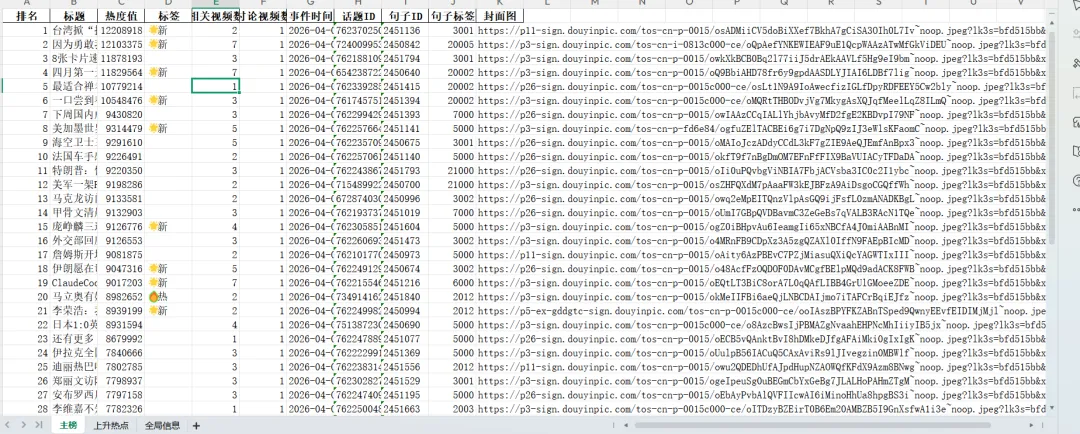
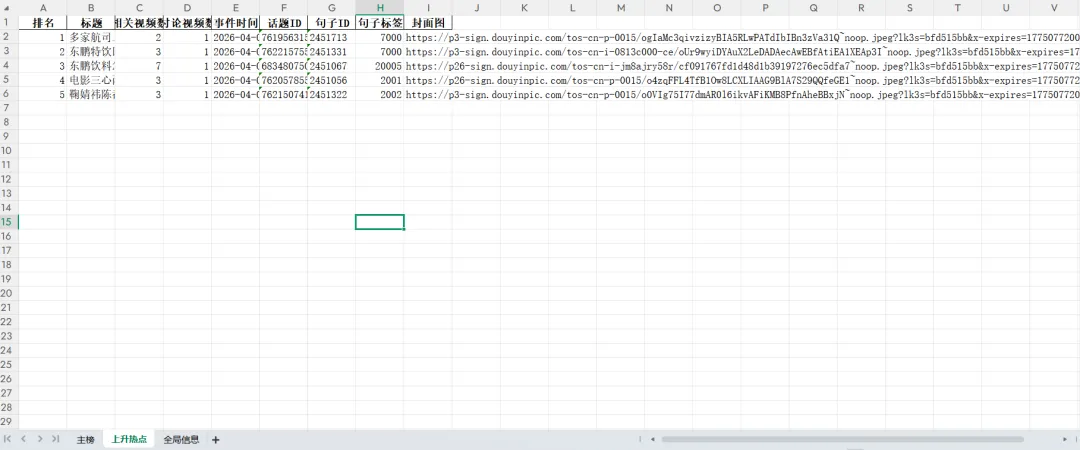
import requestsimport timeimport pandas as pdfrom datetime import datetimeclass DouyinHotlist: def __init__(self, cookie: str, max_retries: int = 3, save_excel: bool = True): self.cookie = cookie self.max_retries = max_retries self.save_excel = save_excel self.data = None def fetch(self) -> dict: base_url = "https://www-hj.douyin.com/aweme/v1/web/hot/search/list/" # 以下参数为固定模拟数据,无需修改 params = { "device_platform": "webapp", "aid": "6383", "detail_list": "1", "source": "6", # ... 其他固定参数 } headers = { "User-Agent": "Mozilla/5.0 ...", "Cookie": self.cookie, "Referer": "https://www.douyin.com/", # ... 其他固定请求头 } for attempt in range(self.max_retries): try: response = requests.get(base_url, params=params, headers=headers, timeout=15) response.raise_for_status() data = response.json() if data.get("data") and data["data"].get("word_list"): self.data = data if self.save_excel: self.save_to_excel() # 自动保存Excel return data else: print(f"警告: 接口返回数据格式异常,尝试重试... (第{attempt+1}次)") time.sleep(2) except Exception as e: print(f"请求失败: {e},正在重试... (第{attempt+1}次)") time.sleep(3) return None def save_to_excel(self, filename_prefix: str = "douyin_hotlist"): """ 将当前存储的热榜数据保存到 Excel 文件 :param filename_prefix: 保存的文件名前缀,默认 "douyin_hotlist" """ if not self.data: print("无数据可保存") return active_time = self.data['data'].get('active_time', '未知') timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") filename = f"{filename_prefix}_{timestamp}.xlsx" with pd.ExcelWriter(filename, engine='openpyxl') as writer: # 1. 主榜 word_list = self.data['data'].get('word_list', []) if word_list: main_df = [] for idx, item in enumerate(word_list, 1): row = { '排名': idx, '标题': item.get('word', ''), '热度值': item.get('hot_value', 0), '浏览量': item.get('view_count', 0), '标签': self.get_label_text(item.get('label', 0)), '相关视频数': item.get('video_count', 0), '讨论视频数': item.get('discuss_video_count', 0), '事件时间': datetime.fromtimestamp(item.get('event_time', 0)).strftime('%Y-%m-%d %H:%M:%S') if item.get('event_time') else '', '话题ID': item.get('group_id', ''), '句子ID': item.get('sentence_id', ''), '句子标签': item.get('sentence_tag', 0), '封面图': item.get('word_cover', {}).get('url_list', [''])[0] if item.get('word_cover') else '' } main_df.append(row) df_main = pd.DataFrame(main_df) df_main.to_excel(writer, sheet_name='主榜', index=False) # 2. 