如果自定义函数仅仅需要用一次,那么可以定义成匿名函数,直接把函数的定义过程嵌套在其他函数的参数里面,不需要起函数名称。M 函数中的匿名函数是一种特殊类型的自定义函数。它没有名字,通常用于函数调用时直接传递给另一个函数使用,也就是 “即插即用”。它同样是由()=>表示的,符号左侧是参数列表,右侧是函数的计算逻辑。
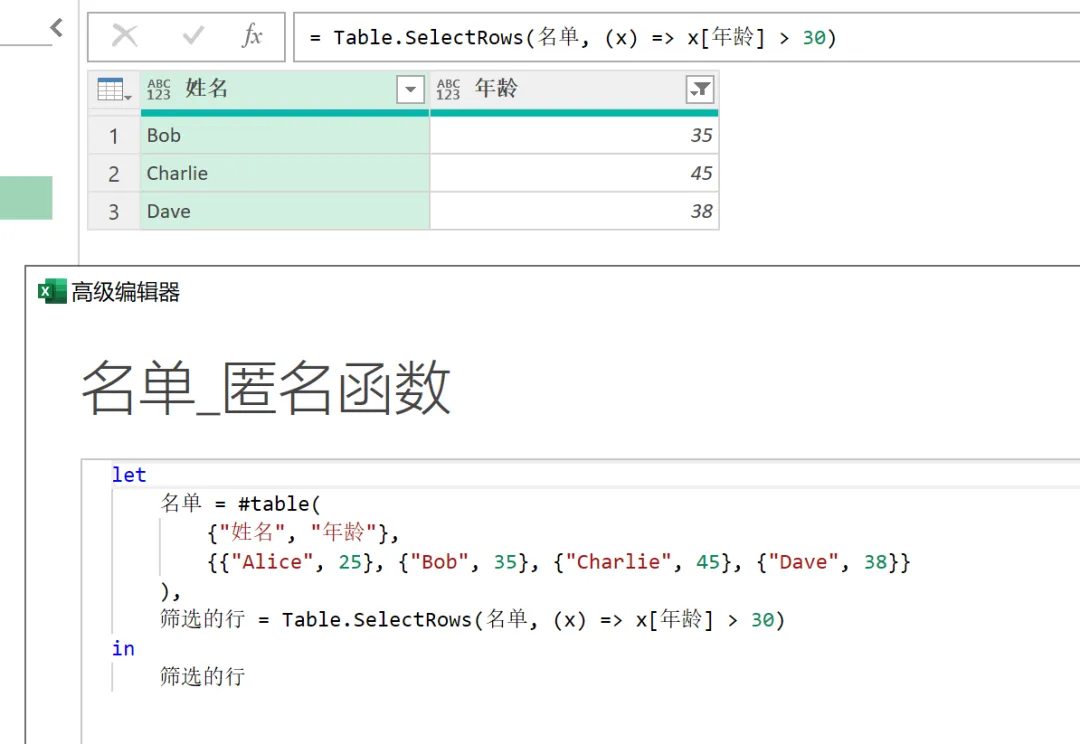
下面看一个简单的示例,从一份名单中将年龄大于 30 岁的人员选出来。可以使用匿名函数(x) => x[年龄] > 30,当然这个匿名函数需要嵌套在 Table.SelectRows() 函数中,如下图所示。
对于匿名函数,较重要的就是理解我们定义的参数(上面示例中是 x)。这里的参数 x 是我们自定义的,除了 x 以外我们还可以用字母 y 或者字母 r,当然中文也可以,只要不是 M 语言的关键字或者已经定义的对象名称。以下的 M 表达式等价:
筛选的行 = Table.SelectRows(名单, (x) => x[年龄] > 30)
筛选的行 = Table.SelectRows(名单, (y) => y[年龄] > 30)
筛选的行 = Table.SelectRows(名单, (r) => r[年龄] > 30)
筛选的行 = Table.SelectRows(名单, (表) => 表[年龄] > 30)
筛选的行 = Table.SelectRows(名单, (x) => Record.Field(x, "年龄") > 30) // 证明x是表的一行记录
匿名函数中的x代表了名单表的每一行(表的一行是一条记录),而x[年龄]就是名单表的年龄列的值,也就是从记录中深化出字段的值,相当于Record.Field(x, "年龄")。对参数x进行操作时需要提前了解它的数据结构。
我们在讲解自定义函数时,单独定义了 “折扣” 函数,然后在Table.TransformColumns()函数中调用。我们也可以在Table.TransformColumns()函数的参数中直接定义匿名函数,如下图所示。
