【小沐学Python】别再加班处理Excel了!Python自动化让你准时下班!(12)
- 2026-05-21 06:57:04

pip install openpyxl pandas xlsxwriter xlrd xlwt pyxlsb1. openpyxl:现代化的 Excel 操作利器
openpyxl 是一个用于读写 Excel 2010 xlsx/xlsm/xltx/xltm 文件的 Python 库,它提供了丰富的 API,可以处理 Excel 文件的各个方面,包括单元格、行、列、工作表、样式、公式等。openpyxl 完全用 Python 编写,不需要安装 Excel 或其他依赖,支持最新的 Excel 格式,是目前 Python 处理 Excel 文件的首选库之一。
openpyxl 的优势包括:支持读写 .xlsx 格式文件;可以创建新文件或修改现有文件;支持丰富的格式设置,如字体、颜色、边框等;支持图表和图片的插入;支持公式的读取和写入。不过需要注意的是,openpyxl 不支持 .xls 格式的老版本 Excel 文件,如果需要处理 .xls 文件,应该使用 xlrd 库。
1.1 openpyxl 的基本操作
使用 openpyxl 进行基本的 Excel 操作非常直观。我们可以创建工作簿、添加工作表、写入数据、读取数据,最后保存文件。openpyxl 的设计理念是让 Excel 操作尽可能简单,同时保持灵活性。在开始操作之前,需要先创建或打开一个工作簿对象,然后通过工作簿访问其中的工作表,最后通过工作表访问单元格。

下面的示例展示了如何使用 openpyxl 创建一个新的 Excel 文件,并写入一些基本数据:
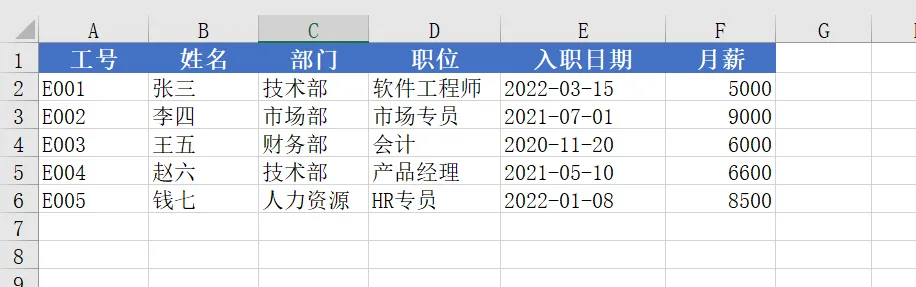
from openpyxl import Workbookfrom openpyxl.styles import Font, PatternFill, Alignment# 创建一个新的工作簿wb = Workbook()ws = wb.activews.title = "员工信息表"# 设置标题行headers = ["工号", "姓名", "部门", "职位", "入职日期", "月薪"]ws.append(headers)# 添加一些示例数据employees = [["E001", "张三", "技术部", "软件工程师", "2022-03-15", 5000],["E002", "李四", "市场部", "市场专员", "2021-07-01", 9000],["E003", "王五", "财务部", "会计", "2020-11-20", 6000],["E004", "赵六", "技术部", "产品经理", "2021-05-10", 6600],["E005", "钱七", "人力资源", "HR专员", "2022-01-08", 8500]]# 写入员工数据for emp in employees:ws.append(emp)# 设置标题样式header_fill = PatternFill(start_color="4472C4", end_color="4472C4", fill_type="solid")header_font = Font(bold=True, color="FFFFFF", size=12)header_alignment = Alignment(horizontal="center", vertical="center")for col in range(1, len(headers) + 1):cell = ws.cell(row=1, column=col)cell.fill = header_fillcell.font = header_fontcell.alignment = header_alignment# 设置列宽column_widths = [10, 10, 10, 12, 15, 10]for col, width in enumerate(column_widths, 1):ws.column_dimensions[chr(64 + col)].width = width# 保存文件wb.save("employees.xlsx")print("✓ 员工信息表已成功创建:employees.xlsx")
