让 AI Agent 帮你做 PPT,这件事有多难?
我前段时间写过一篇 AI PPT 工具的横评。当时我拆了一个技术细节:把 .pptx 文件后缀改成 .zip,解压,你会看到一堆 XML 文件。slide1.xml、presentation.xml、theme.xml。一个 PPTX,说到底,是几十个 XML 文件通过关系链串联起来的结构化文档。
用搬家来类比。PPTX 不是一张画布,是一个打包好的搬家箱,里面每个物品都有编号、位置说明和相互关系。PowerPoint 打开它时,就像一个严格的搬家工人,必须按清单核对每个物品的编号和位置,对不上就打不开。
所以 AI 做 PPT 不是在「画图」,而是在操作一个文件系统。
这就是为什么 AI 直接生成 PPTX 这么难。也是为什么,当我看到 OfficeCLI 这个项目的时候,觉得它走了一条很有意思的路。
01HTML 做演示很爽,但爽完呢?
先交代一个背景。
我自己这段时间的演示,很多都做 HTML 了。
Obsidian 作者最近提了一个观点,Markdown 是 AI 内容的谢林点。几乎同一时间,Claude Code 的作者 Tom Quisel 也发文说,自己主要的对外分享形式已经全面转向 HTML。两位前沿开发者的观点放在一起,勾勒出一套完整的 AI 内容架构:数据层用 Markdown,表现层用 HTML。
HTML 做演示确实有天然优势。交互灵活、样式丰富、支持折叠、动画、颜色编码,信息密度可以做到非常高。你用 Claude Artifacts 生成一个复杂的分析结果,用 HTML 呈现,交互体验远超任何静态格式。而且 HTML 可以直接部署到 S3、GitHub Pages、Vercel,用户打开链接就能看,不需要装任何软件。
但问题是,演示不等于 PPT。
PPT 的核心场景是演讲。一页一翻,节奏感,演讲者控制信息释放的时机。听众不需要交互,不需要滚动,不需要自己找重点。HTML 的交互性和灵活性,在这个场景下反而是噪音。你无法想象一个投资人在路演现场,对着你的 HTML 页面自己滚动翻页。
而且 PPT 还有一个 HTML 完全覆盖不了的场景:协作。你们公司的 PPT 模板,HTML 能复用吗?同事发来的 PPTX 文件,HTML 能打开编辑吗?老板在 PPT 上批注的修改意见,HTML 能兼容吗?
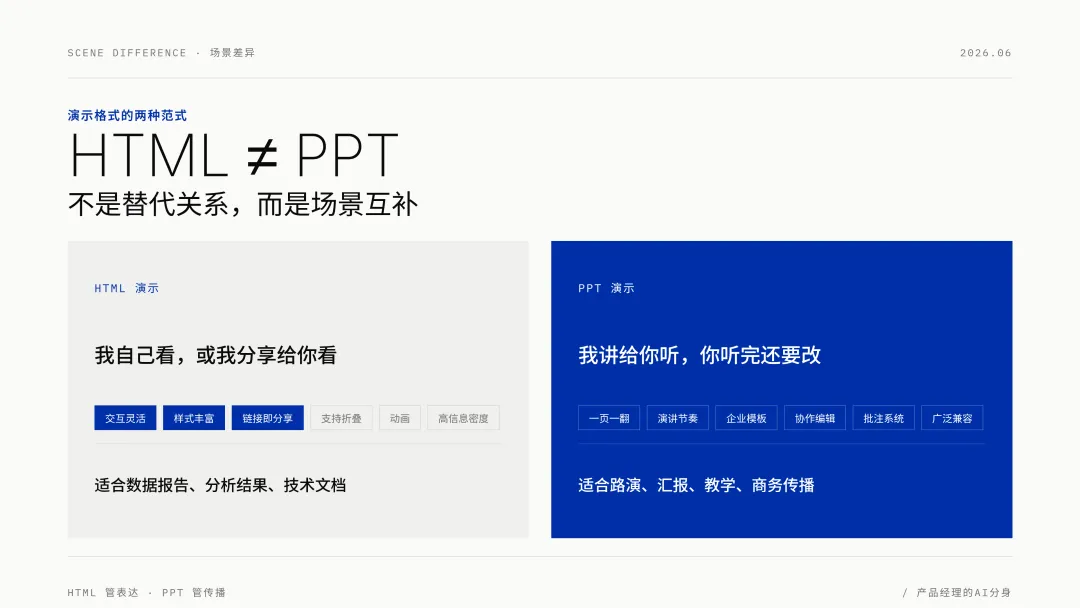
HTML 适合做「我自己看,或者我分享给你看」的演示。PPT 适合做「我讲给你听,你听完还要改」的演示。
两者不是替代关系,而是场景互补。 HTML 管表达,PPT 管传播。
02但 PPT 的管线,真的太难跑了
那为什么市面上 AI PPT 工具这么多,好用的没几个?