let
源 = Excel.CurrentWorkbook(){[Name="销售数据"]}[Content],
折扣价格 = Table.TransformColumns(源, {{"价格", (x)=>if x >100 then x*0.98 else x }}) //直接定义匿名函数,仅使用一次
in
折扣价格
Table.TransformColumns()函数的作用是对指定列(价格列)中的每一个单元格进行转换,所以这里的参数x指代的是价格列中的每一个单元格。此时的x是一个值,所以就不存在行索引或者列名了。对于表而言,(x)=>代表的是每一行,比如前面的Table.SelectRows(名单, (x)=>x[年龄]>30)。那么在Table.TransformColumns(源, {{"价格", (x)=>if x>100 then x*0.98 else x }})中,(x)=>为什么能直接代表单元格的值呢?Table.TransformColumns()函数与Table.SelectRows()函数相比,多指定了列名 “价格”,也就是它在参数中就将行(记录)指定到了具体的列,行列交叉就可得到单元格的值。
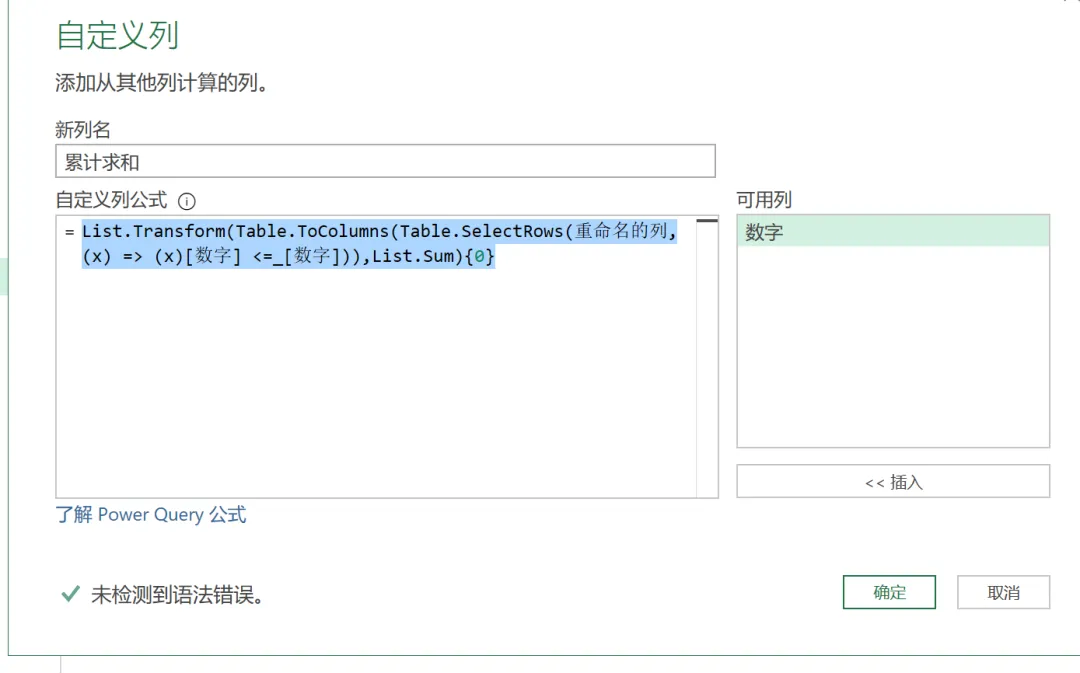
我们再看一个使用匿名函数累计求和的示例。对一列数字进行累计求和,也就是新建列计算从第一行到当前行的累计求和数,新建自定义列累计求和,如下图所示。(x) => x[数字] <= _[数字],就是匿名函数。这里的(x)指代的是源表的每一行,在源表中筛选出数字小于或等于当前行的所有行,然后通过嵌套的函数分步求和。
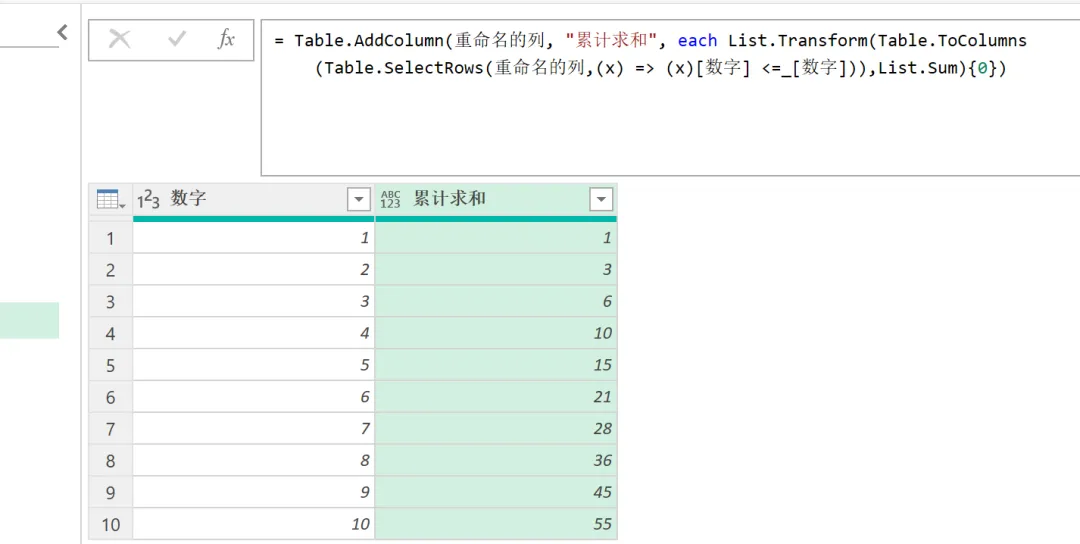
结果如下图所示。
好了,今天内容就这些。
我们一起走过了五月的学习,希望每个人都有收获。