我做 PPT 的水平,是随着 AI 大模型的更新,阶梯式往前跳的。
最早是完全不会做,后来,我开始用 NotebookLM 加上 Gemini,也能做出效果还不错的 PPT,但这套流程比较费时间,跟开盲盒一样,后期需要人工修改的地方实在太多了。直到上个月,ChatGPT image2 生图模型上线,图片中文生成和修改能力彻底进化后,那套旧方法就被我直接弃用了。
这让我产生了一个特别强烈的感受:大模型在很多场景里,会出现“赢者通杀”,当一个模型同时具备了理解、生成、修改、文件输出的全链路能力,而且能力还不错时,我就彻底失去了在不同软件间切来切去的动力。
我最近试出一条用 ChatGPT 做 PPT 的最快路径,不是一句话让它生成整套,而是把 PPT 拆成几个可控步骤:
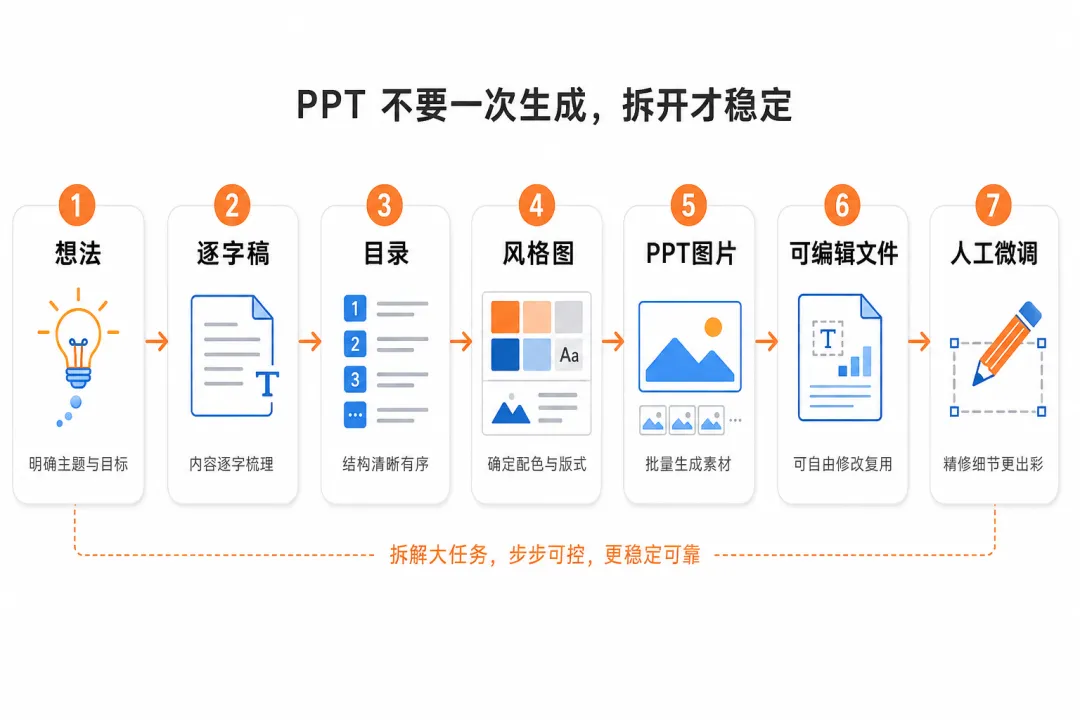
想法 → AI 写逐字稿 → 改逐字稿 → AI 生成 PPT 目录 → 改目录 → AI 生成图片 → 选风格,调图片 → 确定终版 PPT 图片 → 生成可编辑的 PPT → 人工微调。
熟练的话,做完这一套,真 · 半个小时就可以搞定。
这次刚好有一个真实案例:我要给内容组做一次分享,把我做私域宣发时的一套底层逻辑讲清楚,最后这套 PPT,就是我按这条路径做出来的。
