AI Case 5 · Excel数据智能分析:让AI读懂你的报表
AI案例实践系列第5期 | 难度 ⭐⭐ | Pandas + LLM、图表生成、洞察提炼
每个月底,运营同事都要手工整理一堆Excel——销售数据、用户数据、广告数据,做完图表还要写分析结论,光这一套下来就要半天。
今天我们换一个思路:把Excel直接丢给AI,让它自动分析、生成图表、写出业务洞察。
这个案例解决什么问题?
数据分析的痛点不是"不会用Excel",而是:
| 痛点 |
传统方式 |
AI方式 |
| 数据清洗 |
手动处理空值、格式问题 |
Pandas自动检测+修复 |
| 图表制作 |
手动选类型、调样式 |
根据数据类型自动选图 |
| 趋势分析 |
凭经验看折线 |
LLM提炼核心趋势 |
| 业务洞察 |
开会讨论、写PPT |
AI直接输出结论+建议 |
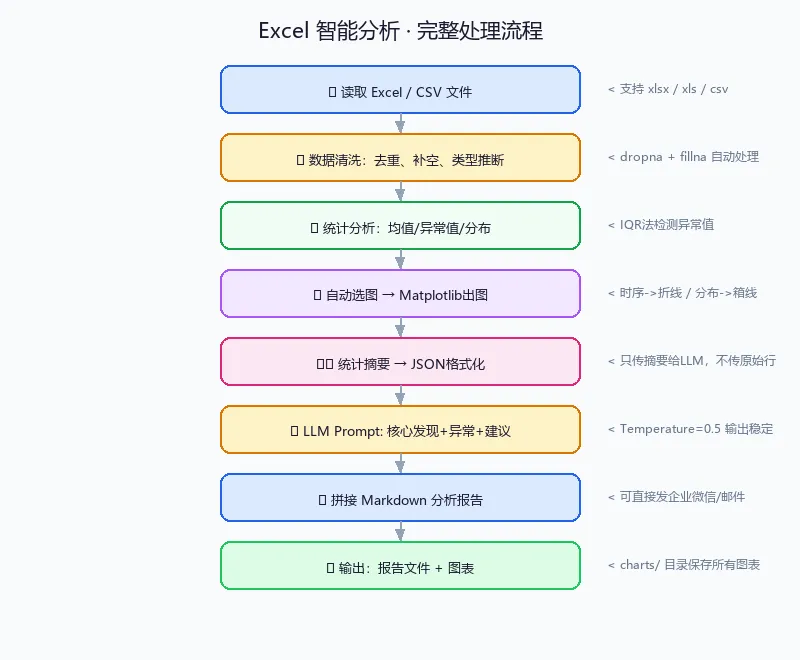
今天的工具链:Excel → Pandas读取 → 统计分析 → Matplotlib出图 → LLM解读 → 输出报告。
核心原理
整个系统分三层:数据层负责读取和清洗、分析层负责统计计算和可视化、LLM层负责把数字翻译成人话。
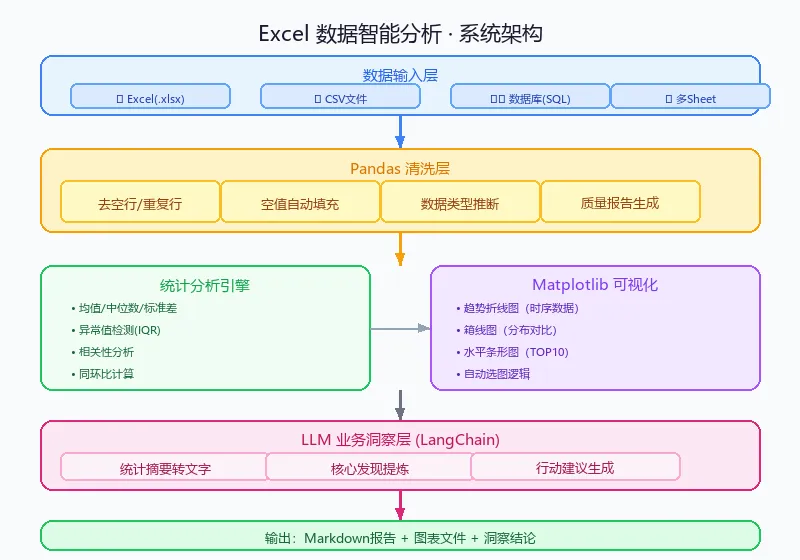
关键思路是先让Pandas算出结构化数据(均值、趋势、异常值),再把摘要性数字喂给LLM生成洞察。这样可以避免LLM直接算数出错,又充分利用它的语言能力。
动手写代码
安装依赖:
pip install pandas openpyxl matplotlib langchain langchain-openai seaborn
第一步:数据加载与清洗
import pandas as pd
import numpy as np
def load_and_clean(filepath: str) -> tuple[pd.DataFrame, dict]:
"""加载Excel文件,返回清洗后的DataFrame和数据质量报告"""
# 支持 .xlsx / .xls / .csv
if filepath.endswith('.csv'):
df = pd.read_csv(filepath, encoding='utf-8-sig')
else:
df = pd.read_excel(filepath, engine='openpyxl')
quality_report = {
"原始行数": len(df),
"列数": len(df.columns),
"列名": list(df.columns),
"空值统计": df.isnull().sum().to_dict(),
}
# 自动清洗:去除全空行、重复行
df = df.dropna(how='all').drop_duplicates()
# 数值列:空值填中位数(比均值更抗异常值)
for col in df.select_dtypes(include=[np.number]).columns:
df[col] = df[col].fillna(df[col].median())
# 字符串列:空值填 "未知"
for col in df.select_dtypes(include=['object']).columns:
df[col] = df[col].fillna('未知')
quality_report["清洗后行数"] = len(df)
quality_report["删除行数"] = quality_report["原始行数"] - quality_report["清洗后行数"]
return df, quality_report
第二步:自动统计分析
def auto_statistics(df: pd.DataFrame) -> dict:
"""对数值列自动计算核心统计量"""
stats = {}
numeric_cols = df.select_dtypes(include=[np.number]).columns
for col in numeric_cols:
series = df[col]
# 计算同比/环比需要时间列,这里先做基础统计
stats[col] = {
"均值": round(series.mean(), 2),
"中位数": round(series.median(), 2),
"最大值": round(series.max(), 2),
"最小值": round(series.min(), 2),
"标准差": round(series.std(), 2),
"总计": round(series.sum(), 2),
}
# 异常值检测(IQR方法)
Q1, Q3 = series.quantile(0.25), series.quantile(0.75)
IQR = Q3 - Q1
outliers = series[(series < Q1 - 1.5*IQR) | (series > Q3 + 1.5*IQR)]
stats[col]["异常值数量"] = len(outliers)
if len(outliers) > 0:
stats[col]["异常值示例"] = outliers.head(3).tolist()
return stats
第三步:自动生成图表
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import os
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
matplotlib.rcParams['axes.unicode_minus'] = False
def auto_visualize(df: pd.DataFrame, output_dir: str = './charts') -> list:
