做中文报表字段拆分,Excel用MIDB更精准
- 2026-06-01 07:36:04
做中文报表字段拆分,Excel用MIDB更精准
函数简介
在 Excel 中,MIDB 是 按字节(byte) 截取文本的函数,常用于 双字节字符集(DBCS) 环境,例如中文、日文、韩文等。与 MID(按字符截取)不同,MIDB 把每个中文字符视为 2 个字节,因此在处理混合了中文和英文/数字的字符串时尤为精准。业务场景中常见的应用包括:
• 从“月份”列(如 1月)提取出纯数字;• 把“销售员”列的姓名拆分为姓和名; • 将“产品类别”列的前缀、后缀分离,便于统计或匹配。
语法
=MIDB(text, start_num, num_bytes)| text | |
| start_num | |
| num_bytes |
注意:如果
start_num小于 1,或num_bytes<0,公式会返回#VALUE!错误。
示例(基于真实业务数据)
数据来源:20 行销售明细
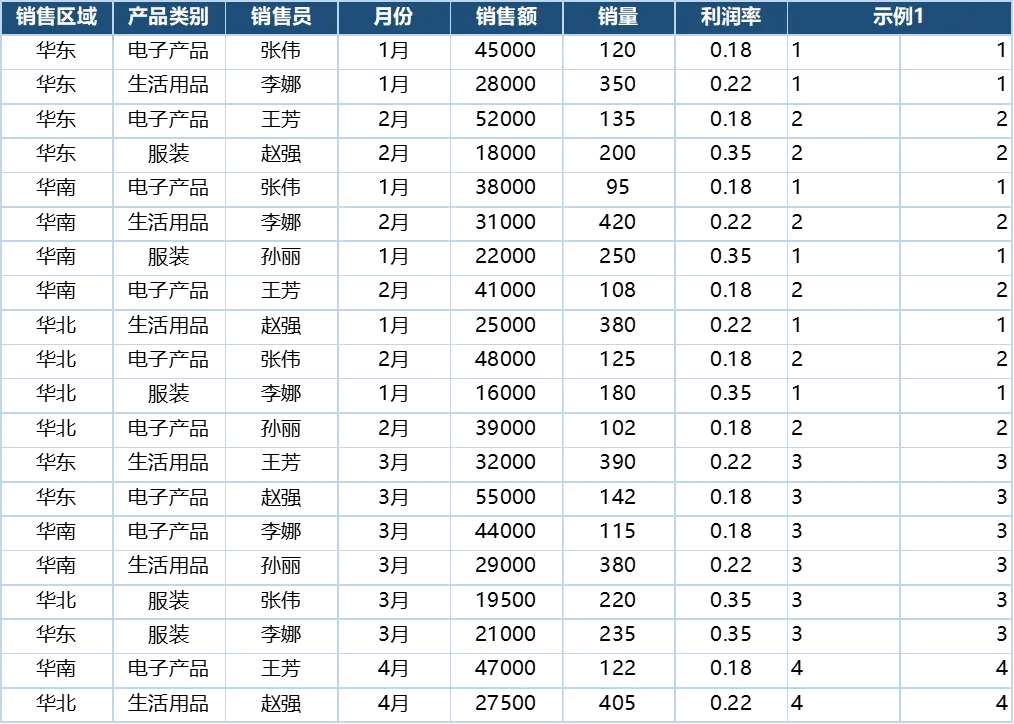
示例一:提取月份数字
“月份”列的格式为 数字+汉字(如 1月、2月),其中数字占 1 个字节,汉字占 2 个字节。要得到纯数字,只需截取第 1 个字节即可。
=MIDB(D2,1,1) // 结果:1(字符类型)=VALUE(MIDB(D2,1,1)) // 若需数值,可套用 VALUE()结果:
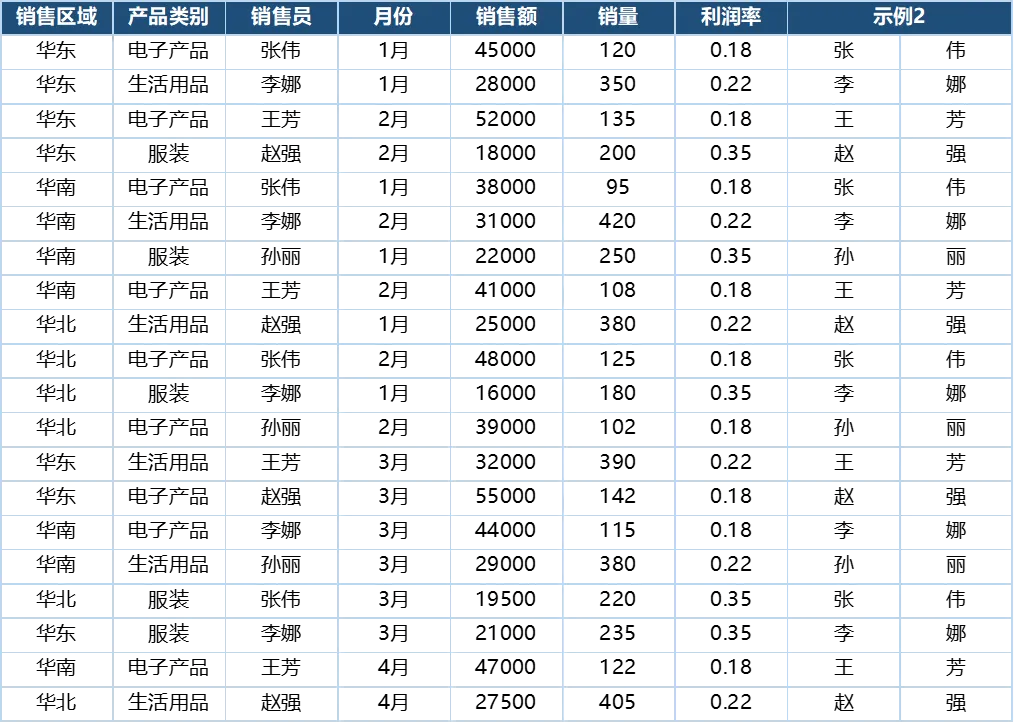
示例二:拆分销售员姓名
“销售员”列全部为 两字中文姓名,每个汉字 2 字节。
• 姓氏 = 第 1~2 字节 • 名字 = 第 3~4 字节
=MIDB(C2,1,2) // 提取姓:张=MIDB(C2,3,2) // 提取名:伟结果:
若想把姓名重新组合,可使用 & 或 CONCATENATE:
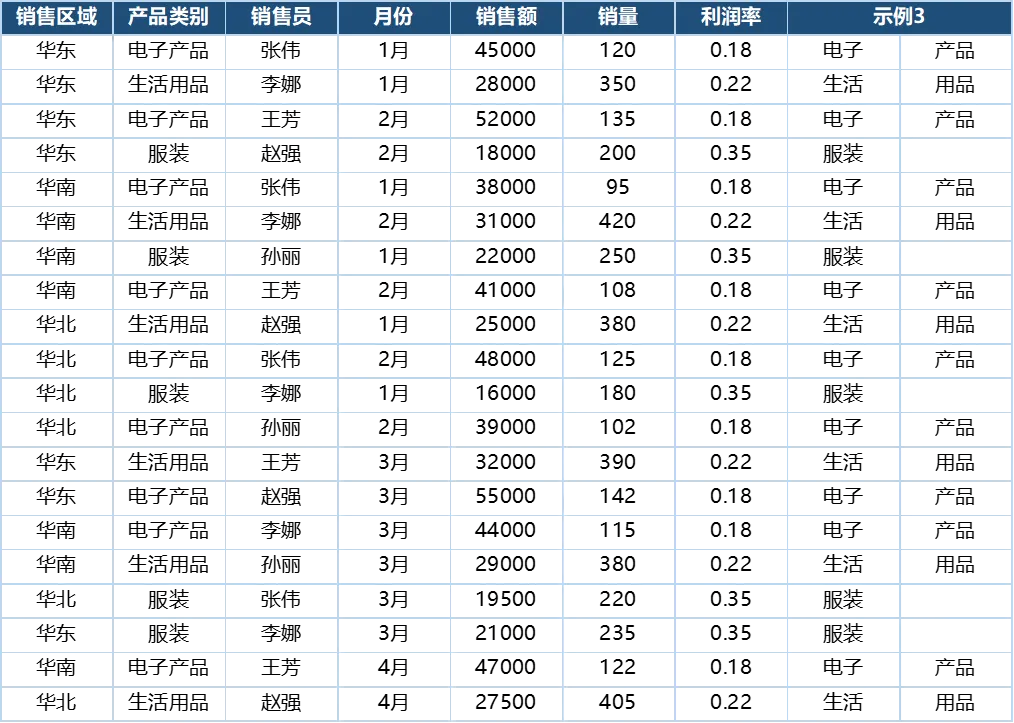
