你用 AI 做过 PPT 吗?
如果做过,大概率经历过这几件事:配色跟公司模板对不上、排版均匀得像方格纸、每页信息密度一模一样、图表坐标偏差肉眼可见。你花在改 PPT 的时间可能比 AI 生成的时间还长。
这些问题不是 LLM 能力不行,也不是提示词写得不够好。是系统架构的设计思路有问题。
本文基于几套开源工具(ppt-master、PPTAgent、SlideGenius-AI)的源码分析,整理出三个核心问题及其对应的架构设计思路。如果你在做相关产品,或者正在评估选型,这些内容应该能帮到你。
🔧 问题 1:模板用不对
解法:读懂模板再动手
大多数工具的「支持企业模板」,实际操作是:你上传 .pptx → 提取背景图和 logo → 在这个背景上自由排版内容。
这不是在用模板。这是在模板的皮肤上涂鸦。
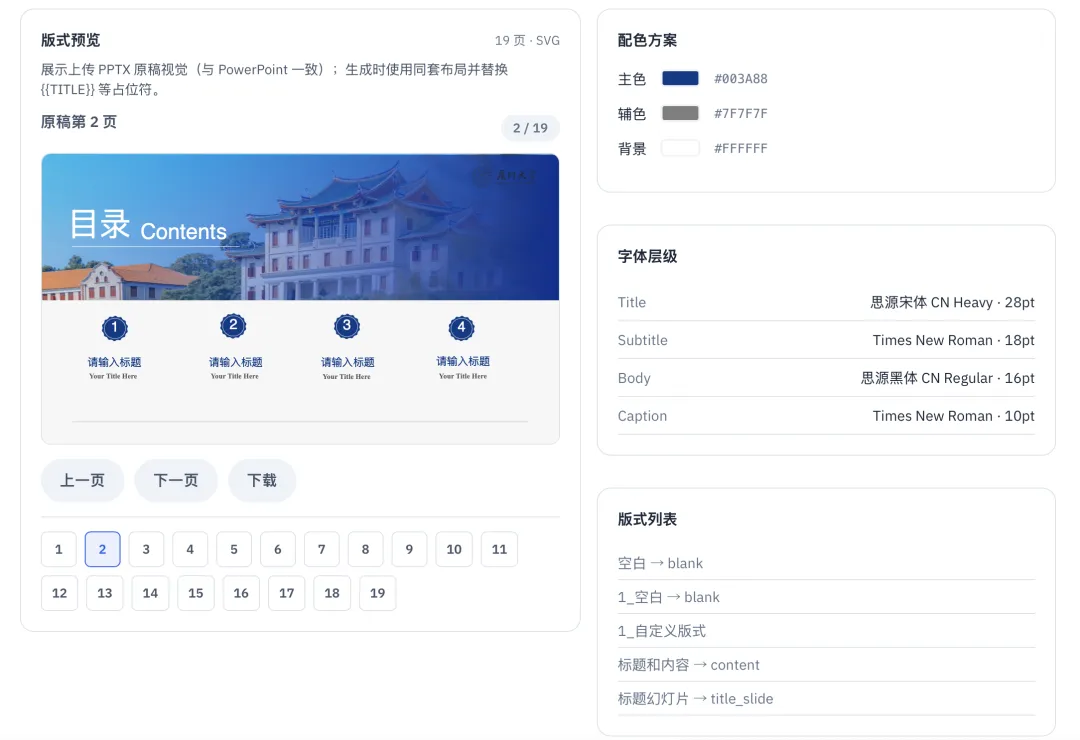
打开 PowerPoint,视图→幻灯片母版,你会看到三层结构:母版定义全局视觉语言,版式定义每类页面的骨架,幻灯片只填充具体内容——所有视觉规范从上层继承。
关键在这里:这些规范是用 EMU 单位写死在 XML 里的。「标题字号 44pt」「正文距左边距 0.8 英寸」——这些数字决定了这套模板的视觉 DNA,而不只是背景图长什么样。
正确的做法,不是训练更大的模型,而是把 .pptx 拆开,读里面的规范。
.pptx 本质上是个 ZIP 包,核心 XML 在三个目录:
ppt/slideMasters/ — 母版定义(全局视觉语言)ppt/slideLayouts/ — 版式定义(每类页面的骨架)ppt/theme/ — 主题定义(配色、字体方案)
开源项目 PPT Master 的 pptx_template_import.py是目前最完整的实现:输入一个 .pptx 模板,输出三组结构化数据:
manifest.json — 版式元数据(占位符位置、字号、字体的精确约束)svg/ — 每层渲染并标注占位符引导线assets/ — 可复用资源
拿到 manifest.json 之后,系统就知道了:「封面标题要放在 (x=457200, y=274638),宽度 8229600 EMU,用微软雅黑 Light 44pt。」——这不是估算,也不是猜测,这是模板里硬性规定好的约束条件。
📚 问题 2:生成的内容空洞
解法:给 LLM 准备好素材再让它组装
大多数工具的交互逻辑是:用户输入一个主题 → LLM 立刻从头写到尾。
对于简单汇报还行,一旦遇到技术分享、行业分析这类知识密集型场景,输出的东西往往比较泛泛。
为什么?因为 LLM 最擅长的事情不是无中生有,而是根据已有信息进行提取、重组、提炼。给它足够多且质量过关的参考资料,整理出来的效果远好于让它凭空编。
所以正确的做法,不是只让用户提供一个 Topic,而是接入三条素材管线:
