职场人都懂,从文档、语音碎片到一份专业PPT,曾需要经历“提炼大纲→填充内容→设计版式→调整细节”的漫长流程。而AnyGen等AI平台的“一键生成PPT”功能,看似魔法,实则是工程化流程编排与机器学习模型的精妙协作。今天就来拆解其端到端生成的技术内核,揭秘背后的工作原理。
端到端生成的核心并非“一步到位”,而是将复杂任务拆解为标准化子流程,通过多智能体协作与误差优化,实现全链路自动化。其技术架构可分为“工程层流程编排”与“模型层智能优化”两大核心,二者协同完成从输入到输出的闭环。
一、工程层:流程编排的“指挥体系”
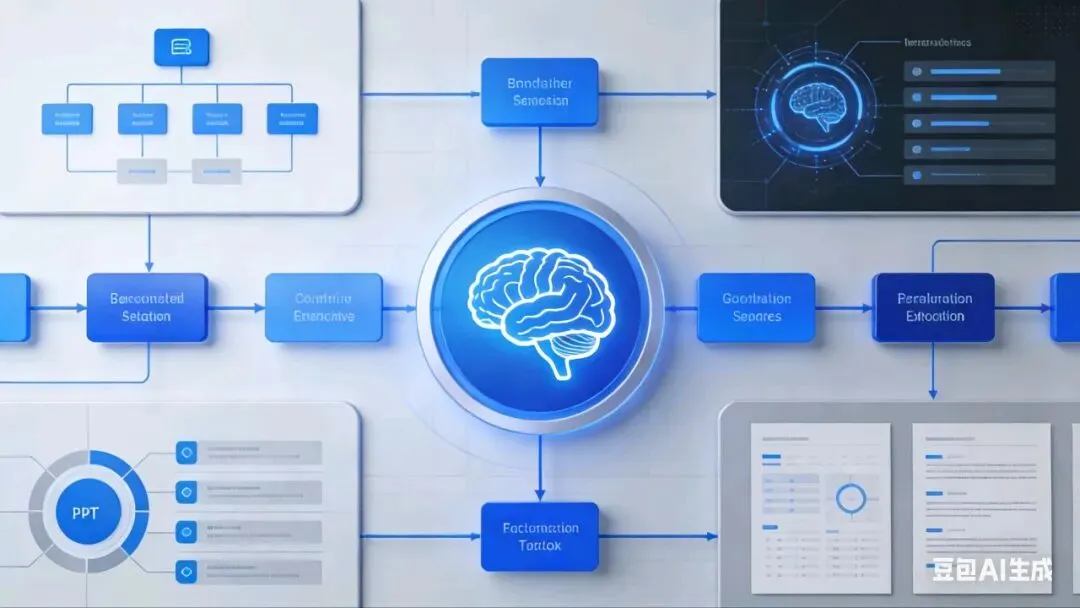
流程编排是生成效率的保障,核心是通过有向无环图(DAG) 与多智能体分工,让每个环节有序衔接。AnyGen的PPT生成流程拆解为4个关键步骤,由专属智能体各司其职:
1. 输入解析智能体:处理文档、语音、图片等多模态输入,通过LangChain等工具链完成文档分割、语音转写,提取标题、正文、数据、配图需求等结构化信息,避免原始信息杂乱导致的生成偏差。
2. 大纲生成智能体:基于结构化信息,按照“封面→目录→内容页→总结”的逻辑生成层级大纲,输出标准化JSON格式,为后续排版奠定基础。
3. 版式渲染智能体:读取用户上传的模板规则(字体、配色、布局),通过python-pptx等工具将内容映射到幻灯片,实现文本框、图表、图片的自适应排列,解决格式错乱问题 。
4. 优化导出智能体:校验元素对齐、格式一致性,支持断点续跑与异步执行,最终导出PPTX或PDF格式,确保生成结果“即拿即用”。
这套编排体系的关键是DAG调度机制,明确规定“输入解析完成后才启动大纲生成,大纲确定后再进行版式渲染”,避免任务并行冲突,同时支持异常恢复,某一步失败可从断点重启,无需从头执行 。
二、模型层:误差最小化的“智能大脑”
流程编排是“骨架”,机器学习模型才是实现“智能生成”的“大脑”。与全局误差优化不同,AnyGen采用分步骤局部误差优化,每个子任务都有专属模型与误差目标,通过反向传播持续迭代。
- 大纲生成:Transformer模型+交叉熵损失:采用编码器-解码器架构的Transformer模型,将输入文本转化为PPT大纲。以“生成大纲与人工标注的交叉熵损失”为优化目标,标题层级错误、内容遗漏都会升高损失值,通过反向传播更新模型权重,让大纲逻辑更贴合人工习惯。
- 版式布局:强化学习+奖励函数:版式设计是离散决策问题,AnyGen采用强化学习训练布局智能体,设计奖励函数R=版式合规分(对齐、留白)+用户满意度分(编辑次数少则加分),误差= -R,通过策略梯度反向传播优化参数,让布局更符合设计规范。
- 闭环迭代:用户反馈驱动增量优化:用户调整版式、替换图片等操作会被记录为反馈数据,计算“生成结果与用户最终版的误差”,通过小批量梯度下降对模型增量更新,实现“越用越懂用户”的效果。
三、好的流程编排:四大量化判定标准
并非能生成PPT就是“好编排”,优质系统需满足效率、稳定性、鲁棒性、可优化性四大指标:
- 效率:长文档生成耗时控制在分钟级,高并发场景下CPU/GPU资源占用合理;
- 稳定性:100+种复杂输入(长文档、多格式混合)的任务成功率≥95%,支持故障自动切换备用方案;
- 鲁棒性:同一输入多次生成的PPT结构一致性≥90%,面对空文档、乱码等极端输入不崩溃;
- 可优化性:用户反馈后,模型迭代生效时间≤24小时,模板规则复用率≥80%。
四、竞品技术对比:闭源与开源的路径差异
AnyGen作为商业产品,未公开技术细节,但同类工具的技术路径可作为参考:Presenton、PPTAgent等开源平台采用“本地LLM+模块化代码”,公开了模板提取算法与多智能体架构;Aspose.Slides AI则公开了LLM调用流程与API文档,支持自定义模型适配 。尽管实现方式不同,但核心都遵循“流程拆解+局部误差优化”的逻辑。
本质上,AnyGen类平台的PPT端到端生成,是工程化思维与AI模型的完美结合。流程编排解决“有序高效”的问题,机器学习解决“智能精准”的问题,二者共同将职场人从重复劳动中解放。随着多模态大模型与强化学习的发展,未来还将实现更精准的风格适配与更灵活的个性化生成,让PPT制作真正实现“输入即交付”。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
