前阵网上看到一个故事,但也有可能就是个段子。内容是这么写的:
上周去一家做汽车零部件的工厂,生产副总老赵跟我说了句话,我记到现在。"公司花了300万上了BI,报表自动生成,我不再做手工Excel了。但我还是不知道今天该干什么。"老赵每天早上7点半到办公室,三个系统的数据自动汇总到一张大屏上,数据实时刷新,报表看起来漂亮极了。但他说:"系统告诉了我昨天发生了什么,没告诉我今天该怎么办。"
也许这就是我决定动键盘写点东西的原因。
大家都叫我老吴,也有朋友叫我吴大维(不是那个DJ主持人啊,只是恰巧雷同而已)。
在自动化、制造业、数字化相关领域干了二十多年。这些年走了不少客户、合作伙伴和朋友的工厂,看到太多类似的场景——系统上了、数据有了、报表更快了,但管理层的决策方式感觉没有什么改变。花了上百万,结果只是把"看过去"这件事变快了。
这个系列我想起个名字叫《从数据到智能:工厂数字化转型》,这不是一本书,只是一个自己梳理和汇总的记录,把我这几年的见闻、思考、以及见过的坑都记录下来。从数据的源头开始,一截一截追踪,到最后这些数据如何才能变成管理层的决策——走完一个完整的链路。算是对自己大脑的一个整理的过程吧。
今天算是这个系列第一篇吧,就是记录一下自己的一些想法、感触,当做抛砖引玉吧。希望给大家带来一些思考或收获。
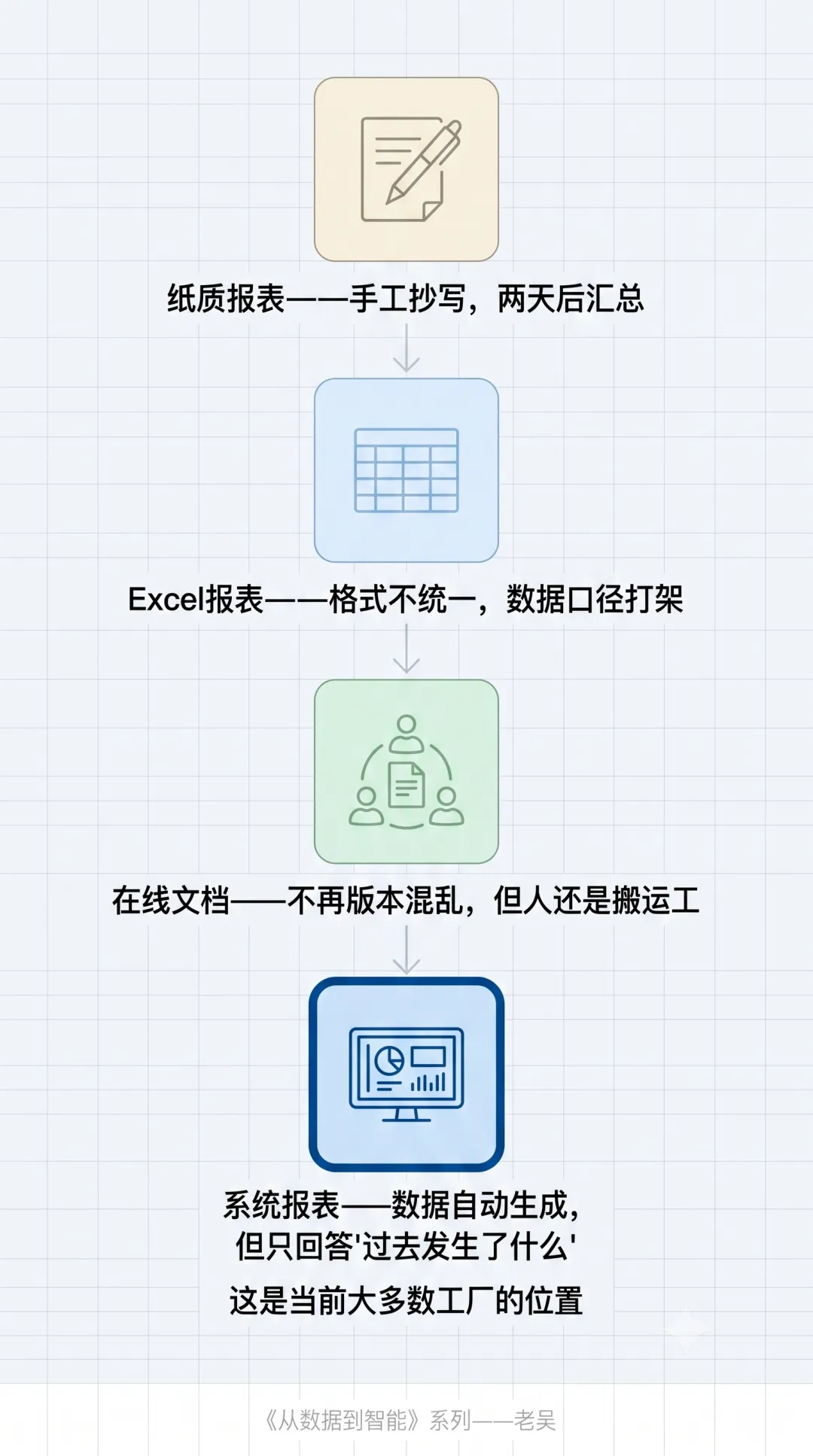
大多数工厂的报表体系,经历过四个阶段。
第一阶段:纸质报表。可能是由某位产线工程师下班前在一张表格上写当天的产量、废品数、设备异常。小组长把三张纸的数据加总,交给生产主管。生产主管再和其他产线合并,填进周报表。这个过程至少两天,一个数字抄错,后面全错。这是古法报表了。二十几年前,我刚大学毕业的时候,实习阶段就是这么干的。