第一步:先想清楚“讲什么”
我先把这次分享的大概想法丢给 ChatGPT,让它帮我生成一版逐字稿,逐字稿出来后,我会和 ChatGPT 来回探讨、修改,直到我认为讲述的逻辑彻底顺畅了,再进入下一步。
这一步很重要,很多人做 PPT 慢,不是因为不会排版,而是一开始就把“我要讲什么”“PPT 怎么排”“页面好不好看”全混在一起了,来回修改非常浪费时间,思路也容易被打断。
第二步,想清楚“怎么排”
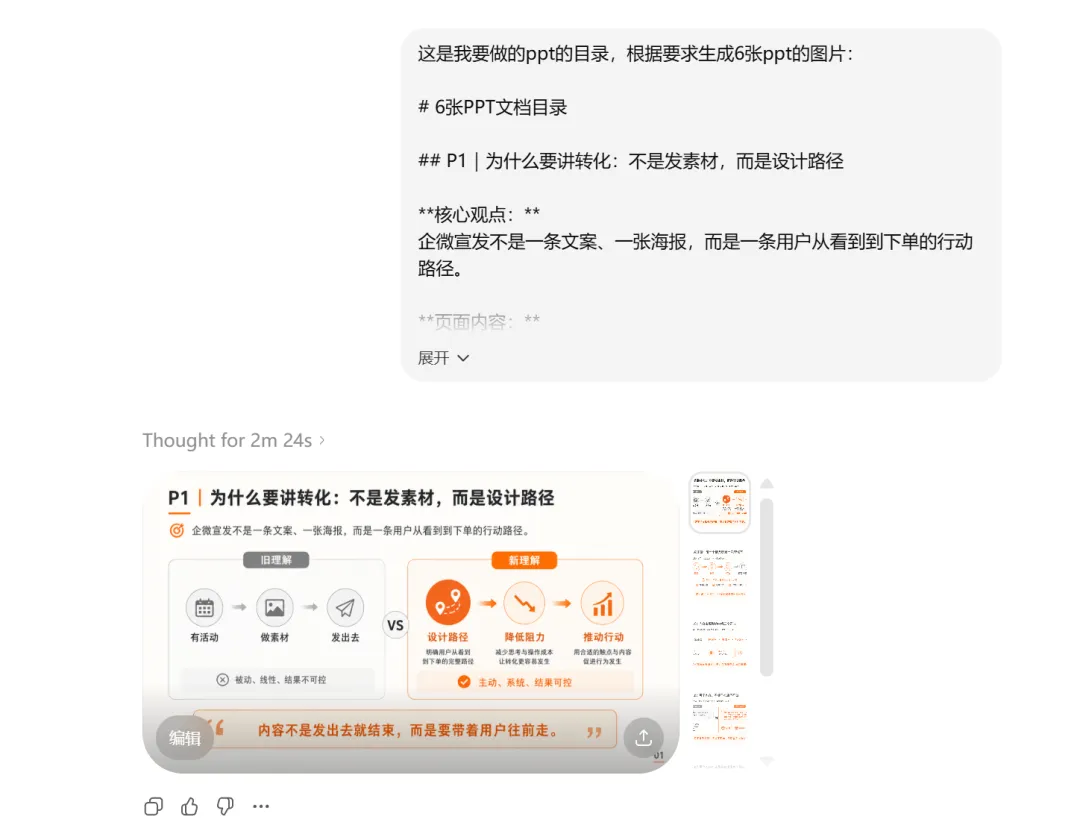
我让 ChatGPT 根据最终逐字稿,整理成 6 张 PPT 的文档目录,这是在把逐字稿,提炼成可以被视觉化表达的页面:第一页讲什么,第二页讲什么,每一页的核心观点是什么,页面里要放哪些内容。
解决的是怎么排的问题,同时也方便下一步生成图片。
拿到目录后不能直接用,还需要人工过一遍,和ChatGPT讨论确定最终版:哪些内容适合放在 PPT 上,哪些只适合口头讲;哪些页面太满,哪些顺序不对。
第三步,生成“概念图”,用最低成本试错风格
注意,我这里先生成的是图片,不是可编辑 PPT,因为这个阶段,文件格式不重要,重要的是看大方向对不对:页面逻辑有没有跑偏?信息层级清不清楚?视觉风格是不是我想要的?
