当我们把需要分析的 Excel 数据表拖进 Deepseek,它是如何读取附件数据的?
真相是——AI 根本没见过那个 .xlsx 文件。 它读到的东西,是由系统在毫秒之内翻译好的一段纯文字。
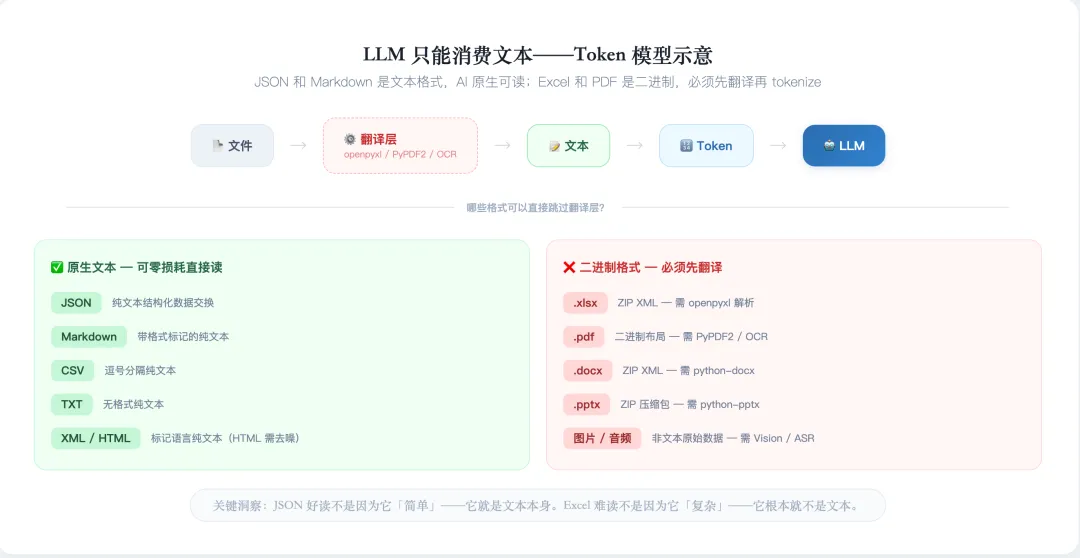
不只是 Excel。上传的 PDF、Word、PPT、图片、音频——所有那些以为「AI 能直接看」的文件,AI 都没有真正触摸过。它看到的,从头到尾,全是同一件东西:文本。
这也解释了为什么 Markdown 和 JSON 在 AI 时代突然重要了起来——不是偏好问题,而是它们天生就是 AI 的母语,不需要翻译。
02 根本原理:LLM 只消费一种东西——token
先回到最底层的问题:一个 LLM 的输入到底是什么?
不是文件,不是图片,甚至不是文字。
LLM 看到的,是一串整数——token。这是自 Transformer 架构诞生[1] 和大规模语言模型(如 GPT-3)出现以来 [2],所有 LLM 共有的输入范式。
输入: "帮我分析这个表格" ↓Tokenizer: "帮" → 8234"我" → 2109"分" → 1823"析" → 3821 ... ↓LLM 收到的: [8234, 2109, 1823, 3821, ...]
而 tokenizer(分词器)能处理什么?只有文本。 如果把一个 .xlsx 文件的原始字节流直接丢给它,它根本不认识——那不在它能 tokenize 的范围内。
所以 LLM 接收信息的路径只有一条:
文本 → token → LLM
从来没有「文件 → LLM」。任何文件要想进入 LLM 的「大脑」,都必须在到达 tokenizer 之前变成文本。
03 六种文件,六种「翻译」方式
被拖进 AI 窗口的文件千差万别,但它们到 AI 面前时全被翻译成了同一件事:文字。只不过每种格式的翻译方式完全不同。
📊 Excel(.xlsx)—— 主力拆解
.xlsx 是什么?很多人以为它是某种「办公表格格式」。从计算机角度看,它是一个 ZIP 压缩包,里面装着一堆 XML 文件。这是国际标准 ECMA-376(即 Office Open XML)规定的格式结构 [3]。
可以做一个小实验:把一个 .xlsx 重命名为 .zip,解压——会看到 xl/worksheets/sheet1.xml、xl/sharedStrings.xml 等等。
AI 不是读了一个表格,是读了一个 ZIP。
当「上传 Excel」时,翻译层做的是:
.xlsx 文件 → openpyxl(或类似库) → 打开 ZIP → 解析 sheet1.xml → 提取单元格坐标、值、类型 → 重新组装为 Markdown 表格文本: | 月份 | 区域 | 销售额 | 增长率 | |------|------|--------|--------| | Q1 | 华东 | 500万 | 8% | | Q2 | 华东 | 560万 | 12% | → 插入 prompt
在这个过程中丢失了什么?