"""根据数据类型自动选择图表类型并生成"""
os.makedirs(output_dir, exist_ok=True)
chart_files = []
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
datetime_cols = df.select_dtypes(include=['datetime64']).columns.tolist()
# 如果有时间列+数值列 → 趋势折线图
if datetime_cols and numeric_cols:
time_col = datetime_cols[0]
df_sorted = df.sort_values(time_col)
fig, axes = plt.subplots(len(numeric_cols[:3]), 1,
figsize=(12, 4 * min(len(numeric_cols), 3)))
if len(numeric_cols) == 1:
axes = [axes]
for i, col in enumerate(numeric_cols[:3]):
axes[i].plot(df_sorted[time_col], df_sorted[col],
color='#4F86C6', linewidth=2, marker='o', markersize=4)
axes[i].set_title(f'{col} 趋势', fontsize=13, fontweight='bold')
axes[i].grid(True, alpha=0.3)
plt.tight_layout()
path = os.path.join(output_dir, 'trend_chart.png')
plt.savefig(path, dpi=150, bbox_inches='tight')
plt.close()
chart_files.append(path)
# 数值列分布 → 箱线图
if len(numeric_cols) >= 2:
fig, ax = plt.subplots(figsize=(10, 5))
df[numeric_cols[:6]].boxplot(ax=ax, patch_artist=True,
boxprops=dict(facecolor='#AED6F1', color='#2874A6'),
medianprops=dict(color='#E74C3C', linewidth=2))
ax.set_title('各指标分布对比(箱线图)', fontsize=13, fontweight='bold')
ax.grid(True, alpha=0.3, axis='y')
plt.xticks(rotation=30, ha='right')
plt.tight_layout()
path = os.path.join(output_dir, 'boxplot.png')
plt.savefig(path, dpi=150, bbox_inches='tight')
plt.close()
chart_files.append(path)
# 分类列 TOP10 → 条形图
cat_cols = df.select_dtypes(include=['object']).columns.tolist()
if cat_cols and numeric_cols:
cat_col = cat_cols[0]
num_col = numeric_cols[0]
top10 = df.groupby(cat_col)[num_col].sum().nlargest(10)
fig, ax = plt.subplots(figsize=(10, 5))
colors = plt.cm.Blues(np.linspace(0.4, 0.9, len(top10)))[::-1]
bars = ax.barh(top10.index, top10.values, color=colors)
ax.set_title(f'{cat_col} TOP10 ({num_col})', fontsize=13, fontweight='bold')
ax.grid(True, alpha=0.3, axis='x')
# 数值标注
for bar, val in zip(bars, top10.values):
ax.text(val * 1.01, bar.get_y() + bar.get_height()/2,
f'{val:,.0f}', va='center', fontsize=9)
plt.tight_layout()
path = os.path.join(output_dir, 'bar_top10.png')
plt.savefig(path, dpi=150, bbox_inches='tight')
plt.close()
chart_files.append(path)
return chart_files
第四步:LLM生成业务洞察
import json
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.schema import StrOutputParser
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.5)
insight_prompt = ChatPromptTemplate.from_template("""
你是一位经验丰富的数据分析师。根据以下数据统计摘要,给出专业的业务洞察。
数据概况:
{data_summary}
请按以下格式输出(每部分2-3点,简洁有力):
## 核心发现
(最重要的3个数据发现,结合具体数字)
## 异常预警
(需要关注的异常数据或风险点)
## 行动建议
(基于数据的3条可执行建议)