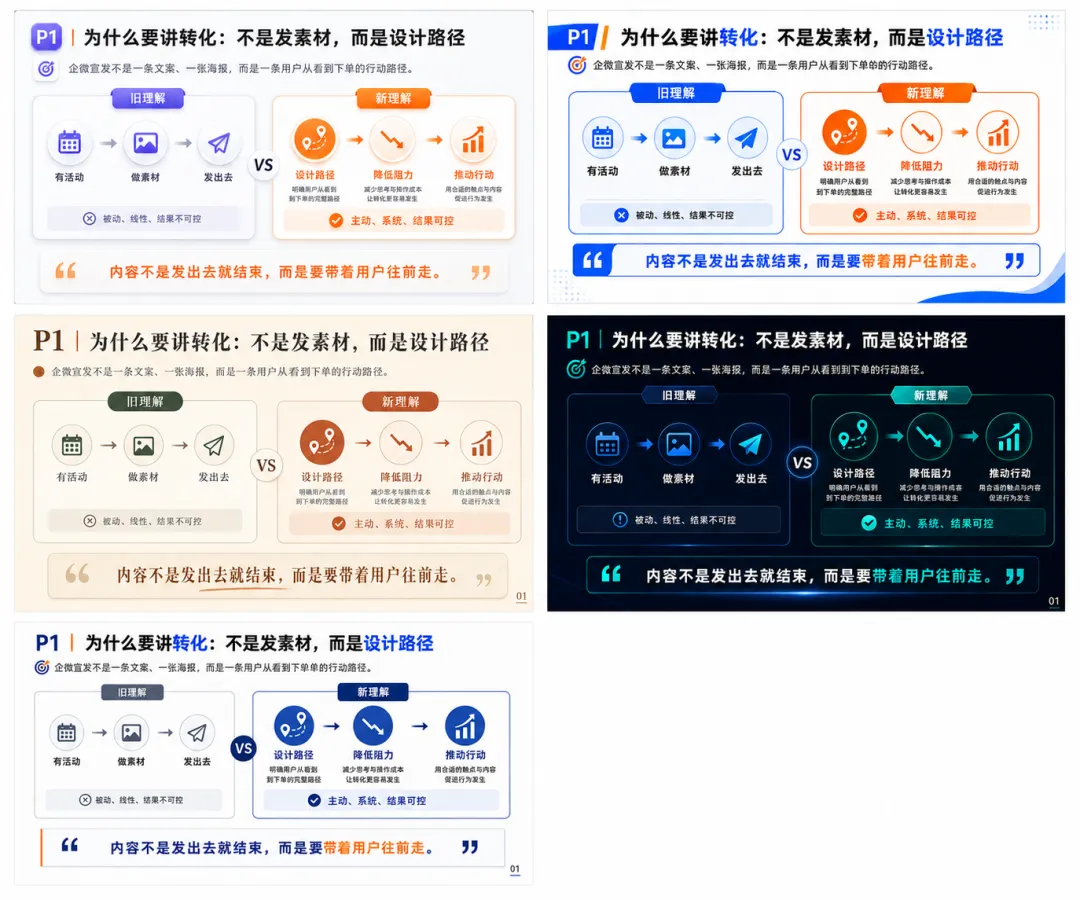
如果第一版风格不喜欢,不要在错误风格上将就,再让 AI 帮你探索不同视觉方向。
我会直接跟 ChatGPT 说:这个风格我不太喜欢,你再给我生成 5 种不同风格,各生成一张图,让我来选。
ChatGPT一次最多可以生成10张,不过5个风格一般已经够选的了。
选中满意的风格后,再让它按这个风格生成整套 PPT 图片。
第四步:对话式修改,取代手动拖拽
其实,到这一步,如果你只是想做一套用来演讲或投屏展示的 PPT,已经够用了。
ChatGPT 现在的指令依从性极其惊人,中文字体都可以处理得不错,图画就更不用说了。
你可以直接在对话里修改 PPT 图片:这里换个表达,那里补一行字,某个箭头上加一个标签,某个图标换一下。
