老板扔来3000行Excel要明天交?我用Python10分钟搞定,同事看傻了
- 2026-07-15 20:32:25




16个Python脚本让Excel自己动起来,从此告别加班!
老板的“灵魂拷问”
某天老板突然丢过来一个Excel表格,拍着桌子说:“小李,这个Excel里几千行数据,你给我整理一下,明天早上要用!”我当时差点没把手里的奶茶喷出来,心想:几千行?手动改?我这怕不是得改秃了! 于是,我默默打开了我的Python神器——pandas和openpyxl,不到十分钟,任务搞定,潇洒下班。老板看着整齐的数据,眼里透着光,转头又给我派了个新活儿……既然自动化办公这么香,那今天就给大家分享16个超实用的Excel操作脚本,让你轻松搞定表格数据处理,成为职场效率王!💡
一、数据读写篇:Excel就像ATM,想取就取,想存就存
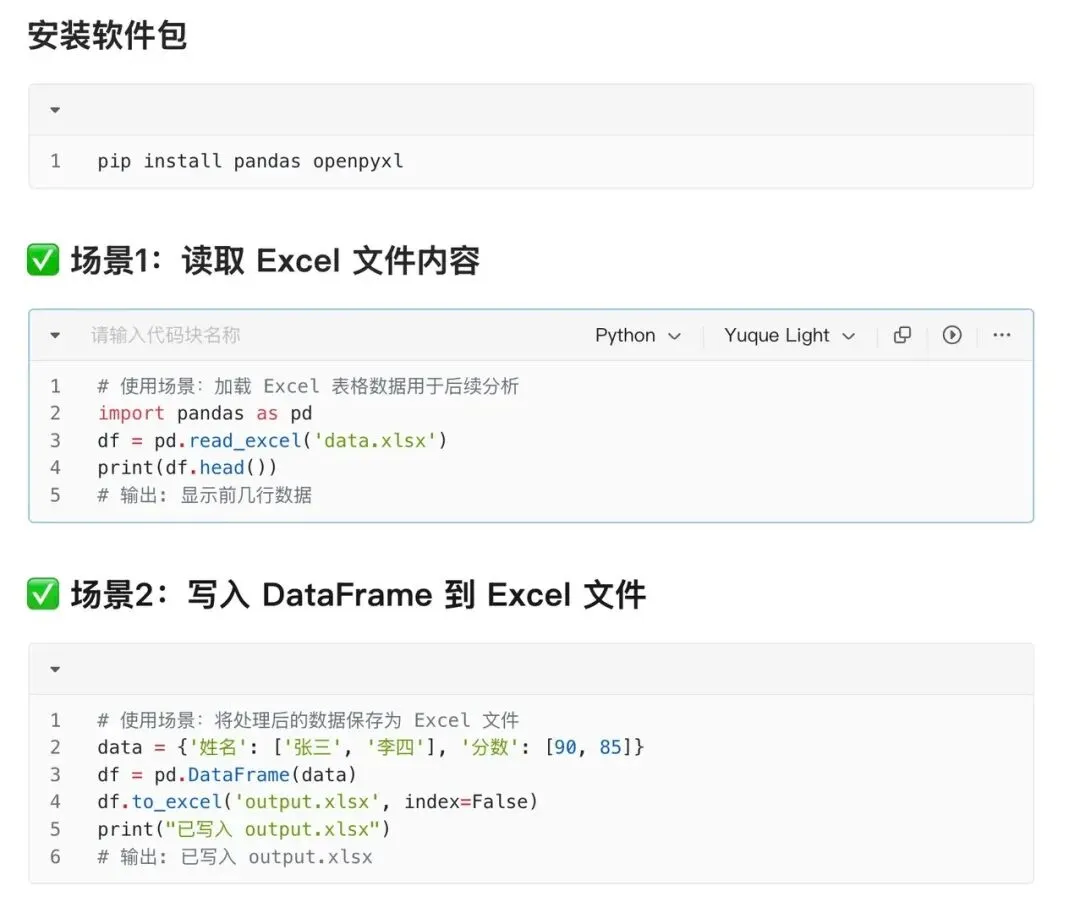
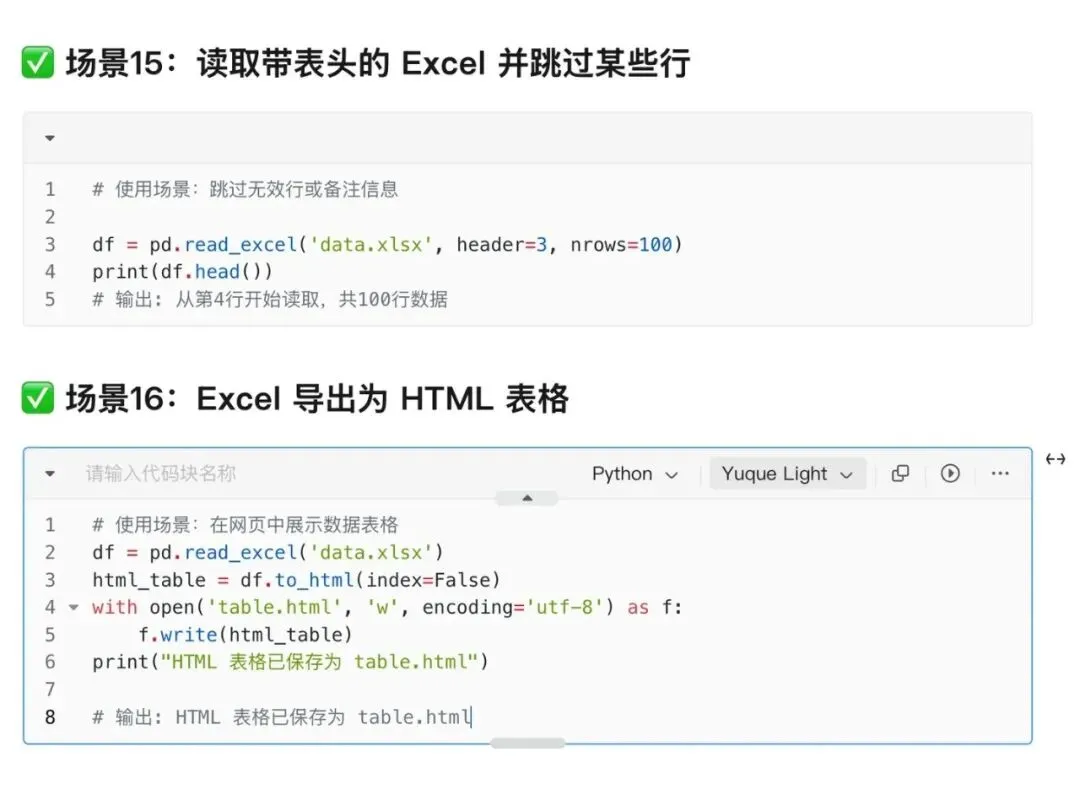
1. 读取Excel文件:打开数据宝库
import pandas as pddf = pd.read_excel("data.xlsx")print(df.head()) # 偷看前5行数据用途:一键打开Excel文件,读取数据,默认获取第一个Sheet里的数据。再也不用手动复制粘贴了!
2. 写入Excel文件:把处理结果存回去
df.to_excel("output.xlsx", index=False)用途:把DataFrame格式数据保存为Excel文件,index=False表示不保存索引。老板要什么格式,就给什么格式!
3. 读取多个Sheet:一网打尽所有工作表
df_dict = pd.read_excel("data.xlsx", sheet_name=None)print(df_dict.keys()) # 查看所有Sheet名称for key in df_dict: print(df_dict[key]) # 遍历每个Sheet的数据用途:一次性读取多个Sheet,返回字典格式,这个字典value对应了一个DataFrame格式的数据。再也不用一个个切换Sheet了!
二、数据清洗与转换篇:把“脏数据”变成“香饽饽”
4. 选取特定列:只要我想要的
selected_columns = df[["姓名", "工资"]]print(selected_columns.head())用途:提取某些关键列,方便分析。其他无关列?直接丢进垃圾桶!
