本文档出自APS 2023 GNN Tutorial,聚焦于图神经网络(Graph Neural Networks, GNNs)在构建第一性原理级原子间势能函数(interatomic potentials)中的理论基础、建模挑战与算法演进。以下将围绕算法原理与数学公式展开深度总结与分析,严格依据文稿逻辑脉络,不引入外部知识或代码实现,重点阐释GNN作为势能模型所必须满足的物理约束、其相较于传统方法(如Behler–Parrinello网络)的结构性优势,以及核心数学机制如何编码对称性、局域性与可微分性。
一、势能建模的根本约束
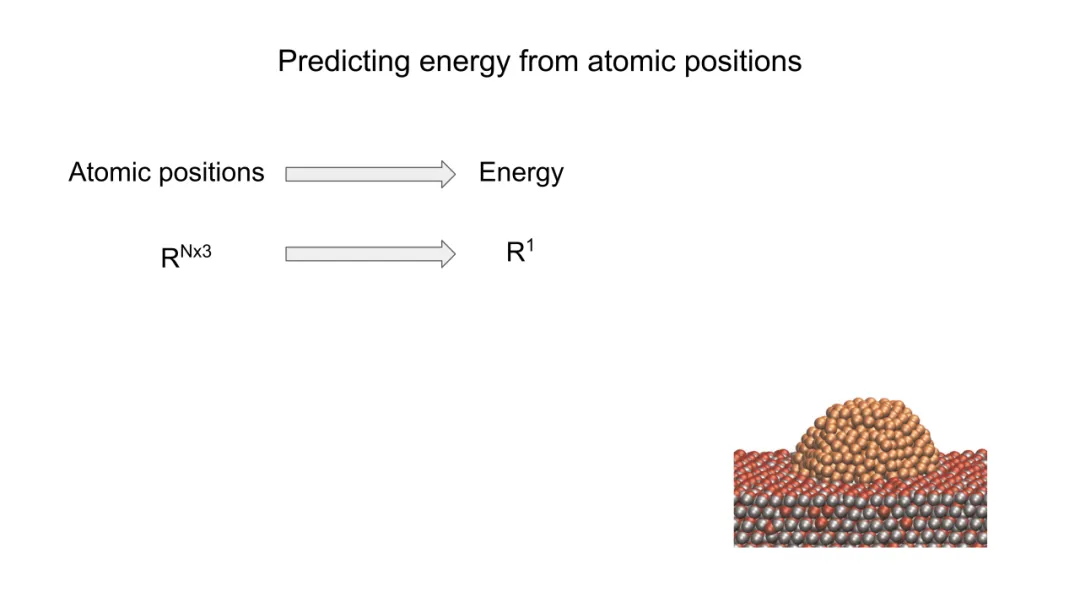
原子系统总能量 E 是原子位置集合
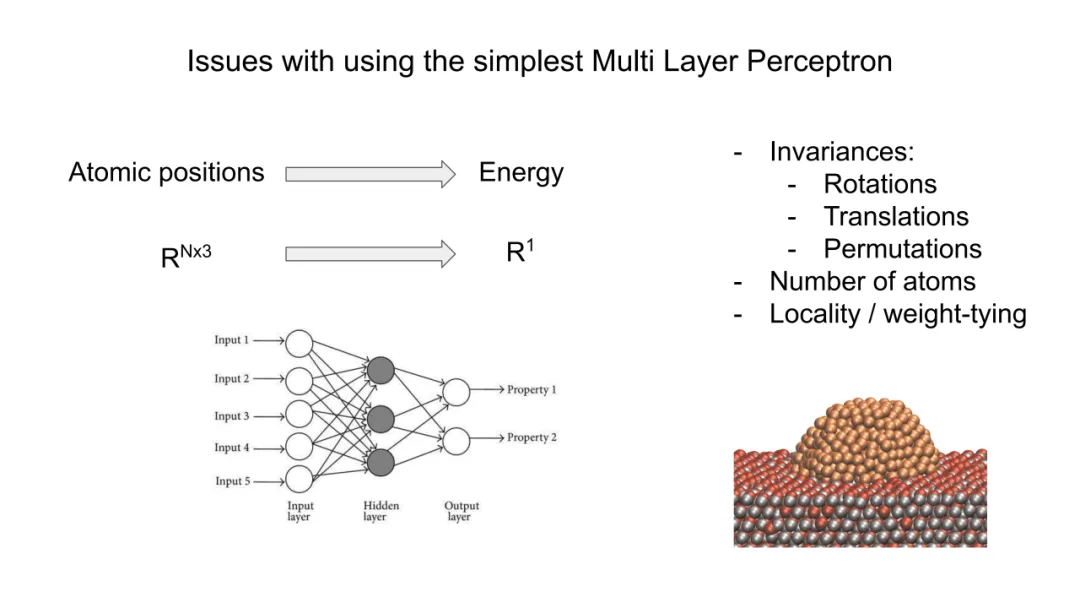
的标量函数。物理第一性原理要求该映射必须满足四重严格不变性(invariances):
1.平移不变性(Translation Invariance):
这意味着能量仅依赖于相对位矢rij=ri−rj,而非绝对坐标。任何势能模型必须将输入预处理为平移不变量,例如以某原子为原点或直接构造成对距离/角度。
