别再让Excel导入拖垮系统:百万条数据秒级入库全链路实战
- 2026-05-19 04:45:37
别再让Excel导入拖垮系统:百万条数据秒级入库全链路实战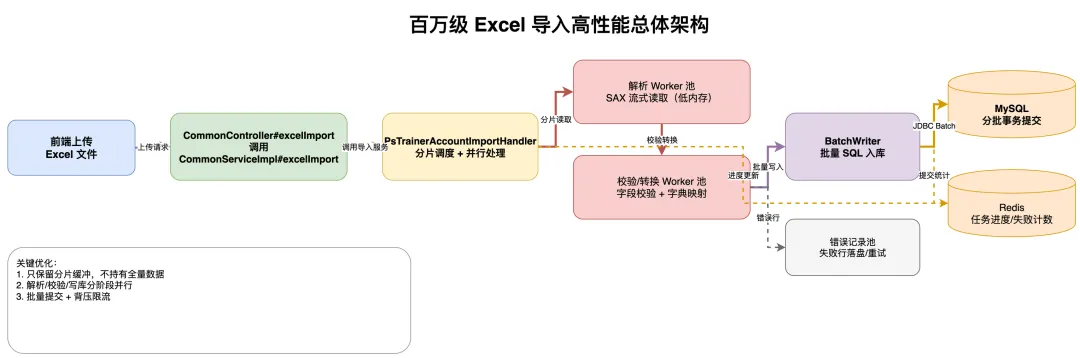
百万级Excel导入总体架构 4.2
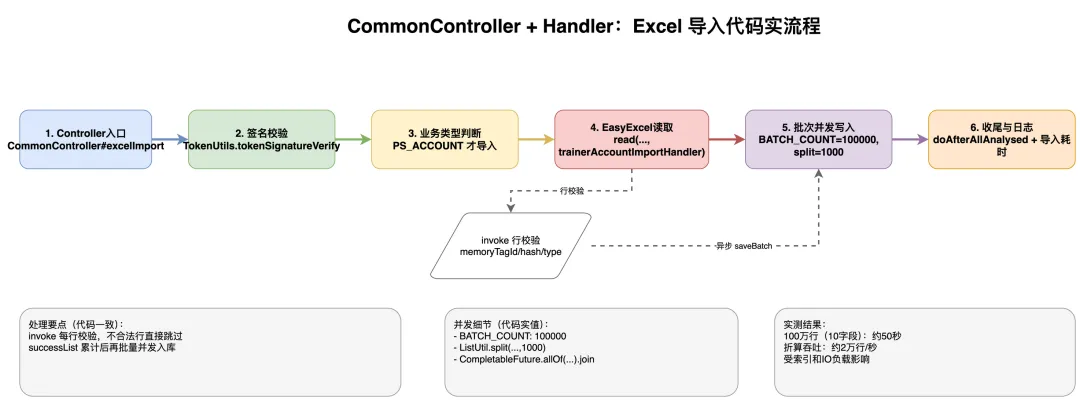
分片并行与批量写入流程
别再让Excel导入拖垮系统:百万条数据秒级入库全链路实战
一、前言
很多系统在做 Excel 导入时,代码逻辑并不复杂,但一到 50 万行、100 万行就会出现:
• 接口超时,用户反复重传 • JVM 内存飙升,Full GC 频发 • 数据库写入抖动,线上业务被拖慢
本文代码片段给出一套可直接落地的百万级导入优化方案:
• 流式解析(不把全量数据读入内存) • 分片并行(解析/校验/写库解耦) • 批量写库(控制事务粒度) • 进度可观测(支持失败重试)
二、先看全链路架构
核心思想只有一句话:让 CPU 做 CPU 擅长的事,让 IO 做 IO 擅长的事,中间用队列削峰填谷。
三、Controller 入口
excelImport 方法非常薄,只做请求接入和服务转发:
1. 接收 authorization和ExcelImportDTO2. 调用 commonService.excelImport(...)3. 返回统一 ApiResult.success()
@PostMapping("excelImport")public ApiResult<String> excelImport(@RequestHeader String authorization, ExcelImportDTO excelImportDTO) { commonService.excelImport(authorization, excelImportDTO); return ApiResult.success();}四、Service 与 Handler:核心导入逻辑
4.1 Service入口
excelImport 负责鉴权、业务类型判断、触发 EasyExcel 读取并统计耗时。
@Overridepublic void excelImport(String authorization, ExcelImportDTO excelImportDTO) { // 验证签名 TokenUtils.tokenSignatureVerify(authorization); ExcelImportBusinessType businessType = ExcelImportBusinessType.getByCode(excelImportDTO.getBusinessType()); try { long beginTime = System.currentTimeMillis(); // 账号导入 if (ExcelImportBusinessType.PS_ACCOUNT.getCode().equals(excelImportDTO.getBusinessType())) { // easyexcel的read方法进行数据读取 EasyExcelFactory.read(excelImportDTO.getFile().getInputStream(), PsTrainerAccountDTO.class, trainerAccountImportHandler) .sheet() .doRead(); } else { throw new ServerException("businessType is error..."); } double time = (System.currentTimeMillis() - beginTime) / 1000.00; log.info("导入{}文件耗时:{}秒", businessType.getDesc(), time); } catch (IOException e) { log.error("导入{}文件异常", businessType.getDesc(), e); }}4.2 PsTrainerAccountImportHandler 关键处理片段
PsTrainerAccountImportHandler 的核心策略是:累计到 BATCH_COUNT 后切分为 1000 一组,并发执行 saveBatch。
@Slf4j@Componentpublic class PsTrainerAccountImportHandler implements ReadListener<PsTrainerAccountDTO> { // 成功数据 private final List<PsTrainerAccountDTO> successList = new ArrayList<>(); // 单次处理条数 private static final int BATCH_COUNT = 100000; @Resource private PsTrainerAccountService trainerAccountService; /** * 读取表格内容,每一条数据解析都会来调用 * @param psAccount one row value. It is same as {@link AnalysisContext#readRowHolder()} * @param analysisContext