,一年的交易日大约250天,数据量适中,单次刷新速度极快。
- 不用频繁创建新文件,也不会因为分区过多,导致后续合并和管理的复杂度飙升。
- 未来每年年底,只需要把当年的数据归档到旧分区即可,一次操作,管一整年。
不同时间维度的刷新策略,怎么设计?
不是所有数据都需要分区,我们可以根据数据量灵活处理:
- 日线数据:必须用「新旧分区」,用最少的刷新量,换取最高的性能。
- 周线/月线数据:数据量本身就不大,即使全量刷新,耗时也很短,直接全量刷新即可,不用额外分区增加维护成本。
最终效果
经过这样的手动分区改造后,Power BI每次刷新时,只需要读取当年的增量数据,再和固定的历史数据合并即可,刷新速度会有质的飞跃:✅ 刷新时间从几分钟缩短到几十秒✅ 减少了SharePoint文件同步和Power Query读取的出错概率✅ 后续分析、可视化时,模型的响应速度也会明显提升
一句话总结:把历史数据“归档冻结”,只让新数据参与刷新,是解决Excel全量刷新痛点、提升Power BI性能的最高性价比方案。
声明:以上内容纯属低代码教学知识分享,不作为任何股票ETF投资建议。