代码运行结果如下:
1.2 读取和修改现有 Excel 文件
openpyxl 不仅可以创建新的 Excel 文件,还可以读取和修改现有的文件。这在实际工作中非常有用,比如更新报表数据、修改配置信息等。读取 Excel 文件时,可以按照工作表、行、列、单元格的方式访问数据,非常灵活。修改数据后,只需要保存文件即可更新原文件。
下面的示例展示了如何读取 Excel 文件中的数据,并进行一些统计和分析:
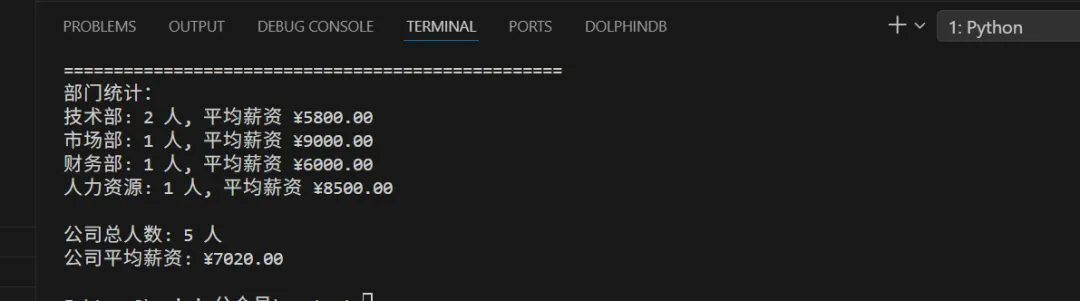
from openpyxl import load_workbookfrom datetime import datetime# 打开现有的 Excel 文件wb = load_workbook("employees.xlsx")ws = wb["员工信息表"]print("员工信息统计:")print("=" * 50)# 读取并显示所有员工信息print("\n所有员工列表:")for row in range(2, ws.max_row + 1):emp_id = ws.cell(row, 1).valuename = ws.cell(row, 2).valuedepartment = ws.cell(row, 3).valueposition = ws.cell(row, 4).valuesalary = ws.cell(row, 6).valueprint(f"{emp_id} | {name} | {department} | {position} | ¥{salary}")# 统计各部门人数和平均薪资department_stats = {}total_salary = 0for row in range(2, ws.max_row + 1):department = ws.cell(row, 3).valuesalary = ws.cell(row, 6).valueif department not in department_stats:department_stats[department] = {"count": 0, "total_salary": 0}department_stats[department]["count"] += 1department_stats[department]["total_salary"] += salarytotal_salary += salaryprint("\n" + "=" * 50)print("部门统计:")for dept, stats in department_stats.items():avg_salary = stats["total_salary"] / stats["count"]print(f"{dept}: {stats['count']} 人, 平均薪资 ¥{avg_salary:.2f}")print(f"\n公司总人数: {ws.max_row - 1} 人")print(f"公司平均薪资: ¥{total_salary / (ws.max_row - 1):.2f}")
代码运行结果如下:
2. pandas:数据分析的神器
pandas 是 Python 中最流行的数据分析库之一,它提供了强大的数据结构和数据分析工具。pandas 的 read_excel() 和 to_excel() 函数让 Excel 文件的读取和写入变得异常简单,更重要的是,pandas 可以直接将 Excel 数据读取为 DataFrame,然后利用 pandas 强大的数据处理能力进行各种分析操作。
pandas 处理 Excel 的优势在于:可以快速读取大量数据;支持多种数据格式转换;内置丰富的数据分析功能;支持数据过滤、分组、聚合等操作;可以轻松处理缺失数据;支持多工作表读取。pandas 底层使用了 openpyxl 或 xlrd 作为引擎,因此具有很好的兼容性。