- 图表——它们是二进制图形对象,不体现在 XML 单元格里,直接消失
- 公式——
=VLOOKUP(A2, Sheet2!A:B, 2, FALSE) 的逻辑无法传递。部分解析器能读出公式文本,但 ChatGPT 等产品的上传接口通常只提取计算后的结果值,公式本身被丢弃 - 多 Sheet——ChatGPT 等主流对话产品的上传接口通常只处理第一个 Sheet,跨 Sheet 引用全部断裂
所以 AI「分析 Excel」的准确度,上限由这次翻译的质量决定。公式没了它无法追溯计算逻辑,合并单元格裂了它无法还原层级关系,图表丢了它根本不知道有过图表。
📄 PDF —— 翻译质量最不稳定
PDF 的翻译分两种情况。如果 PDF 是由文字处理器或排版软件直接生成的(内部含有文本层),PyPDF2 之类的工具可以直接提取文字——但提取顺序取决于 PDF 内部的对象排列,双栏排版时左栏右栏可能交错输出,读起来像天书。
如果 PDF 是扫描件(图片 PDF),那就需要先 OCR、再提取。而 OCR 的准确率取决于扫描质量——模糊、倾斜、手写字都会导致识别错误。
所以同一个 PDF,AI 读出来的内容有时候对有时候完全错。不是 AI 的问题——是翻译层的锅。
🖼️ 图片 —— 根本不是「读」,是「看」
图片不经过文本翻译层。多模态模型(GPT-4V、Claude Vision)有专门的 Vision Encoder,它把图片像素转化为一串与文本 token 混合的 feature token(特征向量)。这项技术源自 CLIP 等视觉-语言对齐模型 [4]。
所以 AI 不是「读了图片里的文字」,而是「看了整张图的视觉特征后,对内容做了一个描述」。可以把它理解为——AI 看着图片,用自己的话说了一遍上面有什么。
这解释了为什么 AI 识别图表中的精确数值偶尔会出错,为什么手写体比印刷体更难读——它不是 OCR 引擎,是视觉语义模型。
🎵 音频 —— 先听写,再推理
音频文件(.mp3、.wav、.m4a)先用 Whisper 等语音识别模型转成文本(ASR,自动语音识别)[5],再把这段文本插入 prompt。
如果音频里有多个人在说话,ASR 通常不区分说话人(除非用了 speaker diarization),所以 AI 看到的是一段没有标注谁在说话的对白文字。
📝 Word(.docx)—— 和 Excel 同宗但更简单
.docx 也是 ZIP + XML,通过 python-docx 解析。翻译层主要丢的是排版信息:字号、加粗、颜色——保留了文字内容和段落结构,但视觉层次被抹平。
🌐 网页(HTML)—— 需要先「清洗」
HTML 本身就是文本,但它是带着标签的文本。<div class="sidebar"><ul><li><a href="...">广告</a>——这些内容对 AI 来说都是噪音。Agent 需要先用 Firecrawl 或 Tavily 把 HTML 转为干净的 Markdown,去掉导航栏、广告、侧边栏,只留正文。
04 把 Excel 再拆深一点——为什么它是最复杂的?
在上面六种格式里,Excel 是最特别的一个。因为它的信息损失不是从二进制到文本的损失,而是从「多维结构」压缩成「一维文本」的损失。
一个 Excel 文件里至少有这些信息层:
| | |
|---|
| 单元格值 | | |
| 行列结构 | | |
| 公式 | | |
| 数据验证 | | |
| 条件格式 | | |
| 图表 | | |
| 合并单元格 | | |
| 多 Sheet 关系 | | |
| 筛选/冻结 | | |
翻译后的 AI 看到的是:「有一张表格,行是月份和区域,列是销售额和增长率」。它看不到公式、看不到图表、看不到条件格式——而这些东西往往是数据分析的核心。
这解释了为什么「帮我看这个 Excel 里的数据和图表」——AI 总是只分析数据,从来不提图表。不是它忽略了,是根本没收到。
05 所以什么样的格式 AI 能直接读?——Markdown 和 JSON 的意义
理解了上面的流程,结论就很清楚了:
任何本身就是纯文本的格式,AI 都能零损耗直接读。不是文本的格式,必须经过翻译——而有翻译就有损失。
这就是 Markdown 和 JSON 存在的核心意义。它们不是「比 Word/Excel 更好的格式」——它们是唯一一类不需要翻译、AI 能直接消费的格式。
| | | |
|---|
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | Vision Encoder → feature token | |
| | | |
在对话窗口里打出来的字,是 AI 直接读的。写在一个 .md 文件里贴给 AI,也是直接读的。但放在 .xlsx 里的东西,AI 读到的是经过翻译的二道信息。
所以:JSON 和 Markdown 不只是 AI 时代的偏好,而是 AI 通信的原生协议。 用它们给 AI 数据,等于在说同一种语言。用 Excel/PDF/Word,就等于让中间人翻译——翻译得好是运气,翻译得差是常态。
06 Markitdown:承认「AI 只能读文本」这件事
理解了「AI 只能读文本」这个前提,就容易理解为什么 Markitdown 能在 GitHub 上超过 10 万 Stars(截至 2026 年 4 月已达 10.7 万)[6]。
它是微软 AutoGen 团队开源的一个 Python 工具,只做一件事:
把任何格式 → Markdown。
PDF、Word、PPT、Excel、图片(OCR)、音频(ASR 转文字)、网页、CSV、ZIP……20+ 种格式,一键转成 Markdown。
from markitdown import MarkItDownmd = MarkItDown()result = md.convert("sales_report.xlsx")print(result.text_content)# 输出:# | 月份 | 区域 | 销售额 |# |------|------|--------|# | Q1 | 华东 | 500万 |
2025 年还出了 MarkItDown-MCP,作为一个 MCP Server 可以直接被 Claude Code 或任何 MCP 兼容的 Agent 调用。
这个工具的灵魂不在于技术多高深——而在于它明确承认了一件事:AI 只能读文本。我们的工作就是给所有人类文件格式做一个统一的翻译层。
就像没人会把 ZIP 直接扔给文本编辑器,得先解压。Markitdown 就是 AI 时代的「解压软件」,只不过它解的不是 ZIP,是 .xlsx、.pdf、.docx、.pptx——把人类世界的繁复格式,统一翻译成 AI 的母语。
07 实战启示:跟 AI 打交道,格式应该怎么选?