因为 PPT 的管线太长了。
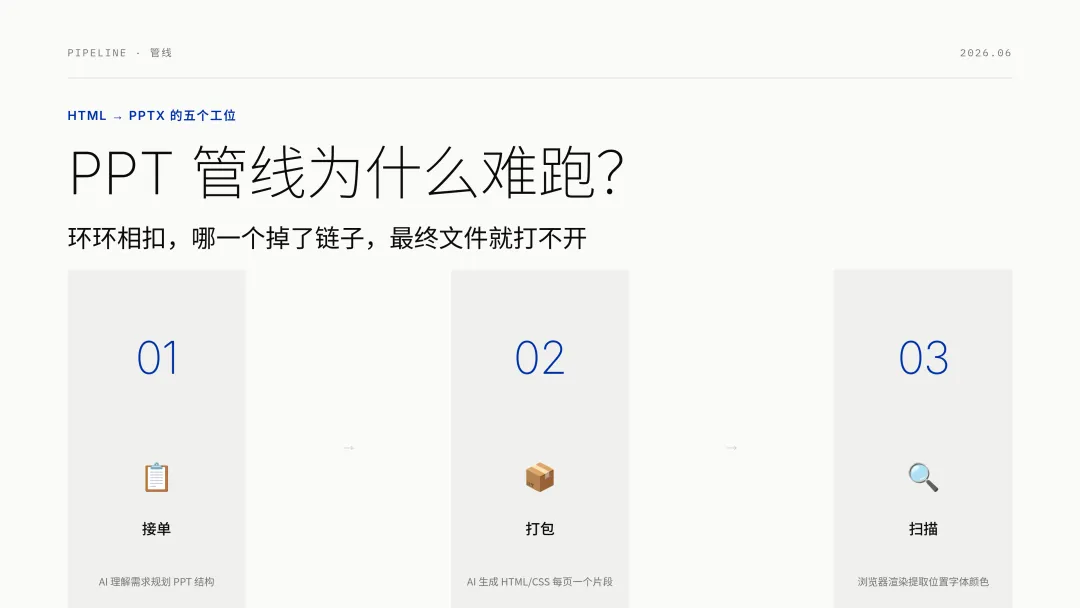
我当时把它拆成五个工位。第一个工位,接单,AI 理解你的需求,规划 PPT 结构。第二个工位,打包,AI 生成 HTML/CSS 代码,每页一个 HTML 片段。第三个工位,扫描,浏览器渲染,提取每个元素的精确位置、字体、颜色、大小。第四个工位,贴标签,CSS 属性映射到 DrawingML,PPTX 的内部图形语言。第五个工位,装车,输出 PPTX 文件。
五个环节,环环相扣。哪一个掉了链子,最终文件就可能打不开或排版错乱。
而且这里有个技术细节:CSS 里的 SVG 滤镜、复杂 mask,在 DrawingML 里压根没有对应实体。也就是说,即使你生成了一页完美的 HTML 幻灯片,转换到 PPTX 时,某些视觉效果一定会丢失。
国内跑得最好的,是我之前聊过的 Qoder Work。它做了三件事让我印象深刻:强制质检,HTML 渲染后自动检测元素溢出;模板沉淀,HTML 加 Markdown 设计描述双控;预览、修订、导出一体化的工作台。这几件事合在一起,能感觉到这个产品团队对「管线」这件事有比较深的理解,不是只把 PPT 生成当成一个功能点来做,而是当成一条需要精心维护的工程管线来对待。
但 Qoder Work 也有一个问题:它是绑定自家平台的。你要用它的管线,就得在它的工作台里操作。对普通用户来说,这没什么问题,甚至体验更好。但对开发者来说,对 Agent 来说,它缺乏普适性。你不能在自己的 Agent 工作流里调用 Qoder Work 的管线,你不能把它集成到自己的自动化流程里。
Kimi 走的是同一条 HTML 路线,但这半年没怎么大更新。豆包走的不是 HTML 管线,更像是直接操作 PPT 元素生成,但细节粗糙,版式经常错乱。
这就是现状:大家都在做,但管线的稳定性和普适性,始终是两条没有同时满足的维度。
