【Python实战】一键提取Excel排班表夜班排休|自动合并连续日期成区间,人事/行政直接复制复用
- 2026-07-21 02:50:35
做学校行政、单位人事、后勤排班的小伙伴,每月是不是都被「排班表统计排休」这件事耗掉大把时间?
✅ 手里一份标准Excel排班表,要挨个核对每位老师/员工的「夜班」日期,手动摘抄到新表格;
✅ 还要把零散的夜班日期,比如「4、8、9、10」,手动整理成「4日、8-10日」的区间格式,眼睛盯久了酸涩不说,还容易漏数、错合并连续日期;
✅ 几十人的排班表,手动统计一遍至少半小时,但凡排班表微调,又要重新返工,机械重复还没技术含量,纯纯浪费时间!
今天分享的这套Python代码,完美贴合你的工作流程:先精准匹配你的Excel排班表样式 → 再读取表格数据 → 自动统计夜班日期 → 智能格式化 → 生成汇总表,一站式解决所有问题!全程10秒搞定几十人的排休统计,准确率100%,代码注释拉满、逐段精讲,零基础也能复制即用,改个文件名就能运行,从此彻底告别手动统计排班表的苦差事!
一、 需求:你的Excel排班表 假如是下面的样子:
排班表.xlsx:
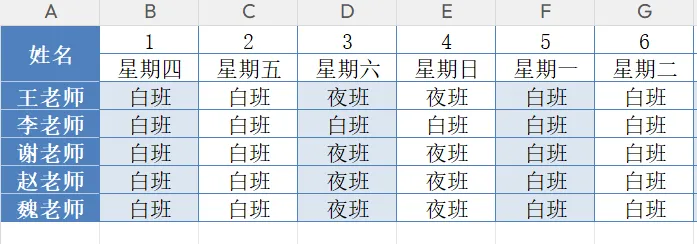
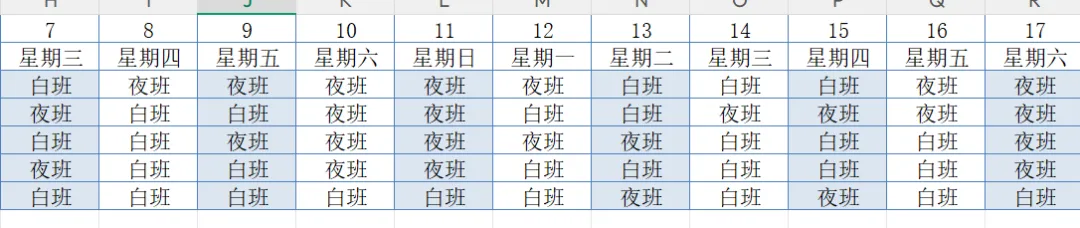
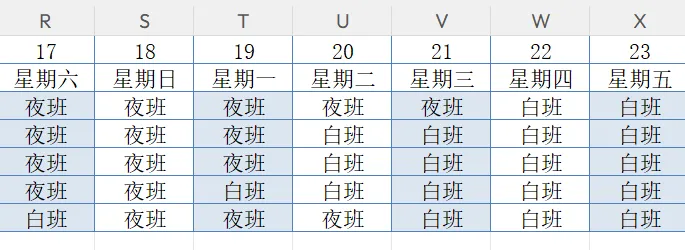
我们想要实现的最终效果:

二、 本次实战核心说明
✔ 核心功能
「读取标准排班表Excel」→「遍历每一行每一列」→「筛选标记为「夜」的日期」→「智能合并连续日期为区间」→「生成排休汇总Excel」
✔ 用到的Python库
仅1个核心刚需库:pandas — Python处理Excel表格的天花板,办公自动化必备,无任何冷门库,pip一键安装即可。
✔ 零基础友好度
全程只需修改2个文件名,其余代码无需改动,复制粘贴就能运行,无任何编程基础也能上手。
三、 逐段完整代码 + 逐行详细精讲(严格按「匹配样式→读取数据→统计筛选→格式化→保存结果」)
整体逻辑顺序:匹配表格样式 → 导入库 → 定义日期格式化函数 → 读取Excel数据 → 逐行统计夜班日期 → 格式化日期 → 生成结果保存Excel,全程逻辑连贯,和咱们手动统计的思路完全一致!