2.1 使用 pandas 读取 Excel 文件
pandas 的 read_excel() 函数可以轻松地将 Excel 文件读取为 DataFrame,支持多种参数配置,比如指定工作表、选择特定列、设置索引列、处理缺失值等。读取后的 DataFrame 可以像表格一样进行各种操作,非常适合数据分析场景。
下面的示例展示了如何使用 pandas 读取 Excel 文件,并进行数据分析和可视化:
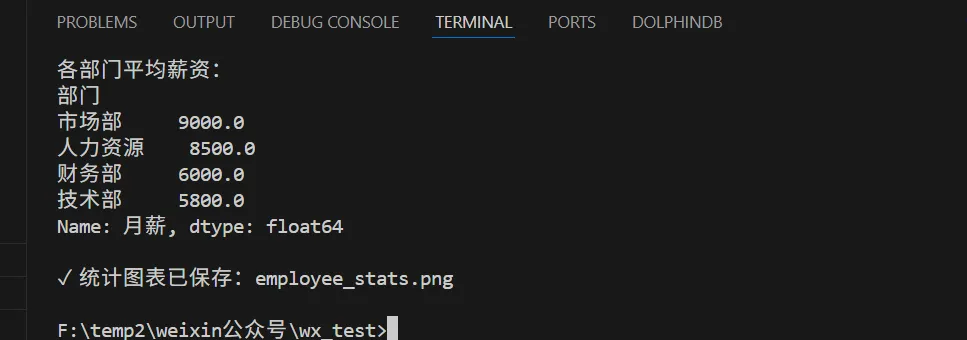
import pandas as pdimport matplotlib.pyplot as plt# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 读取 Excel 文件df = pd.read_excel("employees.xlsx", sheet_name="员工信息表")print("数据预览:")print(df.head())print("\n数据统计信息:")print(df.describe())# 按部门统计人数dept_count = df['部门'].value_counts()print("\n各部门人数:")print(dept_count)# 按部门统计平均薪资dept_salary = df.groupby('部门')['月薪'].mean().sort_values(ascending=False)print("\n各部门平均薪资:")print(dept_salary)# 创建可视化图表fig, axes = plt.subplots(1, 2, figsize=(14, 5))# 部门人数柱状图dept_count.plot(kind='bar', ax=axes[0], color='skyblue')axes[0].set_title('各部门人数统计')axes[0].set_xlabel('部门')axes[0].set_ylabel('人数')# 部门平均薪资柱状图dept_salary.plot(kind='bar', ax=axes[1], color='lightgreen')axes[1].set_title('各部门平均薪资')axes[1].set_xlabel('部门')axes[1].set_ylabel('平均薪资')plt.tight_layout()plt.savefig('employee_stats.png', dpi=300, bbox_inches='tight')print("\n✓ 统计图表已保存:employee_stats.png")
代码运行结果如下:
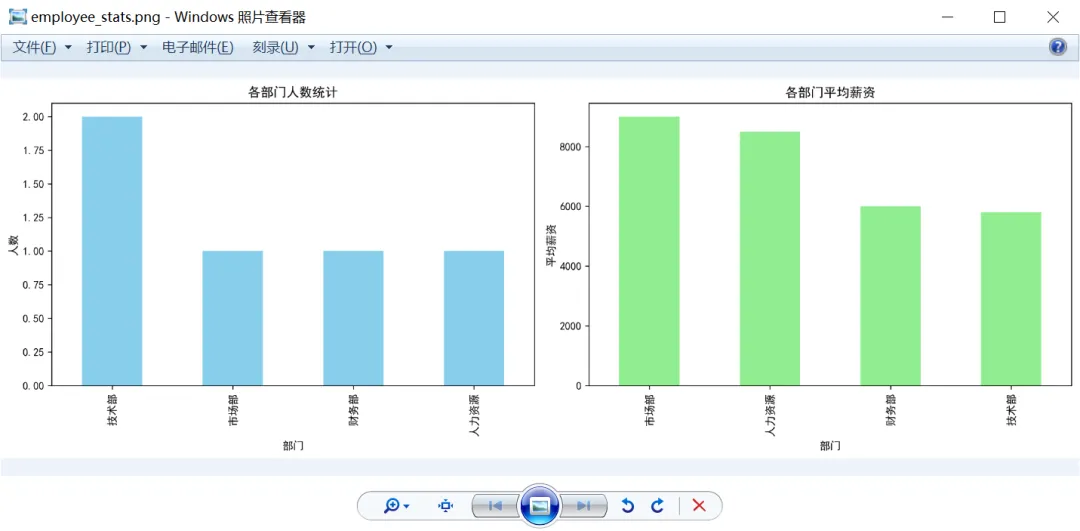
2.2 使用 pandas 写入 Excel 文件
pandas 的 to_excel() 函数可以将 DataFrame 写入 Excel 文件,支持多种输出选项,比如指定工作表名称、设置索引、控制格式等。pandas 还支持将多个 DataFrame 写入同一个 Excel 文件的不同工作表中,非常适合生成多页报表。
下面的示例展示了如何使用 pandas 将分析结果写入 Excel 文件:
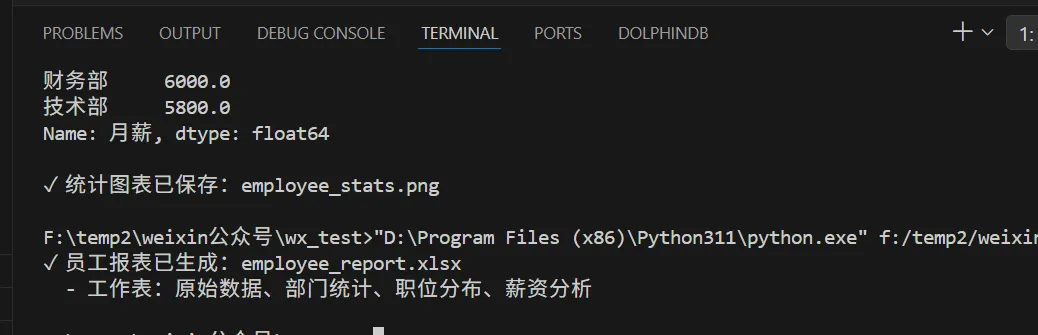
import pandas as pd# 读取原始数据df = pd.read_excel("employees.xlsx", sheet_name="员工信息表")# 数据分析:计算各部门统计信息dept_stats = df.groupby('部门').agg({'工号': 'count','月薪': ['mean', 'min', 'max', 'sum']}).round(2)dept_stats.columns = ['人数', '平均薪资', '最低薪资', '最高薪资', '总薪资']# 数据分析:计算职级分布position_stats = df['职位'].value_counts().reset_index()position_stats.columns = ['职位', '人数']# 创建 Excel Writer 对象with pd.ExcelWriter('employee_report.xlsx', engine='openpyxl') as writer:# 写入原始数据df.to_excel(writer, sheet_name='原始数据', index=False)# 写入部门统计dept_stats.to_excel(writer, sheet_name='部门统计')# 写入职位分布position_stats.to_excel(writer, sheet_name='职位分布', index=False)# 写入薪资分析salary_analysis = pd.DataFrame({'指标': ['总薪资', '平均薪资', '最高薪资', '最低薪资', '薪资中位数'],'数值': [df['月薪'].sum(),df['月薪'].mean(),df['月薪'].max(),df['月薪'].min(),df['月薪'].median()]})salary_analysis.to_excel(writer, sheet_name='薪资分析', index=False)print("✓ 员工报表已生成:employee_report.xlsx")print(" - 工作表:原始数据、部门统计、职位分布、薪资分析")
代码运行结果如下:
3. xlsxwriter:专业的 Excel 写入工具
xlsxwriter 是一个专门用于写入 Excel 文件的 Python 库,它专注于创建高质量的 Excel 文件,支持丰富的格式设置、图表、条件格式、数据验证等功能。xlsxwriter 的特点是写入速度快、功能强大、生成的文件质量高,特别适合生成报表、导出数据等场景。

xlsxwriter 的优势包括:纯 Python 实现,无需安装 Excel;支持大量的 Excel 功能,如图表、图片、公式、条件格式等;写入性能优秀;生成的文件兼容性好;支持大数据量的写入。不过需要注意的是,xlsxwriter 只能创建新文件,不能修改已有的 Excel 文件。
3.1 创建带有图表的 Excel 报表
xlsxwriter 提供了强大的图表功能,可以轻松创建各种类型的图表,包括柱状图、折线图、饼图、散点图等。图表可以自定义样式、标题、轴标签、图例等属性,让数据可视化更加专业。在生成报表时,图表可以帮助读者更直观地理解数据。
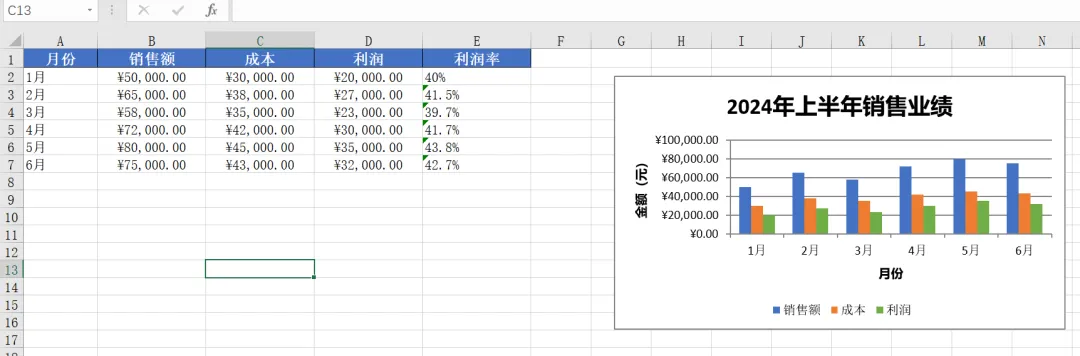
下面的示例展示了如何使用 xlsxwriter 创建一个包含图表的销售报表:
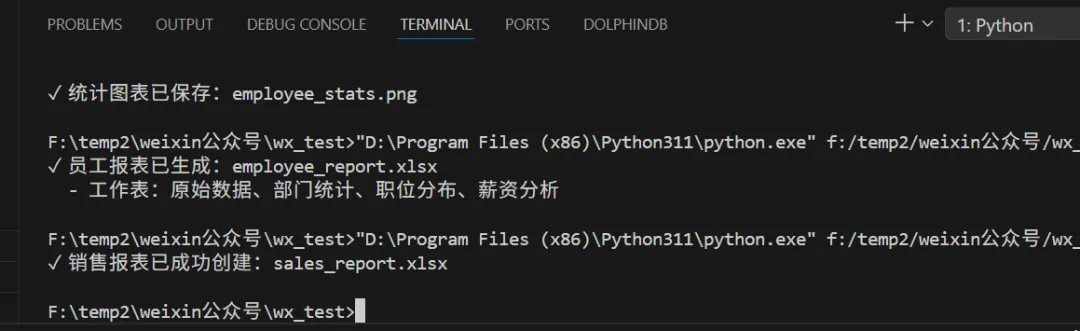
import xlsxwriter# 创建一个新的 Excel 文件workbook = xlsxwriter.Workbook('sales_report.xlsx')worksheet = workbook.add_worksheet('销售数据')# 定义格式header_format = workbook.add_format({'bold': True,'font_size': 12,'bg_color': '#4472C4','font_color': 'white','align': 'center','valign': 'vcenter','border': 1})number_format = workbook.add_format({'num_format': '¥#,##0.00','align': 'center'})# 准备数据headers = ['月份', '销售额', '成本', '利润', '利润率']data = [['1月', 50000, 30000, 20000, '40%'],['2月', 65000, 38000, 27000, '41.5%'],['3月', 58000, 35000, 