03OfficeCLI 的思路:不修管线,拆掉重来
OfficeCLI 走了一条完全不同的路。
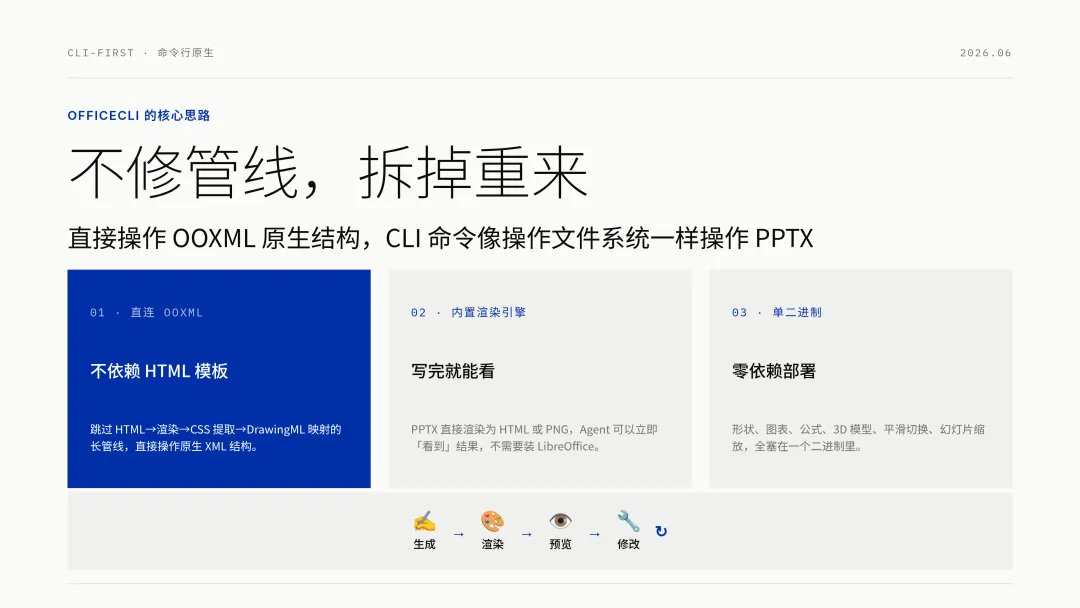
它不依赖 HTML 模板。它不搞 HTML→浏览器渲染→CSS 提取→DrawingML 映射这套长管线。它直接操作 OOXML 原生结构,用 CLI 命令的方式,像操作一个文件系统一样操作 PPTX。
比如你想在第一张幻灯片上加一个文本框,只需要:
officecli add deck.pptx '/slide[1]' --type shape \
--prop text="Revenue grew 25%" --prop x=2cm --prop y=5cm \
--prop font=Arial --prop size=24 --prop color=FFFFFF
对比 Python 的写法,import、Inches、Pt、slide_layouts,至少 10 行起步。差距一目了然。
但这不是最重要的。最重要的是,OfficeCLI 自带渲染能力。
它能把 PPTX 渲染成 HTML 或 PNG。这意味着 Agent 写完文档后可以立刻「看」到结果。它可以把渲染出的 PNG 喂给多模态模型,或者直接读 HTML 结构来判断排版是否合理。OfficeCLI 提供的是一个完整的「生成 → 预览 → 修改」反馈循环。
这个反馈循环的意义,怎么说都不过分。
之前我写过,Agent 做 PPT 最大的痛点是「能写不能看」。python-pptx 能生成 PPTX,但渲染是另一个世界的事。你要预览?那就得装 LibreOffice,或者让它去调微软的 Graph API。Agent 在服务器里跑得好好的,一到渲染环节就卡壳。它写出来的东西自己没法质检,交付质量完全靠运气。