▶▶ 第一段:导入核心依赖库
import pandas as pd
✅ 代码讲解
pandas这一个库,它能一站式完成「Excel读取、数据遍历、数据筛选、结果保存」所有操作,是Python办公自动化处理Excel的万能工具,没有之一。
▶▶ 第二段:定义【核心工具函数】format_rest_days — 零散日期转连续区间(统计排休的核心)
defformat_rest_days(days_list):
"""
专用格式化函数:将提取的零散夜班日期列表,转为规范的区间字符串
示例:传入 [4,8,9,10] → 返回 "4日、8-10日"
"""
# 如果没有夜班日期,返回空字符串
ifnot days_list:
return""
# 对日期排序,防止日期乱序导致连续区间合并失败(比如[10,8,9])
days_list.sort()
result_strs = [] # 存储拆分好的区间字符串,如["4日", "8-10日"]
start = days_list[0] # 初始化连续区间的起始日期
end = days_list[0] # 初始化连续区间的结束日期
# 遍历排序后的日期,从第二个开始判断是否连续
for i in range(1, len(days_list)):
curr_day = days_list[i]
# 判断当前日期是否和上一个日期连续(比如9是8+1,属于连续)
if curr_day == end + 1:
end = curr_day # 连续则更新区间结束值
else:
# 不连续则闭合上一个区间,存入结果列表
if start == end:
# 区间只有单个日期的情况,如:4日
result_strs.append(f"{start}日")
else:
# 区间是连续多个日期的情况,如:8-10日
result_strs.append(f"{start}-{end}日")
# 重新初始化新的区间起始和结束值
start = curr_day
end = curr_day
# 处理循环结束后,最后一个未闭合的区间(必做,否则漏最后一段)
if start == end:
result_strs.append(f"{start}日")
else:
result_strs.append(f"{start}-{end}日")
# 用顿号拼接所有区间,生成最终的排休字符串
return"、".join(result_strs)
✅ 核心细节讲解
这个函数是本次统计的「灵魂」,专门解决办公场景中「零散数字合并连续区间」的需求,除了排班表,考勤统计、值班汇总都能复用; 必须执行 days_list.sort():因为提取的日期可能是乱序的(比如先提取到10号,再提取到8号),排序后才能正确识别连续日期;循环结束后一定要处理最后一个区间:循环中只有「遇到不连续日期才闭合区间」,最后一段连续日期不会被处理,这是避免漏数据的关键。
▶▶ 第三段:定义【核心业务函数】process_excel — 完整实现「读取Excel→统计夜班→生成结果」全流程(重中之重)
本段代码严格按照「读取Excel数据 → 遍历每行数据 → 逐列筛选夜班日期 → 统计整理 → 保存结果」的顺序编写,和我们手动统计的步骤完全一致,逻辑清晰,易懂易改!
defprocess_excel(input_file, output_file):
# ========== 第一步:读取Excel排班表数据(严格匹配前面的表格样式) ==========
# header=0 :指定Excel的【第一行】作为列名,对应我们的「姓名、1、2...30」
# skiprows=[1] :强制跳过Excel的【第二行】,因为第二行是星期几的备注,无数据
df = pd.read_excel(input_file, header=0, skiprows=[1])
# ========== 致命避坑!统一列名格式,保证日期列能被正确匹配 ==========
# 原因:Excel里的1、2、3会被pandas默认读取为【整数】,我们遍历的是字符串格式的日期
# 处理后:所有列名统一转为字符串,比如 1 → '1',完美匹配后续遍历的列名
df.columns = df.columns.astype(str)
# 初始化空列表,存储最终的排休结果,每个元素是一个字典:{'姓名':'XXX', '排休':'XXX'}
final_results = []
# ========== 第二步:开始逐行遍历Excel数据 → 统计每位人员的夜班日期 ==========
# df.iterrows() :遍历Excel的每一行,index是行号,row是当前行的所有数据
for index, row in df.iterrows():
# 提取当前行的姓名,列名固定为「姓名」,兜底处理防止无姓名的情况
staff_name = row.get('姓名', f"未知人员{index+1}")
# 初始化空列表,存储当前人员的所有夜班日期(数字格式)
night_rest_days = []
# ========== 第三步:逐列遍历1-30号日期 → 筛选标记为「夜班」的日期 ==========
# 遍历1到30号,对应Excel里的30个日期列
for day_num in range(1, 31):