实时上升热点 trending_list = self.data['data'].get('trending_list', []) if trending_list: trend_df = [] for idx, item in enumerate(trending_list, 1): row = { '排名': idx, '标题': item.get('word', ''), '相关视频数': item.get('video_count', 0), '讨论视频数': item.get('discuss_video_count', 0), '事件时间': datetime.fromtimestamp(item.get('event_time', 0)).strftime('%Y-%m-%d %H:%M:%S') if item.get('event_time') else '', '话题ID': item.get('group_id', ''), '句子ID': item.get('sentence_id', ''), '句子标签': item.get('sentence_tag', 0), '封面图': item.get('word_cover', {}).get('url_list', [''])[0] if item.get('word_cover') else '' } trend_df.append(row) df_trend = pd.DataFrame(trend_df) df_trend.to_excel(writer, sheet_name='上升热点', index=False) # 3. 全局信息 info = { '更新时间': active_time, '分享标题': self.data['data'].get('share_info', {}).get('share_title', ''), '分享链接': self.data['data'].get('share_info', {}).get('share_url', ''), '上升热点描述': self.data['data'].get('trending_desc', ''), '展示样式': self.data['data'].get('display_style', 0) } df_info = pd.DataFrame([info]) df_info.to_excel(writer, sheet_name='全局信息', index=False) print(f"数据已保存至: {filename}") def print_hotlist(self): """在控制台打印当前存储的热榜数据""" if not self.data: print("无数据可打印") return print("\n" + "="*70) print(f"📈 抖音热榜 - 更新时间: {self.data['data'].get('active_time', '未知')}") print("="*70) # 主榜 print("\n🔥 【热榜主榜】") for idx, item in enumerate(self.data['data']['word_list'], 1): word = item.get('word', '无标题') hot_value = item.get('hot_value', 0) label = item.get('label', 0) label_text = self.get_label_text(label) hot_str = self.format_hot_value(hot_value) print(f"{idx:3}. {word:<38}{label_text:>4} 热度: {hot_str:>12}") # 上升热点 print("\n\n📈 【实时上升热点】") trending = self.data['data'].get('trending_list', []) for idx, item in enumerate(trending, 1): word = item.get('word', '无标题') video_count = item.get('video_count', 0) discuss_count = item.get('discuss_video_count', 0) print(f"{idx:3}. {word:<50} 相关视频: {video_count} 个 | 讨论: {discuss_count} 个") @staticmethod def format_hot_value(value): """将热度值转换为万/亿格式""" if value >= 100000000: return f"{value/100000000:.1f}亿" elif value >= 10000: return f"{value/10000:.1f}万" else: return str(value) @staticmethod def get_label_text(label): """根据label值返回标签文字(热/沸/新/荐)""" label_map = { 1: "🔥热", 2: "💥沸", 3: "🌟新", 4: "👍荐" } return label_map.get(label, "")if __name__ == "__main__": # 请将下面的 COOKIE 替换为你最新的完整 Cookie YOUR_COOKIE = """ 你的完整Cookie字符串,请自行替换 """.strip() YOUR_COOKIE = " ".join(YOUR_COOKIE.split()) # 去除换行,整理为一行 douyin = DouyinHotlist(cookie=YOUR_COOKIE, save_excel=True) hot_data = douyin.fetch() if hot_data: douyin.print_hotlist() else: print("获取热榜失败,请检查 Cookie 是否过期。")