5. 过滤数据:按条件筛选
high_salary = df[df["工资"] > 10000] # 筛选工资大于1万的员工print(high_salary)用途:数据筛选,比Excel的筛选功能还强大。工资太低的?直接过滤掉!
6. 处理空值:让数据完整无缺
df.fillna("缺失值", inplace=True) # 用"缺失值"填充空值df.dropna(inplace=True) # 或者直接删除含空值的行用途:处理空白单元格,防止数据异常。空值?要么填上,要么滚蛋!
7. 添加新列:计算新指标
df["奖金"] = df["工资"] * 0.1# 工资的10%作为奖金用途:快速计算并添加新列。老板突然要个新指标?分分钟搞定!
8. 修改列名:让表格更专业
df.rename(columns={"姓名": "员工姓名"}, inplace=True)用途:更改列名,增强可读性。列名太土?一键改名!
9. 按条件修改数据:批量修改更高效
df.loc[df["工资"] < 5000, "工资"] = 5000# 最低工资设为5000用途:把工资列中值小于5000的都改成5000,批量修改数据,比手动改省事多了。工资太低?直接提升!
10. 排序数据:让数据井然有序
df.sort_values(by="工资", ascending=False, inplace=True)用途:按工资降序排列。ascending=False是降序,ascending=True是升序。数据乱七八糟?一键排序!
三、多文件合并与拆分篇:大文件拆得开,小文件合得拢
11. 合并多个Excel文件:把分散的数据整合起来
import osfiles = [f for f in os.listdir('.') if f.endswith('.xlsx')]combined_df = pd.DataFrame()for file in files: df = pd.read_excel(file) combined_df = pd.concat([combined_df, df], ignore_index=True)combined_df.to_excel('combined.xlsx', index=False)用途:批量处理多个Excel文件时,合并是非常常见的需求。文件太多?一个脚本全部合并!