day_col_name = str(day_num) # 列名转为字符串,和前面统一的列名格式匹配
# 提取当前日期的值班状态(白班/夜班)
work_status = row.get(day_col_name)
# 核心筛选条件:如果当前日期的状态是「夜班」,就把这个日期存入列表
if work_status == '夜班':
night_rest_days.append(day_num)
# ========== 第四步:格式化夜班日期 → 存入最终结果 ==========
# 如果当前人员有夜班日期,就格式化后存入结果列表
if night_rest_days:
final_results.append({
'姓名': staff_name,
'排休': format_rest_days(night_rest_days)
})
# ========== 第五步:生成结果Excel并保存 ==========
# 将结果列表转为pandas的表格格式
result_excel = pd.DataFrame(final_results)
# to_excel保存文件,index=False :不生成多余的行号,表格干净整洁,直接能用
result_excel.to_excel(output_file, index=False)
# 控制台打印结果,方便即时核对,不用打开Excel
print(f" 排班表处理完成!结果已保存至:{output_file}")
print("-" * 40)
print("本次排休统计结果预览:")
print(result_excel)
✅ 逐步骤重点讲解(新手零踩坑,必看)
读取Excel的2个关键参数:完全匹配我们前面的表格样式,缺一不可 header=0:刚好对应表格第一行的「姓名+1-30号」表头,pandas会自动把这一行识别为列名;skiprows=[1]:刚好跳过表格第二行的星期备注,避免备注行干扰数据读取,这是匹配表格样式的核心配置。列名格式统一: df.columns = df.columns.astype(str)是90%新手会踩的坑!如果不加这行,Excel里的数字列名(1、2)是整数,我们遍历的是字符串,会导致「找不到列」,读取不到值班状态,加了之后完美解决。双层遍历逻辑:和手动统计完全一样,外层遍历每个人 → 内层遍历这个人的1-30号值班状态,逻辑简单易懂,就算要修改筛选条件(比如筛选「休」),也能轻松找到位置。 筛选条件灵活修改:如果你的排班表中,夜班标记不是「夜班」,而是「夜」「晚」「晚班」,只需要修改 if work_status == '夜班'这一行的内容即可,比如改成if work_status == '夜'。
▶▶ 第四段:程序执行入口 + 异常容错处理(零基础友好,只需改2个文件名)
# --- 程序运行入口,无需修改逻辑,只需改文件名 ---
if __name__ == "__main__":
# 只需修改这两个文件名!!!其他代码一行都不用动
# 你的原始排班表文件名(和代码放在同一个文件夹)
input_file_name = '排班表.xlsx'
# 生成的排休汇总表文件名(自定义)
output_file_name = '夜班结果.xlsx'
# 异常处理:防止文件找不到、格式错误等问题,给出清晰的报错提示
try:
# 调用核心处理函数,执行所有操作
process_excel(input_file_name, output_file_name)
except FileNotFoundError:
print(f" 错误:未找到文件「{input_file_name}」,请检查文件名是否正确、是否和代码同文件夹!")
except Exception as e:
print(f" 运行出错,错误原因:{str(e)}")
✅ 代码讲解
if __name__ == "__main__":Python的标准运行入口,意思是「当这个文件被直接运行时,才执行下面的代码」,规范写法,不影响运行;零基础友好核心:你只需要修改 input_file_name和output_file_name这两个变量,改成自己的文件名即可,其余代码无需任何改动;异常处理:加入了报错提示,如果文件找不到、Excel格式不对,会给出清晰的文字提示,新手也能轻松排查问题,不会出现一堆看不懂的代码报错。
四、 零基础【3步傻瓜式使用教程】(不用懂代码,1分钟上手运行)
✔ 第一步:安装依赖库(仅需一次,永久使用)
打开电脑的「命令提示符(CMD)」或「终端」,复制粘贴下面的代码,回车安装,10秒完成:
pip install pandas openpyxl
补充:安装
openpyxl是为了让pandas支持读写新版Excel(.xlsx格式),必装,无它会报错!
✔ 第二步:准备Excel排班表(严格匹配样式,零修改)
将你的排班表文件命名为 排班表.xlsx,和Python代码放在同一个文件夹里;确认表格样式和我们前面说明的一致:第一行是姓名+1-30号,第二行是星期几,单元格值班状态是「白/夜/休」。
✔ 第三步:运行代码,坐等结果
双击运行Python代码,控制台会打印处理完成的提示和排休结果,同时在同一文件夹生成 排休结果.xlsx,打开就是干净的「姓名+排休区间」汇总表,直接复制粘贴到工作报表即可!