=C2 // 原姓名=MIDB(C2,1,2)&MIDB(C2,3,2) // 张伟(与原数据相同)示例三:提取产品类别前后缀
“产品类别”列的常见结构为 两字前缀 + 两字后缀(如 电子+产品、生活+用品、服装+服装)。
• 前缀 = 第 1~4 字节(即前 2 个汉字) • 后缀 = 第 5~8 字节(即后 2 个汉字)
=MIDB(B2,1,4) // 前缀:电子 / 生活 / 服装=MIDB(B2,5,4) // 后缀:产品 / 用品 / 服装结果:
安全技巧:如果类别名称长度不统一(如仅有两字
服装),直接使用MIDB(B2,5,4)会返回空值。
常见错误
#VALUE! | start_num<1 或 | LENB(text)。 |
MID 当成 MIDB,在双字节字符下长度不匹配 | MIDB,英文字符可用 MID。 | |
num_bytes | num_bytes 为 2 的倍数,或根据实际需求取 1、2、4 等。 | |
IFERROR 或 IF 预先判断:=IFERROR(MIDB(...), "")。 |
小结
• 是处理 双字节语言(中文、日文等)文本截取的利器。 • 语法简洁: =MIDB(text, start_num, num_bytes),其中start_num与num_bytes均以 字节 为单位。• 通过 示例一(月份数字提取)可以看到它在清洗数据时的便利; • 示例二(姓名拆分)展示了如何利用字节定位精准提取姓氏与名字; • 示例三(产品类别前后缀)则体现了它在 结构化拆分 与 条件统计 中的强大灵活性。 • 记住 字节 ≠ 字符,避免混用 MID与MIDB,并善用LENB、IFERROR等函数提升公式健壮性。
掌握 MIDB,你在处理中文报表、提取编码、拆分复合字段时将更加游刃有余!
📚 配套学习资料免费领评论回复:MIDB点击公众号菜单「函数教程」,获取教程。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