- 个人知识库:本地散落各处的 PDF、Word、Obsidian 笔记、飞书/腾讯文档、网页收藏、会议录音转写稿
- 联网搜索:
- 结构化数据源:公司 BI 报表、Excel 数据表、内部数据库 API 接口
这三类来源格式不同,需要先统一转成 Markdown,再进入检索环节。
检索策略方面,推荐知识图谱 + 全文检索的混合召回:图谱解决关联问题(PPT 的内容不是孤立的),全文索引解决精确查找(「Q3 营收是多少」这种查询)。联网搜索作为补充通道,填补知识库的时间差。
执行顺序:图谱召回 → 全文精排 → AI 组织语言 → 注入 prompt。
🔍 问题 3:生成完就完事,质量没保障
解法:三层检查 + 用户行为学习
当前大多数 AI PPT 工具,生成完就完事。没有质量检查,没有迭代闭环。
正确的系统必须有三层质量检查:
第一层:规则检查(自动化,零 token)
第二层:视觉检查(半自动化)
程序能算出指标,但阈值靠人定。比如词数可以自动统计,但「80词算多还是少」取决于企业场景;坐标偏差能精确到像素,但「偏5px能不能接受」因项目而异。初始阈值由人设定,后续通过用户修改行为自动调优,逐步减少人工介入。
第三层:语义检查(AI 驱动)
迭代闭环:发现问题 → 自动修正 → 再检查 → 直到通过。不是「生成即交付」,是「检查通过后才交付」。
比自我检查更进一层:系统从每次使用中学习,越用越好。
五个学习机制:
- 用户修改行为记录— 用户上传修改后的 .pptx,系统逐页逐元素对比新旧差异(字号、颜色、位置、文本),再用 LLM 提炼修改意图。规则抓差异,AI 推意图,两者串联才是完整的修改记录。
- 用户偏好画像— 从历史修改构建偏好(视觉、结构、内容),下次生成时自动注入,不用每次重复指定。
- 模板版式统计与调优— 记录每种版式的使用频率和被修改次数,长期运行后系统对企业模板的理解超过大多数人类用户。
- 隐式反馈 + 显式评分— 是否保存了生成的 PPT(保存 = 满意)、用户主动打分,两种信号结合比单一信号可靠得多。
- 知识库动态调权— 用户采纳的素材调高权重,删掉的降低权重,知识库从静态存储变成动态演进的知识网络。
进化路径:
每次用户修改 → 记录修改行为 → 下次生成时注入偏好画像
长期运行后 → 模板版式统计调优 → 对企业模板的理解超过大多数人类用户
知识库动态调权 → 素材采纳率持续提升 → 系统越用越懂用户需要什么
✍️ 写在最后
做一个能真正交付的 AI PPT 系统,核心就三件事:
- 读懂模板:把 .pptx 拆成 XML 看清楚规范,不猜测,只读取。
- 接好素材管线:个人知识库 + 联网搜索 + 结构化数据,让 LLM 从素材中组装而不是从零编造。
- 建好闭环:三层质量检查 + 用户行为学习,生成完不是终点,是下一次更好的起点。
三件事都不需要什么前沿技术。难点在于愿意把工程投入花在这些「不性感」的地方,而不是模型换新、参数调优。
🎯关注「鱼生」的公众号,一起探讨智能体开发!