OfficeCLI 把这个闭环补上了。Agent 写完 → 渲染成 PNG → 喂给多模态模型质检 → 发现排版问题 → 修改 → 再渲染 → 再质检。这个循环打通之后,Agent 做 PPT 的质量不再靠运气,而是靠迭代。
而且它的渲染引擎是从零开始写的,覆盖了形状、图表、公式、3D 模型、平滑切换、幻灯片缩放,单二进制里塞了这么多东西,说实话有点夸张。
04三层架构:Agent 不需要一上来就啃 XML
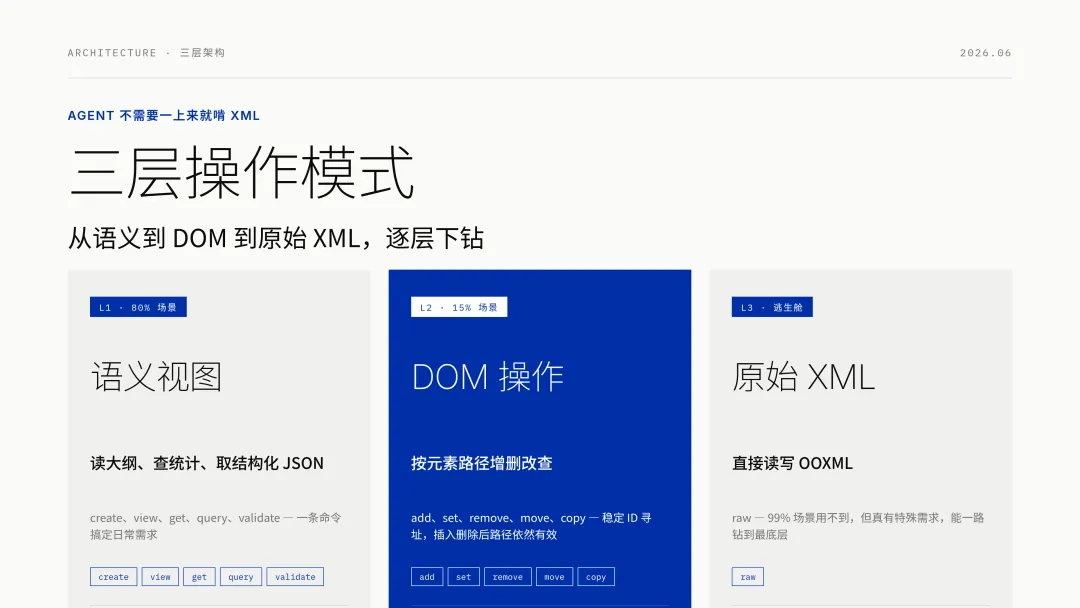
OfficeCLI 给 Agent 设计了三层操作模式,这个设计特别聪明。
L1 是语义视图,create、view、get、query、validate,读大纲、读统计、查问题、取结构化 JSON。Agent 用这一层就能搞定 80% 的日常需求。
L2 是 DOM 操作,add、set、remove、move、copy,按元素路径增删改查,相当于对文档的 DOM 直接动手。
L3 是原始 XML 访问,raw,真有特殊需求,可以直接读写 OOXML。这一层是逃生舱,99% 的场景用不到。
这个分层设计的精妙之处在于,Agent 不需要一上来就啃 XML。大多数时候一条命令就够了。但真遇到复杂场景,它也有能力一路钻到最底层。
而且它的元素定位用的是稳定 ID 寻址,不是单纯的索引。比如 /slide[1]/shape[@id=550950021],这种路径在插入删除操作后依然有效,对多步骤工作流特别友好。
回到我之前写过的那个类比。PPTX 是一个搬家箱,里面每个物品都有编号和位置说明。OfficeCLI 做的事情,就是给了 Agent 一张搬家箱的清单,告诉它「这个物品在第三层第二个抽屉里,编号 550950021」,然后 Agent 可以直接伸手去拿,不用先拆箱、再翻找、再打包。
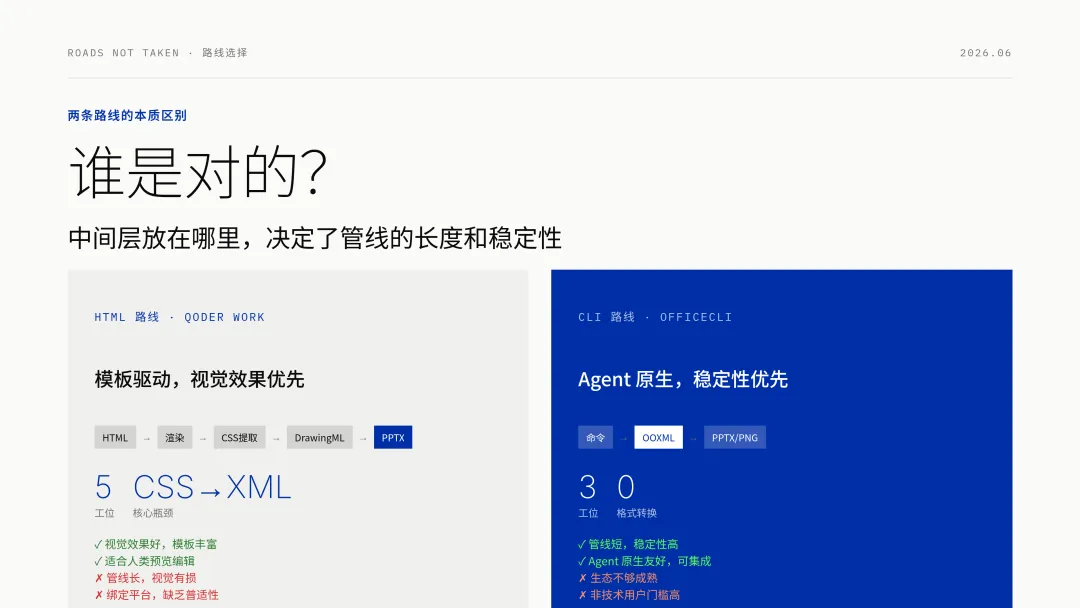
05HTML 路线和 CLI 路线,谁是对的?