23000, '39.7%'],['4月', 72000, 42000, 30000, '41.7%'],['5月', 80000, 45000, 35000, '43.8%'],['6月', 75000, 43000, 32000, '42.7%']]# 写入标题worksheet.set_column('A:A', 10)worksheet.set_column('B:E', 15)for col, header in enumerate(headers):worksheet.write(0, col, header, header_format)# 写入数据for row, row_data in enumerate(data, 1):for col, cell_data in enumerate(row_data):if col in [1, 2, 3]: # 数值列应用格式worksheet.write(row, col, cell_data, number_format)else:worksheet.write(row, col, cell_data)# 创建柱状图chart = workbook.add_chart({'type': 'column'})# 添加数据系列chart.add_series({'name': '销售额','categories': ['销售数据', 1, 0, 6, 0],'values': ['销售数据', 1, 1, 6, 1],'fill': {'color': '#4472C4'}})chart.add_series({'name': '成本','categories': ['销售数据', 1, 0, 6, 0],'values': ['销售数据', 1, 2, 6, 2],'fill': {'color': '#ED7D31'}})chart.add_series({'name': '利润','categories': ['销售数据', 1, 0, 6, 0],'values': ['销售数据', 1, 3, 6, 3],'fill': {'color': '#70AD47'}})# 设置图表属性chart.set_title({'name': '2024年上半年销售业绩'})chart.set_x_axis({'name': '月份'})chart.set_y_axis({'name': '金额(元)'})chart.set_legend({'position': 'bottom'})# 插入图表worksheet.insert_chart('G2', chart, {'x_offset': 25, 'y_offset': 10})# 关闭工作簿workbook.close()print("✓ 销售报表已成功创建:sales_report.xlsx")
代码运行结果如下:
3.2 使用条件格式和数据验证
xlsxwriter 支持条件格式,可以根据单元格的值自动应用不同的格式,这对于数据可视化非常有帮助。同时,xlsxwriter 还支持数据验证功能,可以限制用户输入的数据类型或范围,提高数据质量。
下面的示例展示了如何使用条件格式和数据验证:
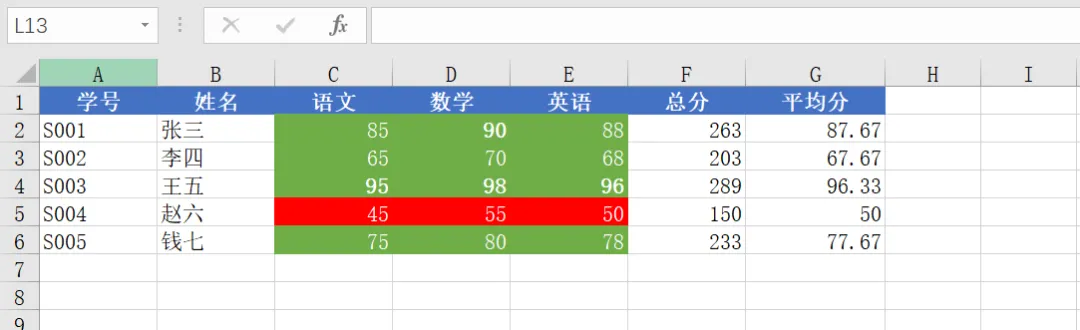
import xlsxwriter# 创建工作簿workbook = xlsxwriter.Workbook('student_scores.xlsx')worksheet = workbook.add_worksheet('学生成绩')# 定义格式header_format = workbook.add_format({'bold': True,'bg_color': '#4472C4','font_color': 'white','align': 'center'})pass_format = workbook.add_format({'bg_color': '#70AD47','font_color': 'white','align': 'center'})fail_format = workbook.add_format({'bg_color': '#FF0000','font_color': 'white','align': 'center'})excellent_format = workbook.add_format({'bg_color': '#FFD700','font_color': 'black','bold': True,'align': 'center'})# 写入标题headers = ['学号', '姓名', '语文', '数学', '英语', '总分', '平均分']for col, header in enumerate(headers):worksheet.write(0, col, header, header_format)# 准备数据students = [['S001', '张三', 85, 90, 88],['S002', '李四', 65, 70, 68],['S003', '王五', 95, 98, 96],['S004', '赵六', 45, 55, 50],['S005', '钱七', 75, 80, 78]]# 写入数据并计算总分和平均分for row, student in enumerate(students, 1):for col, data in enumerate(student):worksheet.write(row, col, data)# 计算总分total = sum(student[2:])worksheet.write(row, 5, total)# 计算平均分average = total / 3worksheet.write(row, 6, round(average, 2))# 应用条件格式# 及格条件(>=60)worksheet.conditional_format('C2:E6', {'type': 'cell','criteria': '>=','value': 60,'format': pass_format})# 不及格条件(<60)worksheet.conditional_format('C2:E6', {'type': 'cell','criteria': '<','value': 60,'format': fail_format})# 优秀条件(>=90)worksheet.conditional_format('C2:E6', {'type': 'cell','criteria': '>=','value': 90,'format': excellent_format})# 添加数据验证(分数必须在0-100之间)worksheet.data_validation('C2:E6', {'validate': 'integer','criteria': 'between','minimum': 0,'maximum': 100,'input_title': '请输入分数','input_message': '分数必须在 0 到 100 之间','error_title': '输入错误','error_message': '分数超出范围!'})# 设置列宽worksheet.set_column('A:B', 10)worksheet.set_column('C:F', 10)worksheet.set_column('G:G', 12)workbook.close()print("✓ 学生成绩表已创建:student_scores.xlsx")print(" - 包含条件格式(及格/不及格/优秀)")print(" - 包含数据验证(分数范围 0-100)")
代码运行结果如下:
4. xlrd 和 xlwt:处理老版本 Excel 文件
xlrd 和 xlwt 是专门用于处理 .xls 格式(Excel 97-2003)的老版本 Excel 文件的库。虽然现在的 Excel 主要使用 .xlsx 格式,但在一些旧系统或遗留项目中,仍然会遇到 .xls 文件。xlrd 用于读取 .xls 文件,xlwt 用于写入 .xls 文件。