analysis context */ @Override public void invoke(PsTrainerAccountDTO psAccount, AnalysisContext analysisContext) { if (psAccount.getMemoryTagId() == null || StringUtils.isBlank(psAccount.getMemoryTagHash()) || psAccount.getMemoryTagType() == null) { log.error("读取错误的行数据:{}", psAccount); return; } successList.add(psAccount); if (successList.size() >= BATCH_COUNT) { log.info("读取数据量:{}条", successList.size()); List<CompletableFuture<Boolean>> futures = new ArrayList<>(); List<List<PsTrainerAccountDTO>> lists = ListUtil.split(successList, 1000); for (List<PsTrainerAccountDTO> list : lists) { // 异步处理数据 CompletableFuture<Boolean> future = CompletableFuture.supplyAsync(() -> { List<PsTrainerAccount> psTrainerAccounts = PsAccountConverter.INSTANCE.psAccountDTOListToPsAccountList(list); return trainerAccountService.saveBatch(psTrainerAccounts); }, ThreadPoolUtils.EXECUTOR_SERVICE); futures.add(future); } // 等待所有异步任务完成(此处会阻塞,直到所有线程处理完成) CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join(); // 清空集合,释放资源 successList.clear(); lists.clear(); } } /** * 所有数据读取完成之后调用 */ @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { // 读取剩余数据 if (CollectionUtils.isNotEmpty(successList)) { log.info("最后读取数据量:{}条", successList.size()); List<PsTrainerAccount> psTrainerAccounts = PsAccountConverter.INSTANCE.psAccountDTOListToPsAccountList(successList); trainerAccountService.saveBatch(psTrainerAccounts); successList.clear(); } log.info("数据导入完成,总共导入{}行...",analysisContext.readRowHolder().getRowIndex()); } /** * 读取标题,里面实现在读完标题后会回调 */ @Override public void invokeHead(Map<Integer, ReadCellData<?>> headMap, AnalysisContext context) { ReadListener.super.invokeHead(headMap, context); log.info("标题:{}",headMap.values().stream().map(CellData::getStringValue).collect(Collectors.toList())); } /** * 转换异常 获取其他异常下会调用本接口。抛出异常则停止读取。如果这里不抛出异常则 继续读取下一行 */ @Override public void onException(Exception exception, AnalysisContext context) throws Exception { ReadListener.super.onException(exception, context); log.error("数据读取异常,正在读取的行数:{}行",context.readRowHolder(),exception); }}4.3 当前项目参数
• 单次累计阈值: BATCH_COUNT = 100000• 每批异步入库分片: 1000• 并发执行器: ThreadPoolUtils.EXECUTOR_SERVICE
五、分片并行流程图
六、性能实测结果
本次数据来自 PsTrainerAccountImportHandler 链路实测:
折算吞吐约为 2 万行/秒。说明:该结果会受索引数量、磁盘 IO、数据库负载和事务配置影响。
关注公众号「SCper技术」,获取更多技术干货!
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