12. 拆分Excel文件:按条件拆分成多个文件
unique_values = df["部门"].unique()for value in unique_values: sub_df = df[df["部门"] == value] sub_df.to_excel(f'{value}.xlsx', index=False)用途:根据指定列的唯一值将Excel文件拆分成多个文件。比如按部门拆分,各部门独立查看自己的数据。
四、分组统计与排序篇:数据分析师的最爱
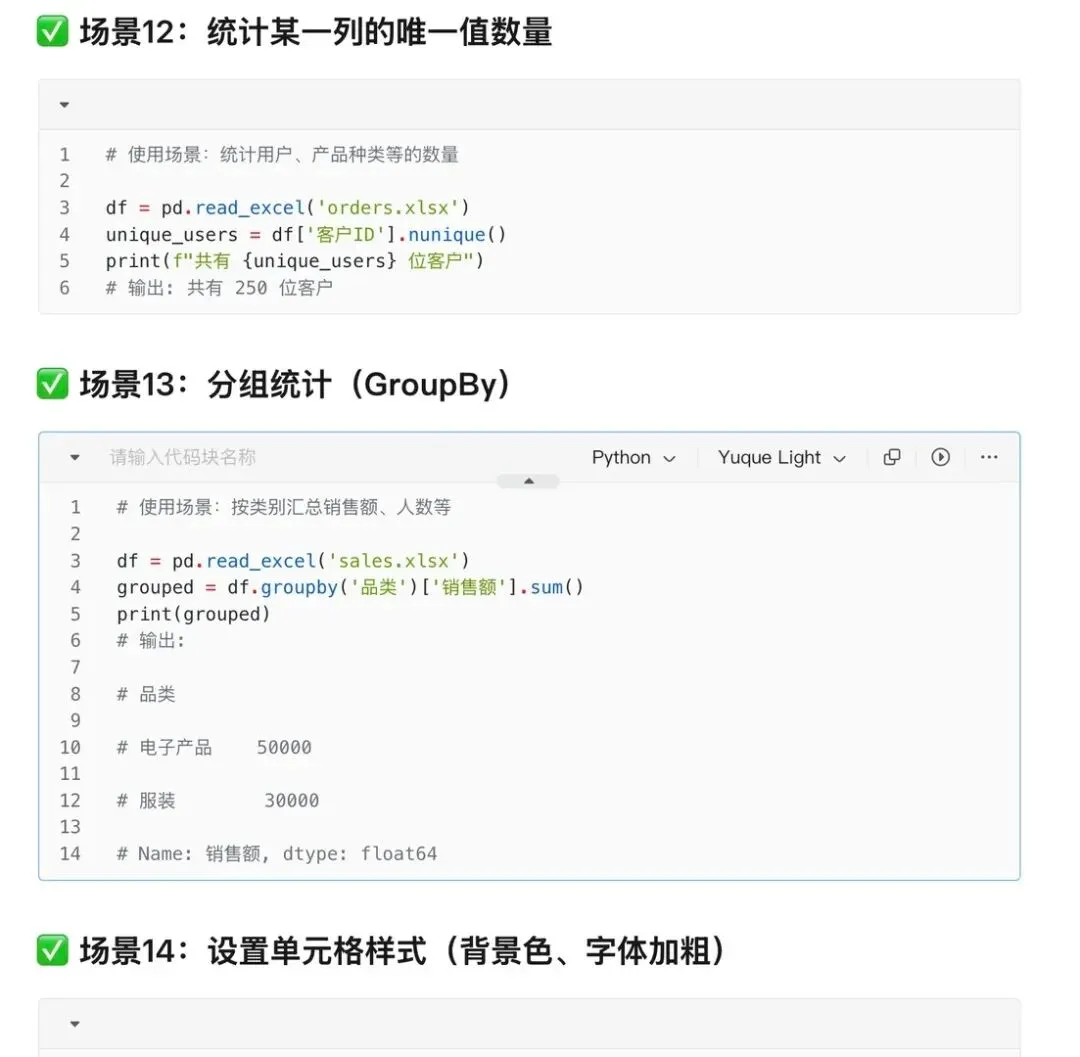
13. 计算数据统计值:一键获取各种统计指标
print("平均值:", df["工资"].mean())print("总和:", df["工资"].sum())print("最大值:", df["工资"].max())print("最小值:", df["工资"].min())print("中位数:", df["工资"].median())print("标准差:", df["工资"].std())print("方差:", df["工资"].var())print("计数:", df["工资"].count())print("描述性统计:", df["工资"].describe())用途:数据统计,计算平均值、最大值等。老板突然要各种统计指标?分分钟搞定!
14. 合并两个表格:类似Excel的VLOOKUP
df_new = pd.merge(df1, df2, on="员工ID", how="left")用途:基于“员工ID”这个列,把df2的数据合并到df1,并使用left join方式来匹配数据。VLOOKUP太慢?用Python更快!
15. 透视表:数据分析神器
pivot = df.pivot_table(values="工资", index="部门", aggfunc="sum")pivot.to_excel("pivot_table.xlsx")用途:数据透视表,返回DataFrame格式,轻松分析数据。按部门统计工资总和?一个透视表搞定!