需要注意的是,xlrd 和 xlwt 有一些限制:xlrd 只支持读取,不支持写入;xlwt 只支持写入,不支持读取;xlrd 从 2.0 版本开始不再支持 .xlsx 文件;xlwt 不支持新版本的 Excel 功能,如条件格式、图表等。对于新项目,建议使用 openpyxl 或 pandas。
4.1 使用 xlrd 读取 .xls 文件
xlrd 提供了简单的 API 来读取 .xls 文件中的数据。我们可以打开工作簿、选择工作表、读取单元格数据、遍历行和列等。xlrd 会自动处理 .xls 文件的编码问题,支持中文内容的读取。
下面的示例展示了如何使用 xlrd 读取 .xls 文件:
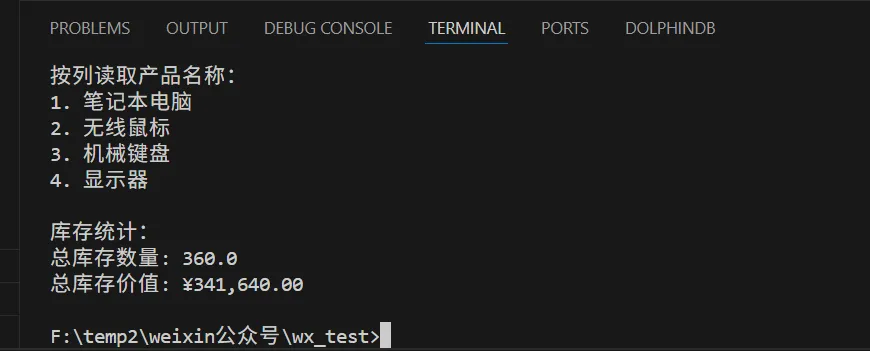
import xlrd# 注意:xlrd 2.0+ 不再支持 .xlsx 文件# 如果需要读取 .xlsx 文件,请使用 openpyxl 或 pandas# 创建一个 .xls 文件用于测试(使用 xlwt)import xlwtwb = xlwt.Workbook()ws = wb.add_sheet('产品信息')products = [['产品编号', '产品名称', '价格', '库存'],['P001', '笔记本电脑', 4999, 50],['P002', '无线鼠标', 99, 200],['P003', '机械键盘', 299, 80],['P004', '显示器', 1599, 30]]for row, product in enumerate(products):for col, value in enumerate(product):ws.write(row, col, value)wb.save('products.xls')# 使用 xlrd 读取 .xls 文件workbook = xlrd.open_workbook('products.xls')worksheet = workbook.sheet_by_name('产品信息')print("产品信息表:")print("=" * 60)# 获取工作表信息print(f"工作表名称: {worksheet.name}")print(f"行数: {worksheet.nrows}")print(f"列数: {worksheet.ncols}")print()# 读取所有数据print("所有产品信息:")for row in range(worksheet.nrows):row_data = []for col in range(worksheet.ncols):cell_value = worksheet.cell_value(row, col)row_data.append(str(cell_value))print(" | ".join(row_data))# 按列读取数据print("\n按列读取产品名称:")product_names = worksheet.col_values(1, start_rowx=1)for i, name in enumerate(product_names, 1):print(f"{i}. {name}")# 计算库存总量print("\n库存统计:")prices = worksheet.col_values(2, start_rowx=1)stocks = worksheet.col_values(3, start_rowx=1)total_stock = sum(stocks)total_value = sum(p * s for p, s in zip(prices, stocks))print(f"总库存数量: {total_stock}")print(f"总库存价值: ¥{total_value:,.2f}")
代码运行结果如下:

结语
如果您觉得这些文字有一点点用处,请给作者点个赞或关个注;╮( ̄▽ ̄)╭
如果您有技术问题探讨,评论处留言。//(ㄒoㄒ)//
谢谢各位童鞋们啦( ´ ▽ ` )ノ ( ´ ▽ `` )っ!
更多精彩文章详见:
CSDN博客:爱看书的小沐