2.旋转不变性(Rotation Invariance):
此约束要求所有特征必须是旋转群 SO(3) 下的标量(scalars)。例如,欧氏距离 rij=∥rij∥ 是标量;而向量 rij或张量 rij×rij⊤则需经迹、行列式等操作降维为标量,或通过球谐函数展开后取模平方以消除方向依赖。
3.置换不变性(Permutation Invariance):
对任意排列
这反映原子的全同性——能量不应随原子编号顺序改变。数学上,这要求映射 E:RN×3→R 必须是对称函数(symmetric function)。经典解法是采用对称聚合(symmetric aggregation),如求和、均值或最大值:
此处hi是第 i 个原子的局部嵌入(local embedding),⨁ 确保输出与输入排序无关。
4.系统规模不变性(Size Extensivity / Cardinality Invariance):
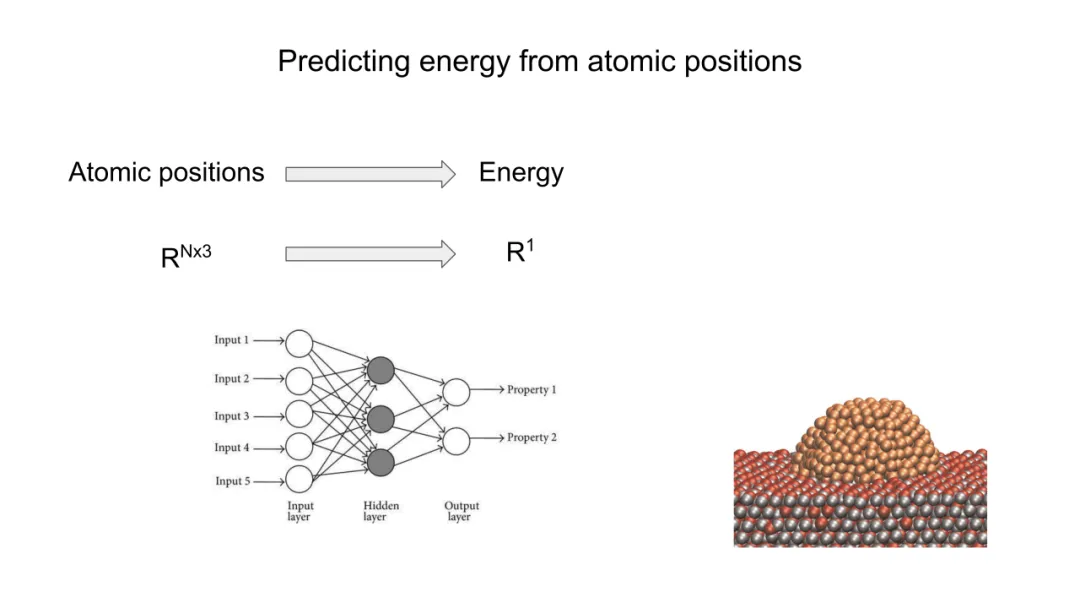
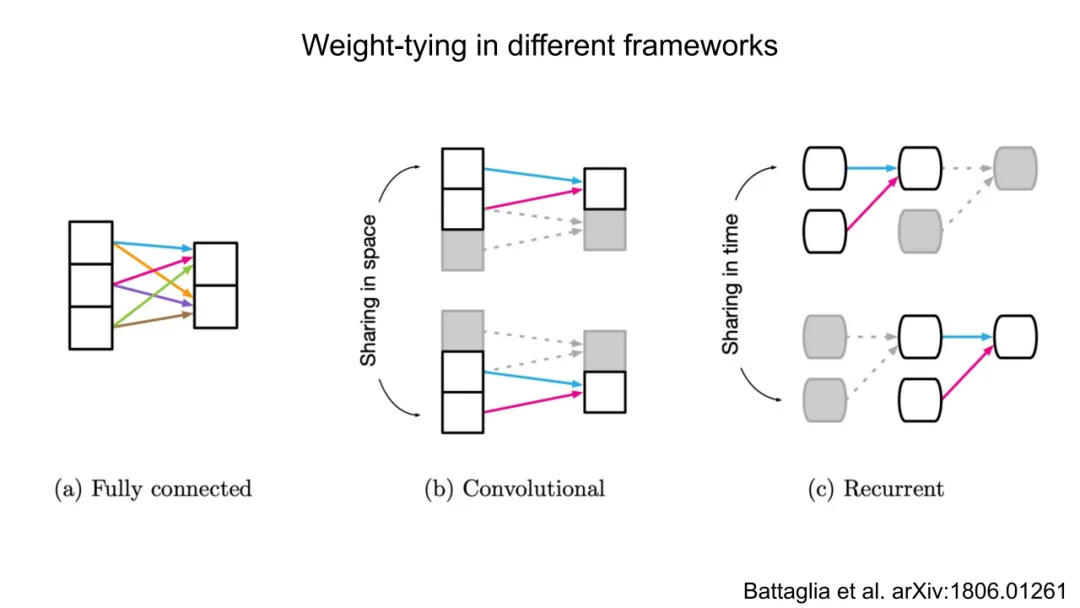