第二阶段:Excel报表。过了第一阶段的远古时期。自从有了电脑之后,纸质变成了电子表格,公式自动计算,不用手动加总了。但新的问题来了——每个部门有自己的Excel模板,格式不统一,字段定义不一致。同样是"产量",生产部按实际产出算,仓储部按入库数算,财务部按销售出库算。三个数字凑不齐,开会先花二十分钟争论"到底是哪个数"。
第三阶段:在线文档。飞书、钉钉的在线文档让多人可以同时编辑,版本不会乱了。但本质上,数据还是要靠人从一个系统里复制,粘贴到另一个系统里。当然还有企业现在已经用上了飞书多维表格,本质上算是个数据库吧。但工具不一样了,人还是那个搬运工。
第四阶段:系统报表。ERP、MES、WMS自带报表功能,自动生成日报周报月报。这是目前"数字化程度不错"的工厂所在的阶段。
听起来,是一个线性进步的过程。每个阶段都比前一个更快、更准、更自动化。
但有一个问题被忽视了:不管报表的形式怎么变,它回答的核心问题始终没有变——记录"过去发生了什么"。
纸质报表告诉你昨天生产了多少。Excel告诉你上周废品率。在线文档告诉你上个月的OEE对比。系统报表告诉你上季度的能耗趋势。
它们都在告诉你"过去怎么了"。但没有一张报表告诉你:"明天会发生什么?"以及"我该为此做什么?"
这就好像你每年做一次体检,血压130/85、胆固醇5.8、体重78公斤——数据很详细。但报告只告诉你"你的数据在这里",不告诉你"这些数据意味着什么风险"、"你接下来该怎么做"。这样的体检报告,你看十年也不会更健康。
大多数工厂的报表体系就是这个状态。其实目前的这个状态,让很多的公司都很焦虑,甚至他们想用一切的手段摆脱这个状态。特别是AI出现之后。
让我印象特别深刻的是,有一次拜访一个朋友的公司,和他们几位同事坐在一起交流,对方很直白地问我,现在已经有AI了。但是它到底能帮我做什么?