五、样式设置与导出篇:让Excel表格美美哒
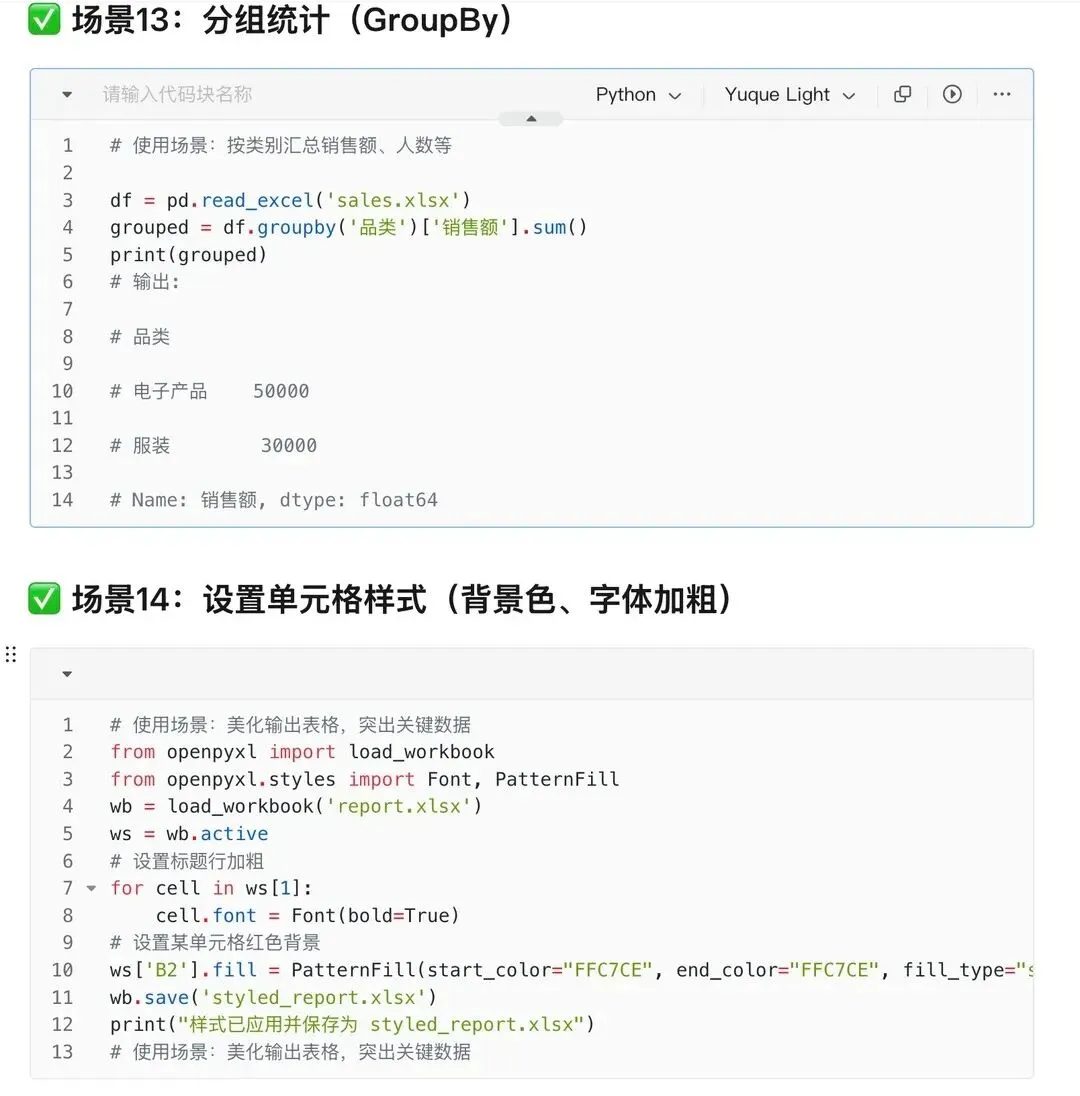
16. 生成Excel带格式:让表格更专业
from openpyxl import Workbookfrom openpyxl.styles import Fontwb = Workbook()ws = wb.activews["A1"] = "姓名"ws["A1"].font = Font(bold=True) # 加粗wb.save("styled.xlsx")用途:添加格式,提升Excel美观度。表格太丑?一键美化!
从此告别加班,Python让你成为职场效率王!
有了这16个Python脚本,Excel处理就像开了挂,再也不用手动复制粘贴、筛选排序、合并拆分了。老板再丢过来几千行数据,你只需要泡杯咖啡,打开Python,十分钟搞定,然后潇洒下班!记住,工具用得好,下班走得早!💪
现在就开始打造你的Excel自动化工具箱吧,让Python成为你职场进阶的神器!
#软件测试 #自动化测试 #测试开发 #python #python处理excel #python自动化办公














请在微信客户端打开