能量应随原子数近似线性增长(广延量),即 E∝N。这要求模型具有权重共享(weight-tying) 机制,避免参数数量随 N 增长。全连接MLP因参数与 N^2相关而天然违背此约束;而GNN通过节点级局部更新,使每层计算复杂度为 O(N)(若邻接稀疏),天然满足可扩展性。
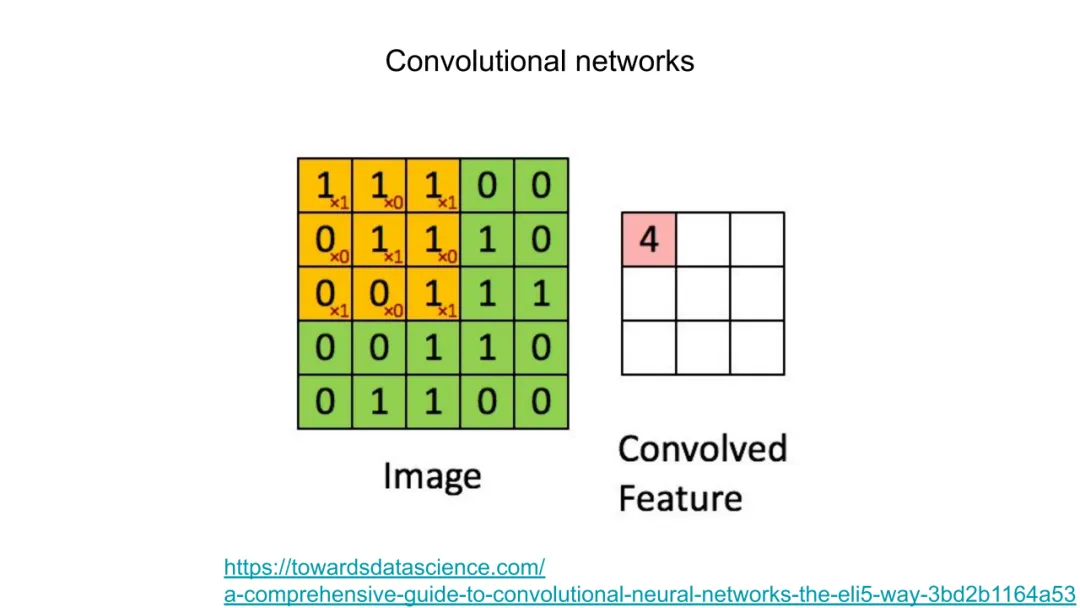
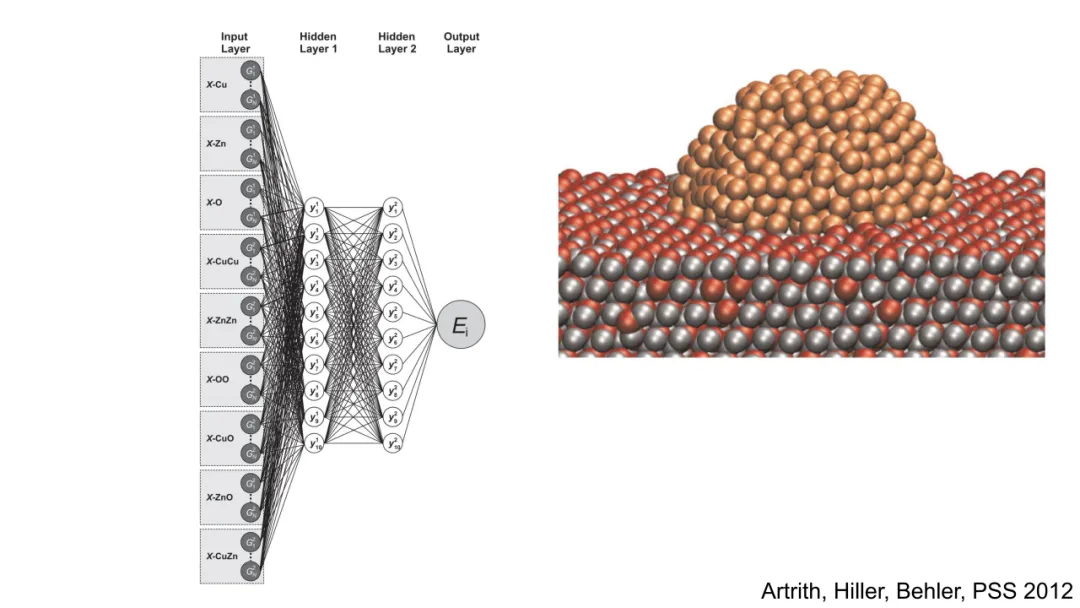
二、传统方法的局限
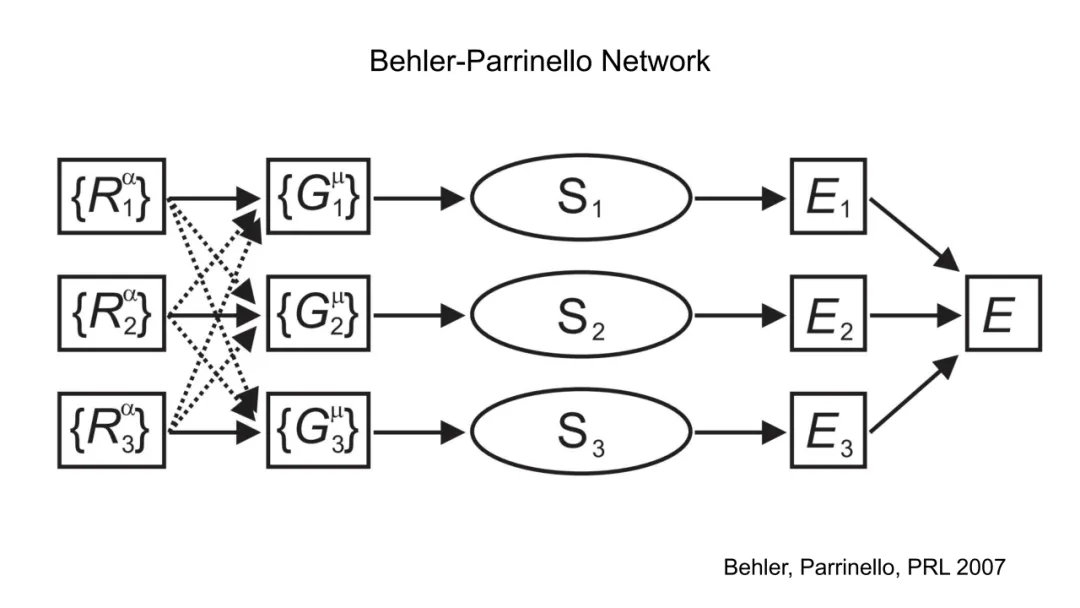
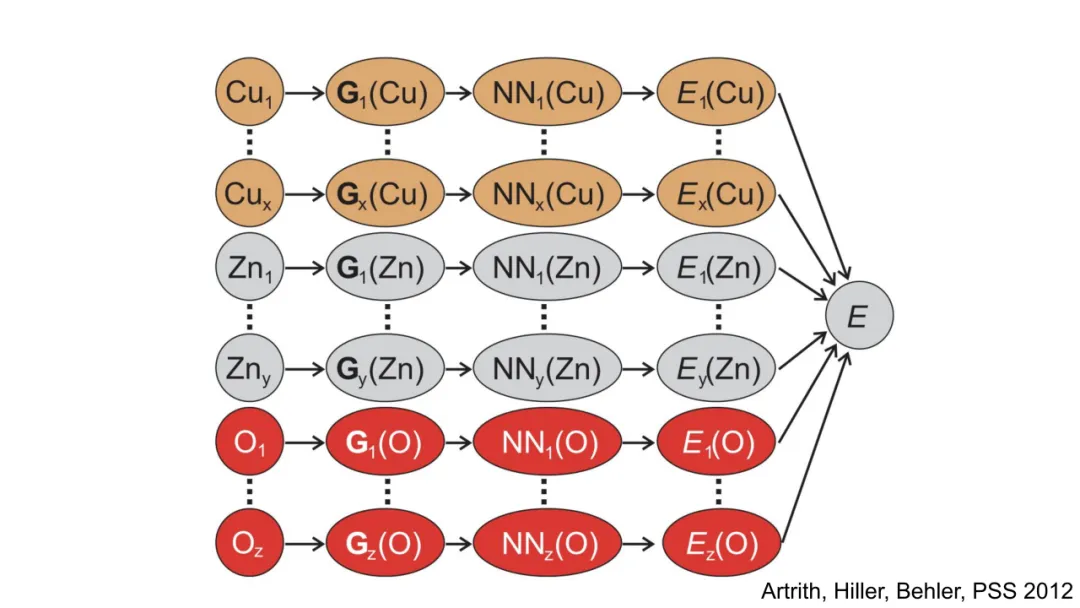
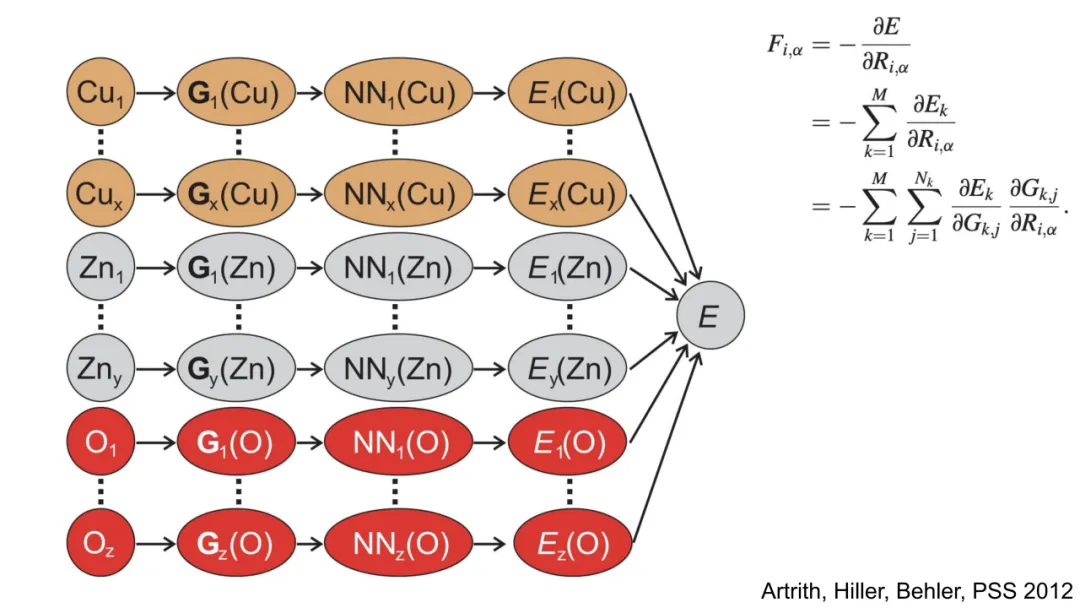
Behler–Parrinello(BP)网络是早期成功的手工特征+MLP范式。其核心在于构造对称函数集 {Gk(R)},将原子环境映射为固定维数向量,再输入MLP预测能量。典型对称函数包括:
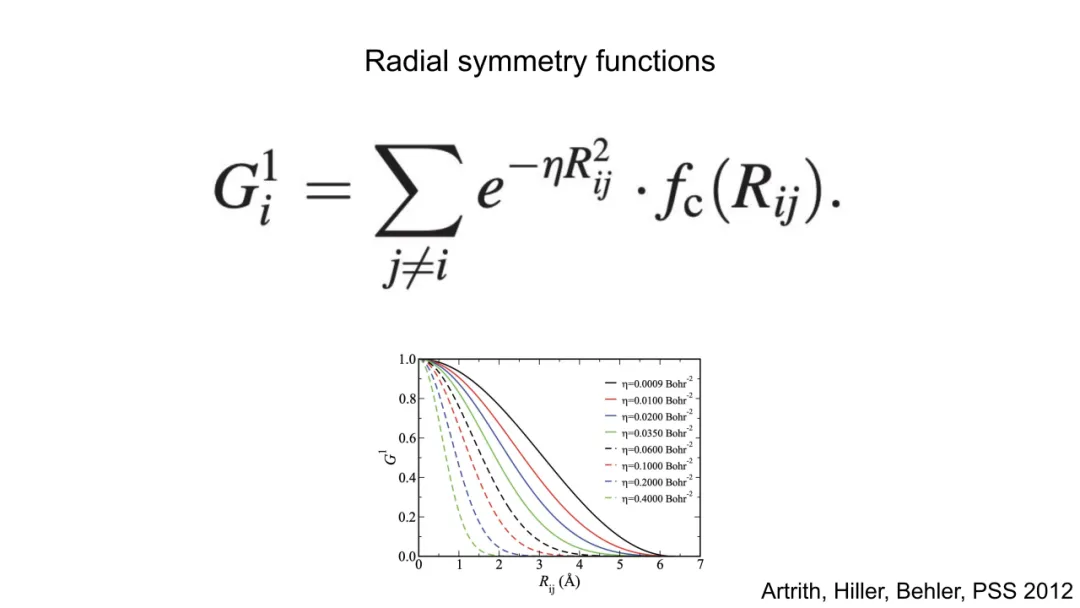
1.径向函数(Radial Symmetry Functions):