把 Qoder Work 的 HTML 路线和 OfficeCLI 的 CLI 路线放在一起看,很有意思。
HTML 路线:生成 HTML 模板 → 浏览器渲染 → 提取位置 → 映射到 DrawingML → 输出 PPTX。管线长,但视觉效果好,适合「模板驱动」的场景。你有一个好看的模板,Agent 往里面填内容,最后导出 PPTX。
CLI 路线:命令行直接操作 OOXML 结构 → 内置引擎渲染预览 → 修改 → 再渲染。管线短,不走 HTML 中转,适合「内容驱动」的场景。你告诉 Agent 要什么内容,Agent 直接操作文档结构,所见即所得。
两条路线的本质区别在于,中间层放在哪里。
HTML 路线把中间层放在浏览器渲染这一步。优点是视觉效果好,缺点是多了一层转换,管线长,容易出问题。而且 CSS 到 DrawingML 的映射,有些视觉效果一定会丢失。
CLI 路线把中间层放在 OOXML 操作这一步。优点是不需要 CSS→DrawingML 的转换,管线短,稳定性高。缺点是牺牲了 HTML 的灵活性,你想做复杂的视觉效果,得用 OOXML 原生支持的方式。
哪个更好?说实话,没有标准答案。
但我觉得,CLI 路线有一个 HTML 路线目前做不到的优势:Agent 原生友好。
HTML 路线是为「人类在浏览器里预览」设计的,Agent 只是借用这个流程。CLI 路线是为「Agent 在命令行里操作」设计的,从第一天就是。Agent 不需要浏览器,不需要渲染引擎,不需要视觉比对,它只需要理解命令和结果。
而且 CLI 路线的管线更短,意味着更稳定。HTML 路线五个工位,CLI 路线三个工位。少了两个工位,就少了两个出错的可能性。
当然,OfficeCLI 也不是完美的。它目前只有 7.3K Stars,生态还远不如 python-pptx 成熟。它的渲染引擎虽然覆盖了很多功能,但跟 PowerPoint 原生渲染相比,肯定还有差距。它的 CLI 操作方式,对非技术用户来说,门槛还是太高了。
但话说回来,OfficeCLI 的定位从来不是「给人类用的 Office 工具」,而是「给 Agent 用的 Office 工具」。它从一开始就明确了一个核心设计原则:为 Agent 而不是为人类设计。几乎所有同类工具的默认假设都是「人来写代码调 API」,而 OfficeCLI 的默认假设是「Agent 来发命令、看结果」。
这个定位的差异,才是它最有意思的地方。
06最后说几句
回到一开始的问题:HTML 做演示很爽,但 PPT 才是 Agent 的终极考试。
HTML 管表达,PPT 管传播。HTML 适合「我自己看,或者我分享给你看」,PPT 适合「我讲给你听,你听完还要改」。两者不是替代关系,而是互补关系。AI 时代的内容架构,底层用 Markdown 做数据层,上层用 HTML 和 PPT 分别覆盖不同的表达场景。
但 PPT 的管线,确实是目前 AI 文档自动化里最难啃的骨头。
Qoder Work 的 HTML 路线,在管线稳定性上做到了国内最好。OfficeCLI 的 CLI 路线,在 Agent 原生友好上走了一条新路。一个在纵向优化「人类体验」,一个在横向探索「Agent 原生」。两条路各有道理,也各有局限。
我的判断是:AI 做 PPT 的未来,不是选 HTML 路线还是 CLI 路线,而是两者融合。 Agent 用 CLI 操作文档结构,在需要复杂视觉效果的时候,再调用 HTML 模板做补充。管线的稳定性和视觉的灵活性,最终会走到一起。
但在此之前,OfficeCLI 的方向,是一个值得认真对待的信号。
以后做 PPT,真的不该只剩 python-pptx 苦修了。