五、 全部源代码完整可复制(直接粘贴运行,零修改适配)
import pandas as pd
defformat_rest_days(days_list):
"""
将数字列表转换为区间字符串,例如 [4, 8, 9, 10] -> "4日、8-10日"
"""
ifnot days_list:
return""
days_list.sort()
result_strs = []
start = days_list[0]
end = days_list[0]
for i in range(1, len(days_list)):
curr = days_list[i]
if curr == end + 1:
end = curr
else:
if start == end:
result_strs.append(f"{start}日")
else:
result_strs.append(f"{start}-{end}日")
start = curr
end = curr
# 处理最后一个区间
if start == end:
result_strs.append(f"{start}日")
else:
result_strs.append(f"{start}-{end}日")
return"、".join(result_strs)
defprocess_excel(input_file, output_file):
# 1. 读取 Excel 文件,匹配表格样式:header=0用第一行做列名,skiprows=[1]跳过第二行星期备注
df = pd.read_excel(input_file, header=0, skiprows=[1])
# 统一列名为字符串,避免整数列名匹配失败
df.columns = df.columns.astype(str)
results = []
# 2. 遍历每一行(每位老师/员工),开始统计
for index, row in df.iterrows():
name = row.get('姓名', f"未知老师{index}")
rest_days = []
# 3. 遍历1-30号日期列,筛选夜班状态
for day in range(1, 31):
day_col = str(day)
status = row.get(day_col)
if status == '夜班':
rest_days.append(day)
# 4. 格式化日期并存入结果
if rest_days:
results.append({
'姓名': name,
'夜班': format_rest_days(rest_days)
})
# 5. 生成结果并保存Excel
result_df = pd.DataFrame(results)
result_df.to_excel(output_file, index=False)
print(f" 处理完成!结果已保存为: {output_file}")
print("-" * 30)
print(result_df)
# --- 执行部分 ---
if __name__ == "__main__":
# 只需修改这两个文件名即可
input_excel_name = '排班表.xlsx'
output_excel_name = '夜班结果.xlsx'
try:
process_excel(input_excel_name, output_excel_name)
except FileNotFoundError:
print(f" 错误:找不到文件 '{input_excel_name}',请确认文件名是否正确。")
except Exception as e:
print(f" 发生错误:{e}")
人事、行政的工作价值,从来都不是在重复的表格统计里消耗自己,而是在更有意义的统筹、协调、管理上创造价值。
请在微信客户端打开
这份Python代码,看似只是解决了「排班表统计排休」这一个小问题,但本质是帮你把「机械重复的人工劳动」交给代码,把节省下来的时间和精力,留给更重要的工作。而且代码里的「日期区间合并函数」「Excel遍历筛选模板」,都是可以无限复用的办公神器,以后遇到任何类似的表格统计,都能直接套用。
希望这份代码,能让你彻底告别排班表的手动统计,让办公效率翻倍,也能让你感受到Python办公自动化的魅力——它不是程序员的专属技能,而是每一位职场人都能掌握的「减负神器」!
#Python办公自动化 #Excel数据处理 #人事行政必备 #排班表统计 #零基础学Python #办公效率神器
🔮 获取和交流
需要源码和源数据的同学,关注+三连,回复 【排班】,自动获取!
加下面微信!也可以拉你进群交流学习,加群备注:IT小本本学习

为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Excel小技巧:IFS函数多条件判断,告别冗长嵌套
- 「图文教程」公众号文章简单3步,插入Word/PDF/Excel文档!
- Excel新增活动单元格!指定区域新增列,不连累下方表格!
- 时事热点 PPT | 若为热爱 便所向披靡:致敬 “马背上的县长” 贺娇龙
- 【Excel模板】2026年待办事项列表跟踪表 日历年度日程计划表 工作计划表 每日工作清单 to do list共9份【链接可直接下载】
- 如何将文献中复杂公式转换到word中
- 从单图到多图,PPT排版有序更有质感
- 徐汇一模语文卷word整理版
- 2026年国考调剂职位表excel下载
- 【含文档+PPT+源码】基于SpringBoot的校园反电信诈骗宣传系统的设计与实现