η,r s为超参,δτiτj指示原子类型匹配。该函数仅捕获中心原子 i 与其同类原子 j 的距离分布。
2.角度函数(Angular Symmetry Functions):
其中 θjik为夹角,λ=±1 控制奇偶性,ζ 控制角分布锐度。此函数编码三体相互作用,但显式依赖于角度余弦,丧失高阶几何信息。
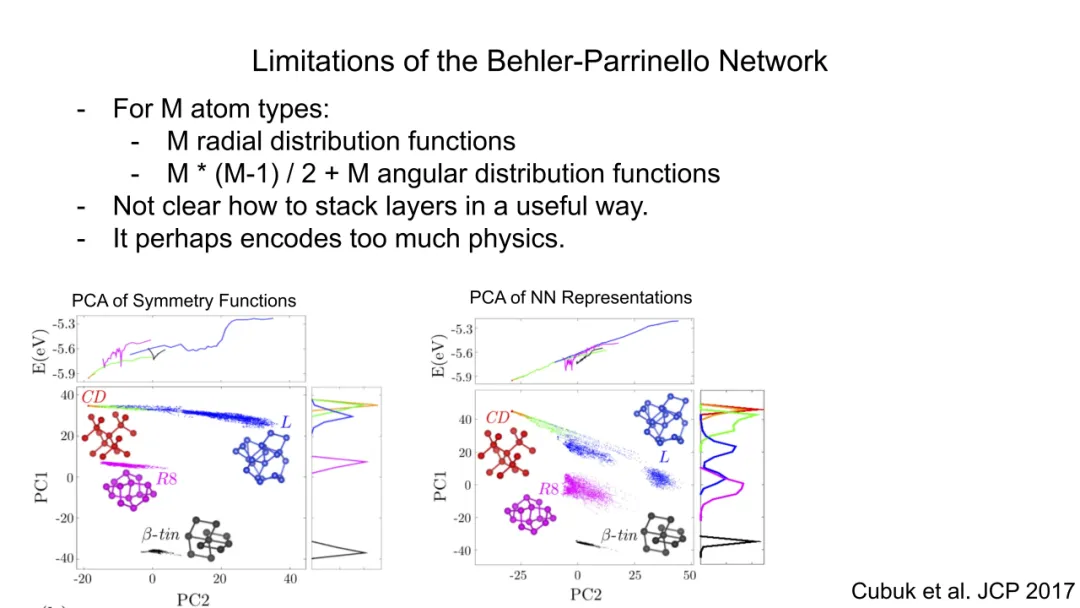
BP网络的数学缺陷在于:
特征工程僵化:函数形式由物理直觉预设,无法自适应学习最优表示;PCA分析(Cubuk et al., JCP 2017)表明其特征空间存在冗余与低效性。
层叠不可行:对称函数输出为固定维向量,缺乏内在图结构,无法定义“邻域消息传递”,故难以堆叠多层非线性变换以提取高阶关联。
物理先验过载:过度嵌入三体、四体等特定相互作用形式,反而限制模型在未知化学空间的泛化能力。
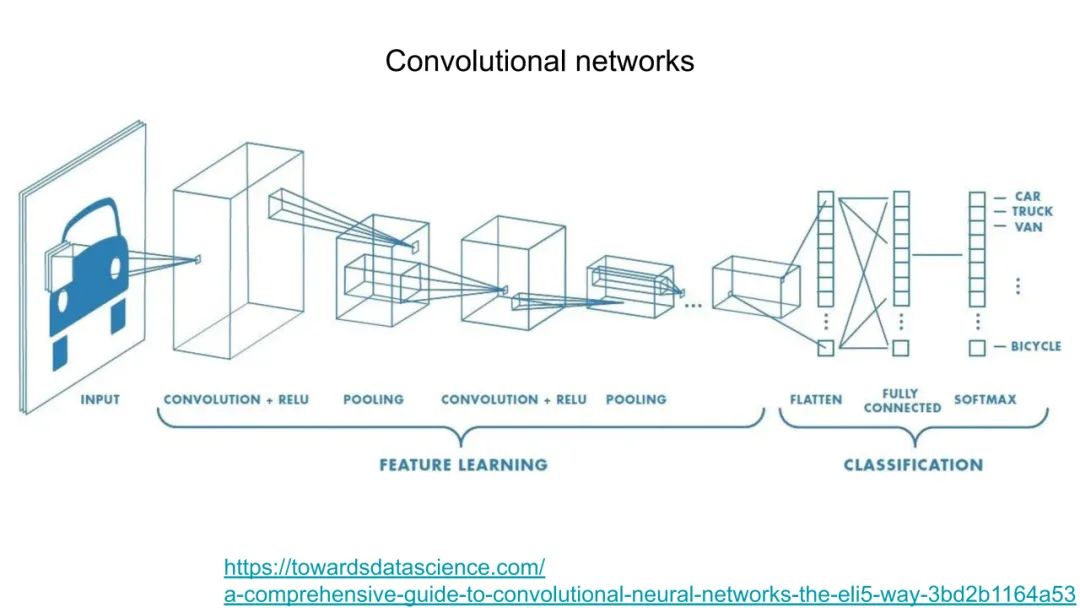
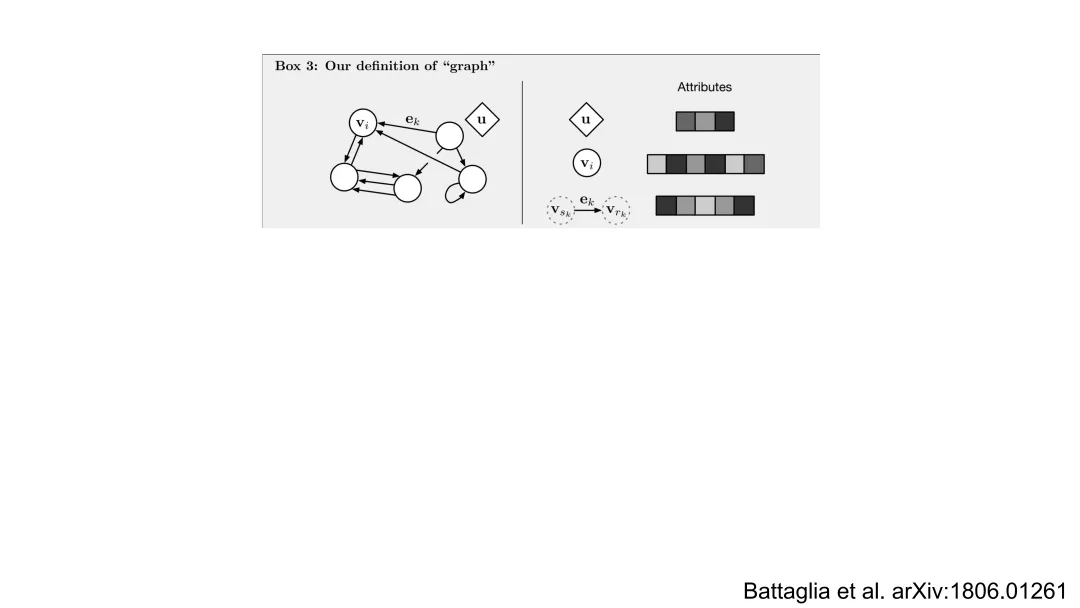
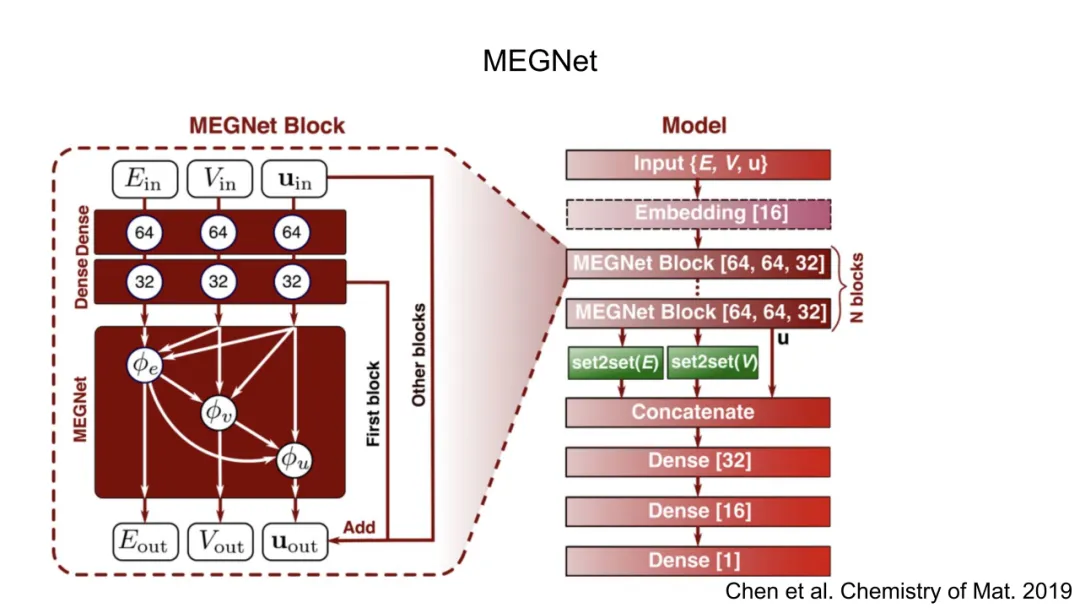
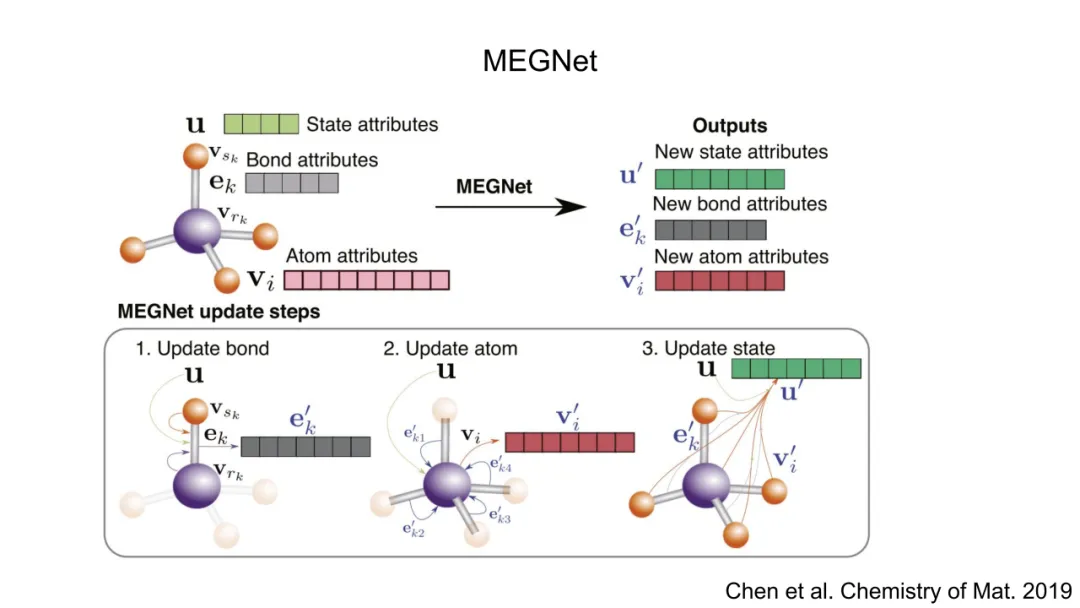