比如,我让它在箭头上补充转化率类型(停留率、看懂率、行动率等),它立刻就能精准改好,这比你自己打开 PowerPoint 一点点改,还要快。
这让做 PPT 从盲盒式的“抽卡”,变成了精准的“对话式修改”。 你只要能指出哪里不对,它就能替你动手。
第五步:不要“转译”,要“视觉重建”
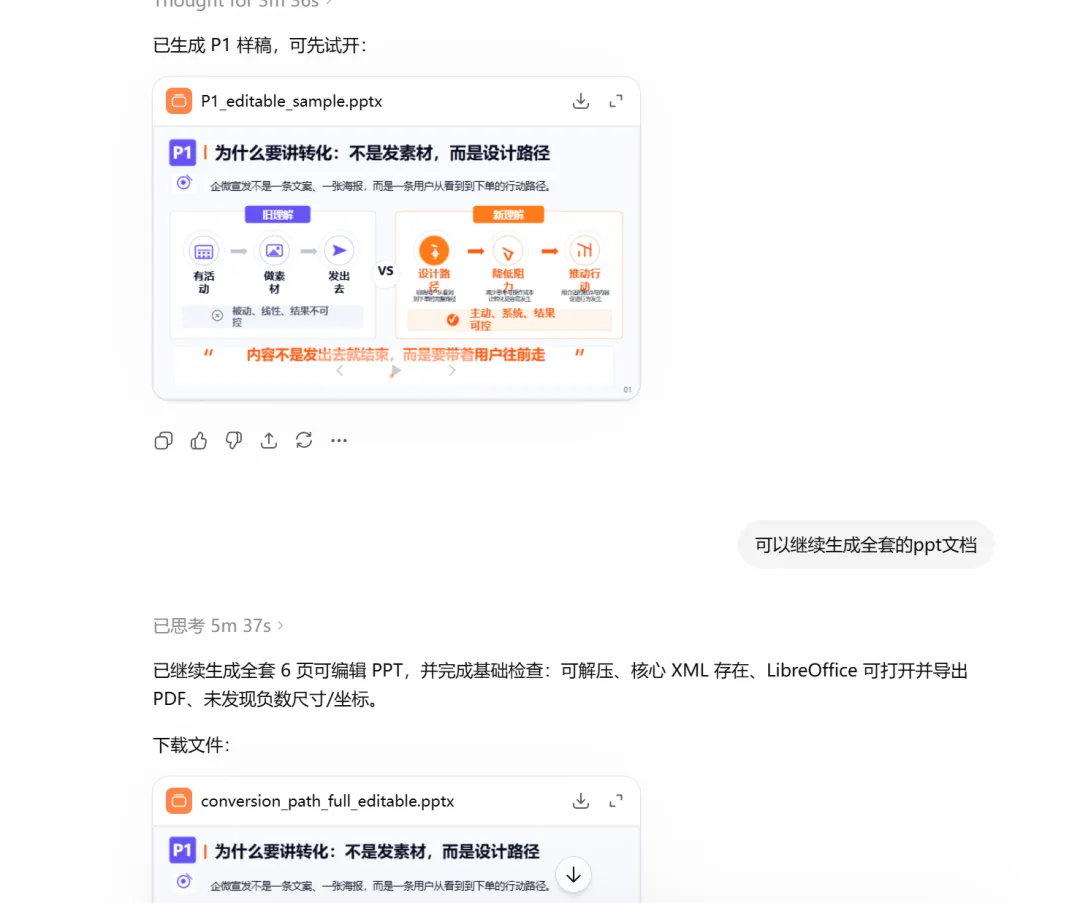
当然,如果你需要的是可编辑 PPT 文件,那就继续往下走。
我最开始用image2 生成可编辑 PPT,经常不稳定,有时候生成得很好,有时候又很简陋。
我一开始以为这是模型不稳定,后来我实在烦了,直接问 ChatGPT:
我要怎么说,你才能按我的想法生成可编辑 PPT?