话题从AI拉回来。话说上了BI系统之后,报表快了。过去两天人工汇总的数据,现在5分钟自动生成。过去只有生产主管能看到的报表,现在全公司五百人在手机上都能看了。看起来数字化成功了。
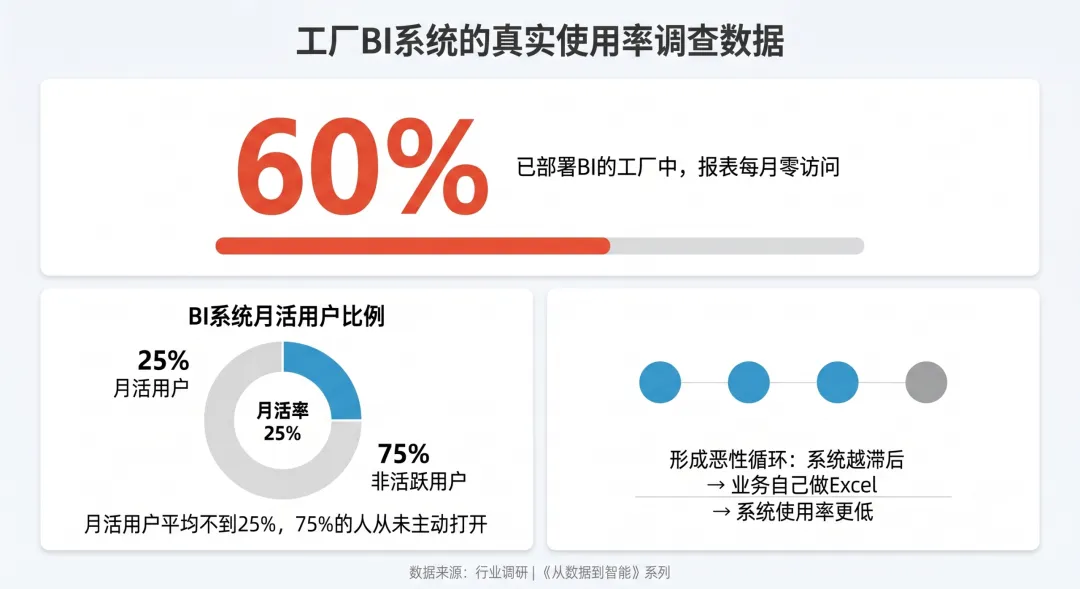
但我在网上看到一个你不一定知道的数据:
已经部署BI系统的工厂里,超过60%的报表每月零访问,月活用户平均不到25%。
虽然不知道这个数据的真实性如何,但可能它代表了一种状态。
为什么?不是系统不好用,是它回答的问题,不是业务部门在做决策时真正需要的问题。
数据团队做报表的逻辑通常是:我们有什么数据 → 我们能做什么分析 → 开始做报表。业务部门需要的逻辑恰恰相反:我明天要跟供应商谈判 → 我需要知道这个供应商过去半年的交货准时率 → BI里有这些数据吗?
两个逻辑完全错位。数据团队在自说自话,业务部门在用脚投票。
你见过这个场景吗?数据团队做了一张"月度销售汇总报表",销售额、销售量、增长率、占比等二十来个指标,看起来非常全面。但业务负责人真正想知道的是:"为什么华东这个月销量掉了15%?"报表里没有答案。
报表的价值不在于展示了多少数据,在于回答了多少业务问题。大部分BI报表的问题是:数据很多,答案很少。
更深层的问题是时效性。大多数报表是"月度"或"周度"的——月初看上个月的数据,下周一看上周的汇总。但业务的决策节奏是"天"甚至"小时"的。产线今天上午出了质量问题,生产主管不会等到下周的周报里才看到,他需要立刻知道。
当报表的产出周期比决策周期长一个数量级时,报表就变成了历史记录,而不是决策工具。
这就是为什么BI系统上线后,很多一线员工还在自己做Excel——等不及系统,只能自己动手。然后形成恶性循环:系统越滞后 → 业务越自己做Excel → 系统使用率越低 → 数据团队越觉得"业务不配合"。
所以"报表效率提升"的天花板在哪?在于你只是把"看过去的数据"变快了,但没有跨越到"用数据指导未来的行动"。
这个天花板,光靠换一个更好的BI工具,是打不破的。
要打破这个天花板,需要换一个思路。
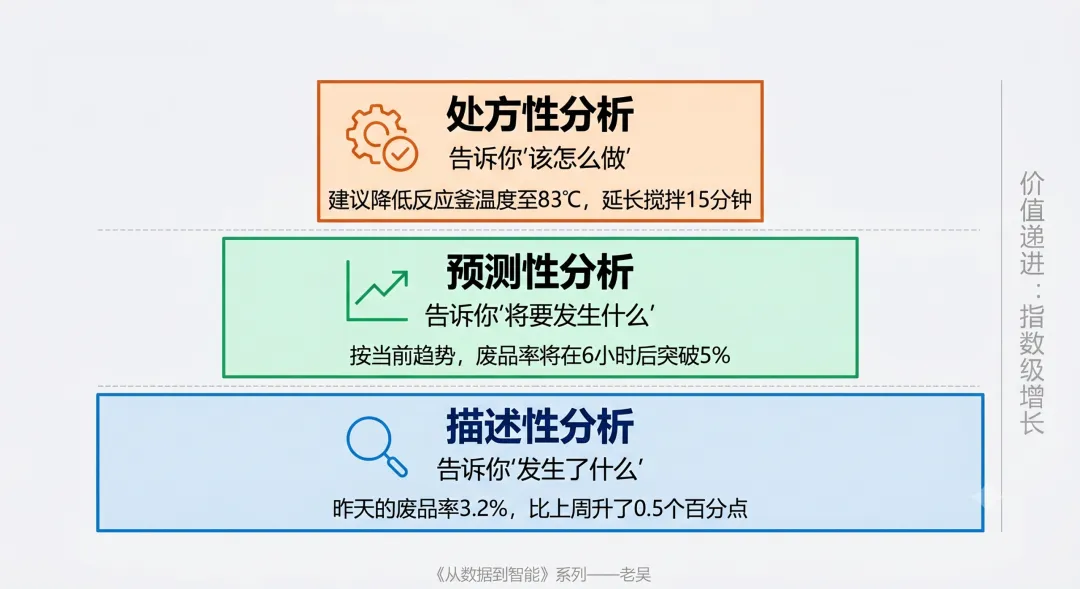
三种分析的区别,决定了你的数字化天花板在哪。
第一种,描述性分析。告诉你"发生了什么"。昨天的废品率是3.2%,比上周升了0.5个百分点。传统报表能做到这件事。