三、GNN的数学重构
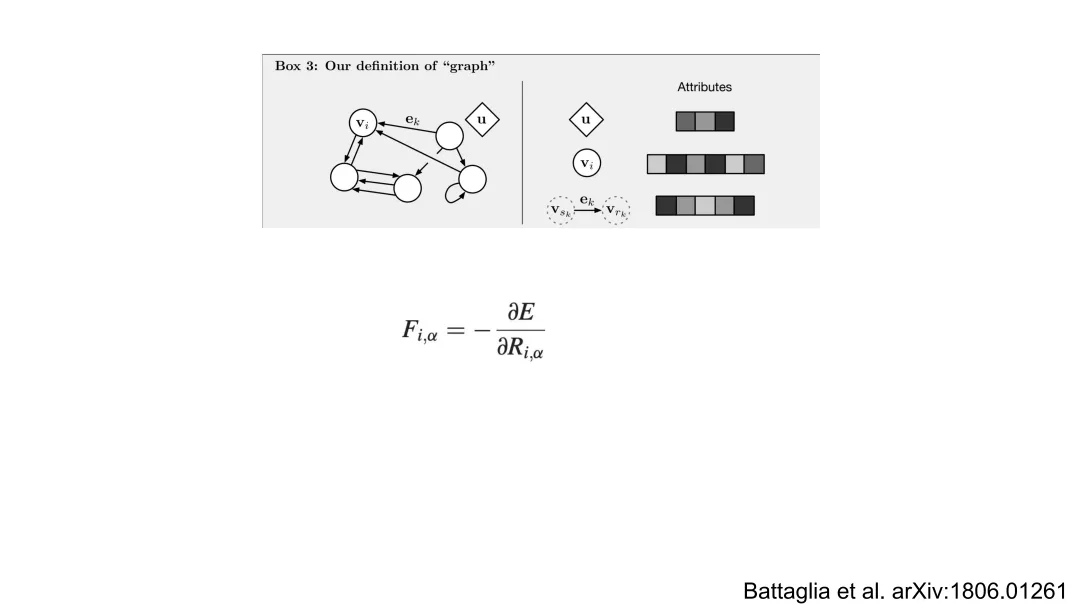
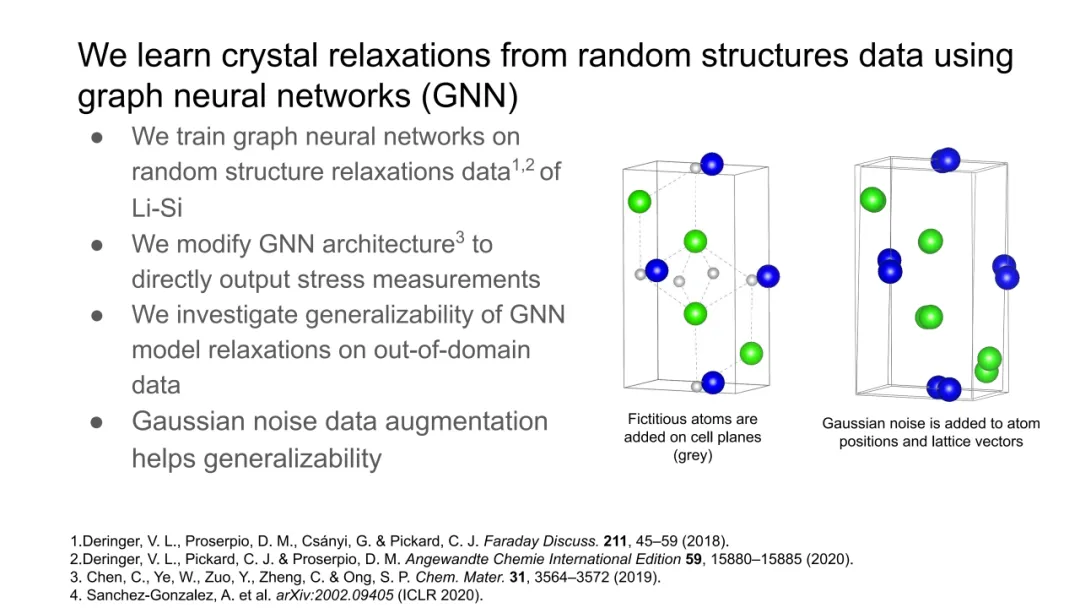
GNN将原子系统自然建模为无向图 G=(V,E):节点集 V={1,…,N} 表示原子,边集 E={(i,j)∣rij<rc} 由截断半径 rc定义的邻接关系构成。每个节点 i 拥有特征xi=[τi,ri](原子类型独热编码 + 位置),边 (i,j) 特征为 eij=[rij,rij]。
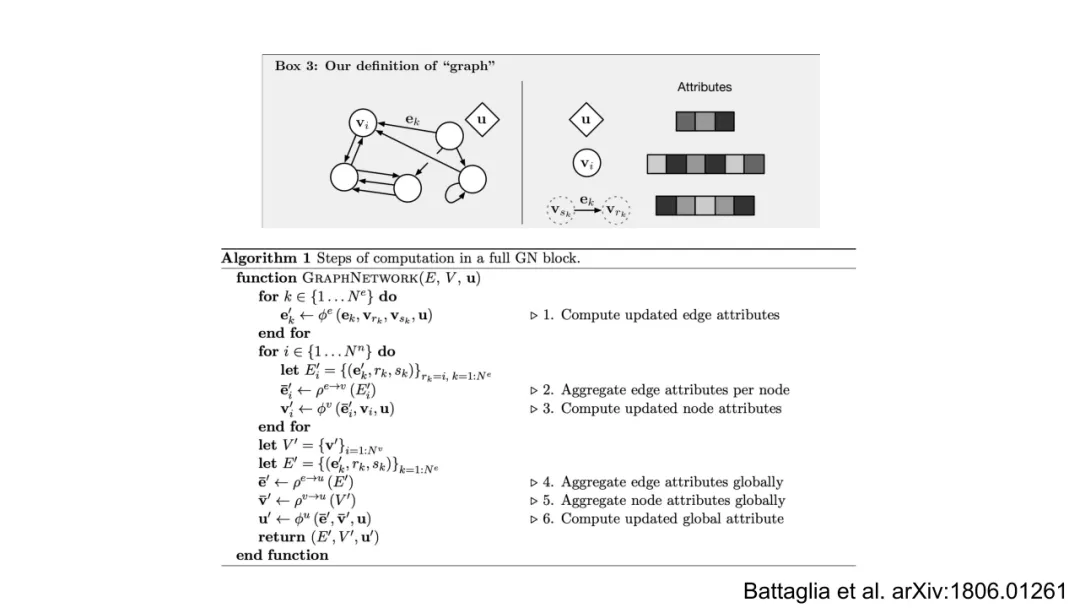
GNN的核心是消息传递框架(Message Passing Framework),其第 l 层更新遵循统一范式:
其中:
N(i) 是 i 的邻居集合;ϕ (l)是可学习的消息函数,输入为中心节点、邻居节点及边特征,输出消息向量;⨁ 是置换不变聚合算子(如求和),确保节点更新与邻居顺序无关,从而保障整体置换不变性ψ(l)是可学习的更新函数,融合旧状态与聚合消息。