""")
insight_chain = insight_prompt | llm | StrOutputParser()
def generate_insight(stats: dict, quality_report: dict) -> str:
"""调用LLM生成业务洞察"""
summary = {
"数据规模": f"{quality_report['清洗后行数']} 行 × {quality_report['列数']} 列",
"字段列表": quality_report['列名'],
"统计摘要": stats
}
return insight_chain.invoke({
"data_summary": json.dumps(summary, ensure_ascii=False, indent=2)
})
第五步:一键生成分析报告
def analyze_excel(filepath: str, output_dir: str = './output') -> None:
"""主函数:一键分析Excel文件"""
print(f"正在分析: {filepath}")
# 1. 加载清洗
df, quality = load_and_clean(filepath)
print(f"数据加载完成: {quality['清洗后行数']} 行, 删除 {quality['删除行数']} 行脏数据")
# 2. 统计分析
stats = auto_statistics(df)
# 3. 生成图表
os.makedirs(output_dir, exist_ok=True)
chart_files = auto_visualize(df, os.path.join(output_dir, 'charts'))
print(f"图表已生成: {len(chart_files)} 张")
# 4. AI洞察
insight = generate_insight(stats, quality)
# 5. 输出报告
report_path = os.path.join(output_dir, 'analysis_report.md')
with open(report_path, 'w', encoding='utf-8') as f:
f.write(f"# 数据分析报告\n\n")
f.write(f"**文件**: {filepath}\n\n")
f.write(f"**数据规模**: {quality['清洗后行数']} 行 × {quality['列数']} 列\n\n")
f.write("---\n\n")
f.write("## 统计摘要\n\n")
for col, s in stats.items():
f.write(f"**{col}**: 均值 {s['均值']} | 中位数 {s['中位数']} | 总计 {s['总计']}\n\n")
f.write("---\n\n")
f.write(insight)
print(f"\n报告已保存: {report_path}")
print(f"\n{'='*50}")
print(insight)
# 使用示例
if __name__ == "__main__":
analyze_excel("./sales_data.xlsx", "./output")
实战演示:分析一份销售数据
用一份示例数据跑一遍完整流程:
# 生成测试数据(模拟一份季度销售报表)
import pandas as pd
import numpy as np
np.random.seed(42)
dates = pd.date_range('2024-01-01', periods=90, freq='D')
df_test = pd.DataFrame({
'日期': dates,
'销售额': np.random.normal(50000, 12000, 90).clip(0),
'订单数': np.random.poisson(120, 90),
'客单价': np.random.normal(400, 80, 90).clip(100),
'区域': np.random.choice(['华东', '华南', '华北', '西南'], 90),
'产品线': np.random.choice(['A产品', 'B产品', 'C产品'], 90),
})
df_test.to_excel('test_sales.xlsx', index=False)
analyze_excel('test_sales.xlsx')
运行后你会得到:
- 3张自动生成的图表(趋势图+箱线图+TOP10分布)
进阶技巧
技巧1:对接业务数据库
把 pd.read_excel() 替换为 pd.read_sql(),直接从MySQL/PostgreSQL拉数据,整套流程不变。
技巧2:定时自动分析
配合定时任务,每天早9点自动拉前一天的运营数据、生成报告并推送到企业微信,让老板每天上班就看到昨日数据洞察。
技巧3:多Sheet批量处理
# 处理一个Excel的所有Sheet
xl = pd.ExcelFile('multi_sheet.xlsx')
for sheet in xl.sheet_names:
df = xl.parse(sheet)
analyze_dataframe(df, sheet_name=sheet)
小结
今天我们把数据分析拆成了四个步骤:清洗→统计→可视化→LLM解读。
核心收益:
- Matplotlib负责画——自动根据数据类型选图
这套工具链不只适合技术人员,产品经理、运营同学稍微改一改Prompt风格,就能让AI帮你写数据周报了。
💡 下期预告:第6期《网页内容抓取与总结》——教你用AI批量抓取竞品网站/行业资讯,自动整理成结构化报告。
AI案例实践系列 · 第5期 · Excel数据智能分析
关注公众号,每天学一个能用的AI案例