第二种,预测性分析。告诉你"将要发生什么"。按当前趋势,这批产品的废品率会在6小时后突破5%。这需要AI模型学习历史数据和实时数据。
第三种,处方性分析。告诉你"该怎么做"。建议立即检查3号产线的某个参数,同时排查原料批次的含水率,预计可以把废品率控制在4%以内。这需要把预测结果和工艺知识结合。
从我个人感知上,感觉大多数工厂目前可能还停留在第一种。少数开始做第二种。极少做到了第三种。但这三种的价值差异是指数级的。
我还在网上看到过一个案例,当然也可能还是段子,因为里面的数据感觉不太真实。但是我觉得也是挺有意思的:
某精细化工企业,年产两万吨产品,过去的质量管控方式是:每批次出厂前做质检,不合格品率超过3%算"异常"。数据体现在月度质量报表上——"本月异常批次占比8%"。管理层看到了问题,但问题已经发生了,废品已经产生了,损失已经造成了。
设想一下如果变了,会怎样?系统实时监控生产中的三十多个工艺参数,AI模型在生产进行到第三小时就预测出"本批次最终不合格品率可能达到6%"——此时生产还没结束,还有机会调整。系统不仅预测异常,还给出建议:"建议将反应釜温度从85℃降至83℃,延长搅拌时间15分钟,预计可将不合格品率降至2%以下。"
图片由AI生成,来源请见水印 (内容比较搞笑,仅供示意)虽然上面这个文章案例有可能只是个段子,或者是大家的美好愿景。但从"看到8%的不合格率"到"避免十几万的废品损失"——这才是数字化该有的价值。
但这个转变,不是换一个BI工具就能实现的。它需要数据从静态记录变成实时流、分析从人工解读变成自动推理、输出从数据展示变成行动建议。
这不是"更好的报表",这是完全不同的东西。它不叫"报表系统",它可能叫"决策系统"。
再问一个问题:你的工厂,报表体系处于哪个阶段?
如果你的报表已经走完了从纸质到系统报表的全过程,但你还是觉得"数据多了,决策没变"——那你已经站在了从"描述性分析"向下一步迈进的节点上。
我在这个系列后面会一点点讲我的体会:你的数据怎么来的、怎么打通、怎么治理、怎么变成模型、最终怎么变成管理层的决策输入。每一次讲一个我个人有感受的点,我不太会讲大道理,只分享一下我见过的事和踩过的坑。
下一篇,也许我们可以聊聊一个更扎心的问题:工厂不是"没有数据",是"数据在沉睡"。
如果觉得这篇有点感觉,点个关注。也欢迎在评论区说说,更欢迎不同的意见和见解,都可以丢过来。有思想的碰撞才会讨论出更有价值的结论。
老吴 | 制造业数字化转型探索 | 讲故事、讲问题、找方法、填真坑。