关键突破在于:所有函数 ϕ(l),ψ(l)均为MLP,且其输入被精心设计为旋转/平移不变量。例如,ϕ(l)的输入可设为 {hi(l−1),h j(l−1),rij,gij},其中 gij是球谐函数对rij/rij的展开系数(如Ylm( r^ij)),其模平方∣Ylm∣2构成旋转不变标量基。这种构造使GNN在每一层都内生地保持旋转与平移不变性,无需后处理。最终全局能量预测为:
其中 ρ 是输出MLP,⨁ 再次保证置换与规模不变性。应力张量 σ 可通过对能量关于晶格矢量 H 求导获得:
这依赖于整个计算图的自动微分(automatic differentiation)——JAX-MD正是为此提供端到端可微框架。
四、归纳偏置与可扩展性
GNN的成功根植于其与物理系统的归纳偏置(inductive bias)对齐:
1.局域性(Locality):消息仅在rc内传递,对应真实短程相互作用,计算复杂度 O(N)(经空间划分优化);
2.对称性(Symmetry):通过不变量输入与对称聚合,数学上严格嵌入物理定律;
3.可组合性(Composability):多层消息传递可渐进式构建 k-体关联(k 随层数增长),超越BP网络固定的二体/三体截断。
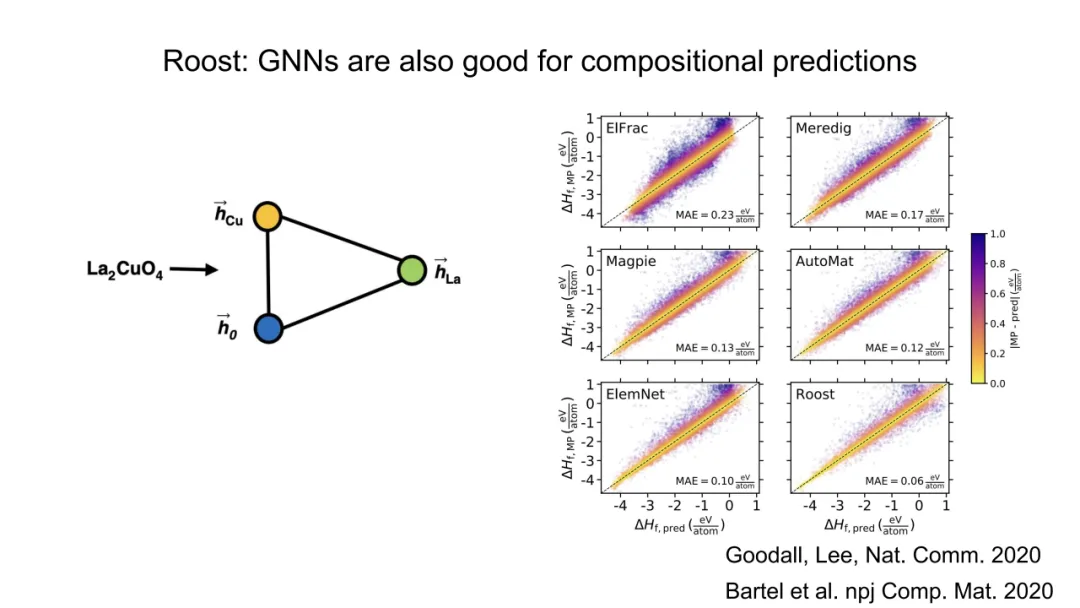