| | |
|---|
| JSON / Markdown 表格 | |
| Markdown | |
| 纯文本 | |
| | |
| Markdown + JSON | |
| | |
总结:如果内容主要给 AI 看(RAG 文档、Agent 数据、LLM 上下文),用 Markdown 和 JSON。如果主要给人看,用传统格式——但要清楚 AI 多了一道翻译损耗。
08 More
这个认知偏差的背后,是一个更根本的问题:
人对数据的认知和 AI 对数据的认知,是两套完全不同的体系。
对人来说,「文件就是信息」——一个 Excel 文件 = 一张表格,一张图片 = 一个场景。格式是透明的。
对 AI 来说,「文本才是信息」——所有不是文本的东西都是「待翻译的噪音」。在被翻译成文本之前,这些东西对 AI 来说等于不存在。
这个认知差解释了近年来的几个趋势:
- 为什么 Markdown 突然成了 AI 时代的第一格式? 不是编辑器好用——它就是 AI 的母语。写 Markdown,等于跟 AI 说同一种语言。
- 为什么 JSON 是 AI 工具链的默认交换格式? 因为 JSON 是纯文本,能表达复杂结构,且 AI 不用翻译就能读。
- 为什么「AI 能直接处理 Excel」是幻觉? 除非 AI 调用了代码执行环境去读写 .xlsx,否则它只是在读写一段翻译过的文本。
- 为什么 Agent 必须先做预处理? 因为网页(HTML 噪音)、文件(二进制)、多媒体(非文本)——所有这些 AI 都不能直接消费。它们需要先被翻译。
09 最后
这篇的核心,一句话:
每次把文件拖给 AI,AI 从来没碰过那个文件本身。它读到的是系统帮它翻译的文本。翻译得好的,给人的感觉是 AI 真的「读懂了」。翻译得不好的,就觉得 AI 不够聪明。其实 AI 从头到尾都只做了一件事——读文字。
选择用什么格式跟 AI 沟通,不只是偏好的问题。是选的格式,能不能以最小损耗穿越「人类世界 → AI 世界」这道翻译边界。
🔧 附:Markitdown 快速上手
pip install markitdown
from markitdown import MarkItDownmd = MarkItDown()# Excel → Markdownresult = md.convert("data.xlsx")print(result.text_content)# PDF → Markdownresult = md.convert("report.pdf")# Word → Markdownresult = md.convert("document.docx")# 图片 → Markdown(自动 OCR)result = md.convert("scanned.jpg")# 批量转换import osfor f in os.listdir("docs/"):if f.endswith((".xlsx", ".pdf", ".docx", ".pptx")): result = md.convert(f"docs/{f}")with open(f"output/{f}.md", "w") as out: out.write(result.text_content)
📚 参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems 30. Long Beach: NeurIPS, 2017: 5998-6008.
[2] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[C]//Advances in Neural Information Processing Systems 33. Virtual: NeurIPS, 2020: 1877-1901.
[3] ECMA International. Standard ECMA-376: Office Open XML File Formats[S]. 5th ed. Geneva: ECMA International, 2021.
[4] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//Proceedings of the 38th International Conference on Machine Learning. Virtual: ICML, 2021: 8748-8763.
[5] Radford A, Kim J W, Xu T, et al. Robust speech recognition via large-scale weak supervision[J]. arXiv preprint arXiv:2212.04356, 2022.
[6] Microsoft AutoGen Team. MarkItDown: Python tool for converting files to Markdown[CP/OL]. GitHub. (2024). https://github.com/microsoft/markitdown.
📌 觉得有用?「点赞」、「分享」+「推荐」,让更多人看到!