它直接给了我一段提示词,后面我经过继续调试,确定成了现在这版:
请不要做普通图片转译。 请你根据我上传的图片 / 文件,用 **PPT原生元素** 重新搭建一份 **可编辑 PowerPoint 文件(.pptx)**。这不是 OCR 转换任务,也不是把图片贴进 PPT。 请把我上传的图片当成 **截图级视觉蓝本**,用 PPT 元素逐页重建。## 一、核心目标优先级如下:1. **文件必须能被 Microsoft PowerPoint 正常打开**2. **所有文字必须是可编辑文本**3. **版式、层级、颜色、字体风格、图标位置和视觉比例尽量贴近原图**4. **圆角框、色块、箭头、边框、阴影、图标都尽量用 PPT 原生元素重建**5. 不追求 100% 像素级复刻,但必须做到:**可编辑、接近原图、细节完整、适合继续修改**## 二、视觉重建要求请不要重新设计,不要自行优化版式。请按以下方式执行:- 先把原图作为视觉底稿进行对齐;- 按照原图的位置、大小、颜色、圆角、阴影、边框、层级逐项重建;- 最后删除底稿,不要把原图作为背景或图片贴进去;- 文字必须全部重新输入为 PPT 可编辑文本;- 图标可以用相近的 PPT 原生图标 / SVG 图标 / 简化线性图标替代;- 图标无法完全一致时,优先保持:**位置、大小、颜色、视觉重量接近原图**;- 不允许把整页截图当作图片放进 PPT;- 不允许只做风格相似,必须尽量贴近原图结构。## 三、必须保留的视觉细节请重点保留:- 页面边距- P 编号位置和样式- 主标题位置、字号、粗细- 副标题位置- 左侧小图标位置- 卡片大小和左右间距- 圆角大小- 阴影层级- 标签条位置和颜色- 箭头位置- 底部金句框高度、位置、颜色- 页码位置## 四、PPT 兼容性要求:必须避免打不开生成 PPT 时请严格注意:- 不要使用 PowerPoint 可能无法识别的异常 XML;- 不要生成负数宽高、负数坐标、负数线条长度;- 所有 shape 的 x、y、width、height 必须为正数;- 所有线条、箭头必须使用 PowerPoint 标准 shape / connector;- 不要使用 LibreOffice 能打开但 Microsoft PowerPoint 不能打开的特殊元素;- 尽量避免复杂自定义 geometry;- 如果需要箭头,请用标准 PPT 箭头形状;- 如果需要阴影、渐变、透明度,请使用 PowerPoint 标准属性;- 文件名请使用英文或简单中文,避免特殊符号;- 生成后必须检查 `.pptx` 压缩包结构是否正常;- 必须确认文件不是空文件、不是损坏文件。## 五、生成后的自检要求在给我下载链接前,请先完成以下检查:1. `.pptx` 文件可以作为 zip 正常解压;2. `[Content_Types].xml` 存在;3. `ppt/presentation.xml` 存在;4. `ppt/slides/slide1.xml` 等页面文件存在;5. 所有图片底稿已经删除;6. 页面文字是可编辑文本,不是整页图片;7. 用 LibreOffice 或其他工具尝试打开并导出 PDF;8. 检查是否存在负数尺寸、异常坐标或无效 XML;9. 如果发现 Microsoft PowerPoint 可能打不开,必须重新修复后再给我文件。## 六、工作方式请不要一次性直接做完整文件。请先只生成 **P1 一页样稿**,让我确认:- 是否能正常用 Microsoft PowerPoint 打开;- 是否接近原图;- 字号、间距、颜色、阴影、圆角是否可以接受。我确认 P1 样稿后,再继续生成完整 PPT。## 七、输出要求请最终输出:- `.pptx` 文件; - 文件必须能被 Microsoft PowerPoint 正常打开;- 不要只给我图片;- 不要只给 PDF;- 不要把原图贴进 PPT 冒充可编辑文件。
这段提示词会先根据上传的图片中的1张生成可编辑的PPT文档,确认可以接受后再让它生成全套。
这个提示词之所以有效,是因为它纠正了 AI 的行为模式了,也可以说是我们把话说清楚了。
你说“帮我转成 PPT”,AI 会按最省算力的方式(比如直接贴图)糊弄你; 但你说“请像重新设计 PPT 一样,用原生元素重建”,它才知道你真正要的是能够供你后续编辑的基础组件。
写在最后
这套方法并非完全不需要人工,你最终还是要检查对齐、微调细节。但它已经把最耗时间、最折磨人的环节全部前置给了 AI:梳理内容结构、探索页面风格、局部元素修改、可编辑文件的重建。
人,只需要退一步,做好判断和微调。
在这个过程中我最大的感触是:用 AI 做事,遇到卡点时不要急着怪模型不稳定,先问问 AI:“我要怎么提问,你才能达到我的标准?”
很多时候,不是 AI 做不到,而是我们没有把标准说清楚。
目前,我还正在探索另一条路径——如何在 Obsidian 里直接生成可编辑的 PPT。路径已经跑通了,效果很惊艳,等我调试稳定了,再单独写一篇和大家分享。






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