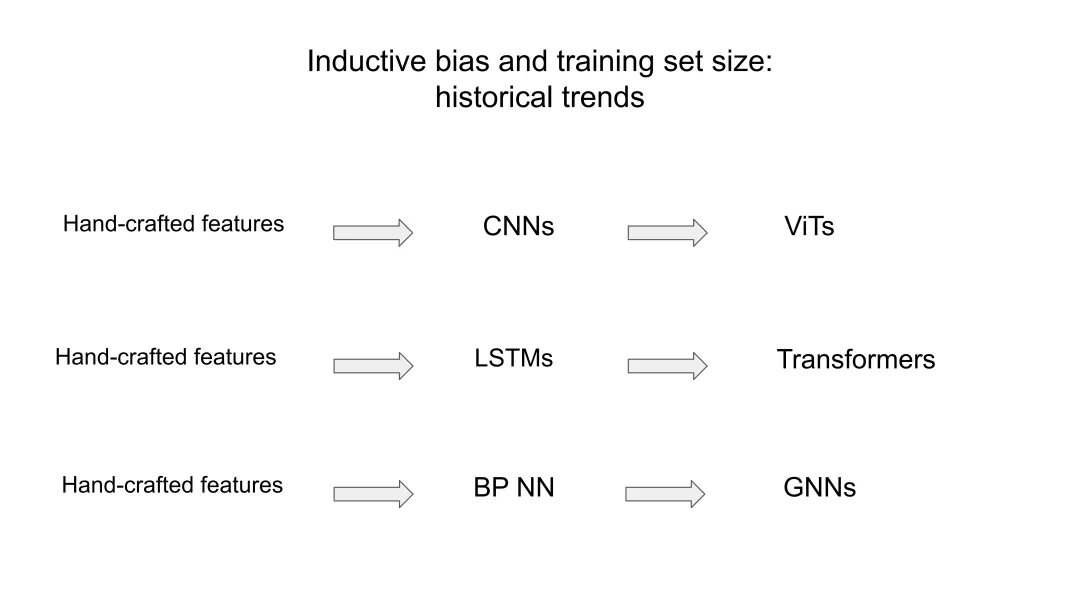
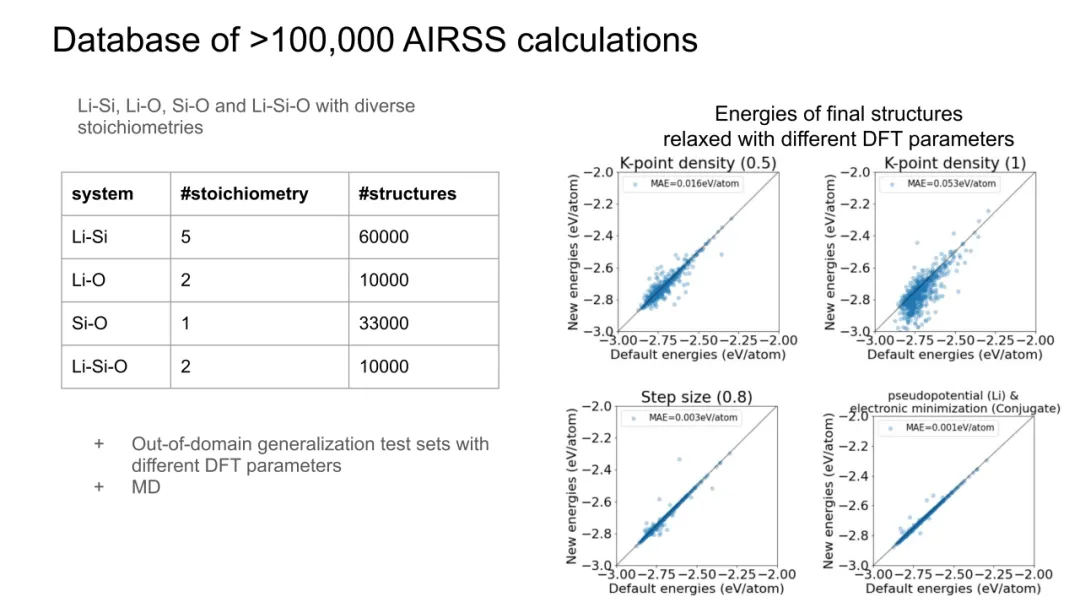
相较而言,CNN在图像任务中依赖平移等变性(equivariance),而GNN在原子系统中需旋转/平移不变性,二者数学基础迥异。ViT等架构虽具强表达力,但缺乏对原子间几何约束的先验,需海量数据补偿,而GNN以少量数据(如Li-Si体系数千结构)即可收敛,印证其归纳偏置的有效性。
综上,GNN并非黑箱替代品,而是以严格的群论约束为骨架、以可学习图算子为肌肉的势能建模范式。其数学本质是:在对称性流形上定义的、满足物理守恒律的、可微分的、可扩展的函数逼近器。未来突破将聚焦于更优的不变特征基(如SE(3)-equivariant表示)、应力预测的协变性保障,以及跨元素泛化的鲁棒图拓扑学习。
与我交流(为方便长期交流合作,加好友请按要求备注行业/专业,不胜感激))
微信号|wx18813053116
常用马甲|Grandfissure
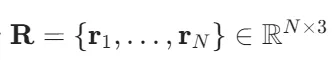
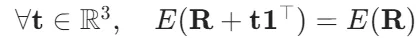
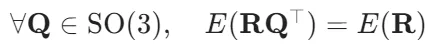
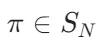
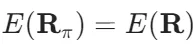

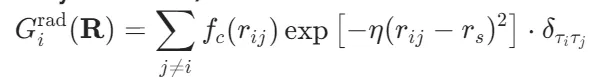
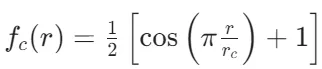
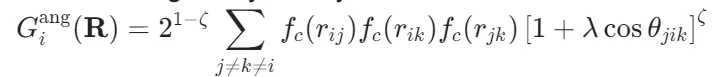
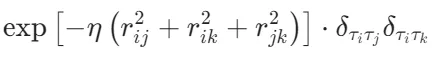
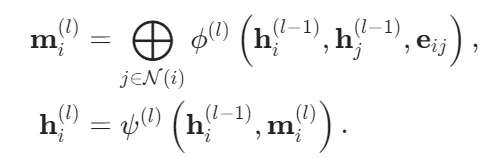
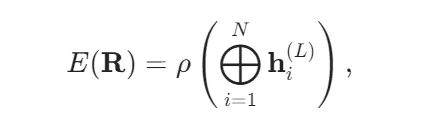
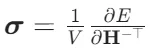






















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
