豆包AI做学术PPT实测:拿Nature论文试了一下,能追上GPT和Claude吗?
- 2026-06-03 03:58:43
组会前一晚赶PPT,答辩前改了八版排版还是丑,课题汇报的图表怎么摆都不对——这些场景,科研人应该都不陌生。
最近AI做PPT的工具越来越多,但Claude、GPT这些要么付费,要么国内访问门槛高,不是所有人都方便用。
那免费的、国内直接用的豆包,拿来做科研学术PPT,到底行不行?
我们拿了一篇Nature Medicine的论文,实测了一把👇
豆包做PPT,现在是什么水平?
综合多篇测评和我们的实际使用体验:
豆包做PPT目前免费、无水印、支持一句话生成、导出可编辑PPTX。
在国内免费工具里,下限不低,快速出个通用初稿完全够用。
但通用场景够用,不等于学术场景能打。科研PPT对逻辑严谨性、术语准确度、数据精确度、图表规范性的要求,跟普通商务汇报完全不同。
下面我们看看豆包在学术PPT上的实际表现和能力边界👇
裸测:一句话扔进去,看什么水平
测试条件
测试论文:Google Research发表在Nature Medicine上的《Toward expert-level medical question answering with large language models》(Med-PaLM 2)。
选这篇是因为它内容够复杂——涉及模型架构、多种训练策略、多个数据集的实验对比、人机评测等。
如果豆包能把这篇讲清楚,其他常规论文基本不在话下。
测试场景:论文汇报PPT,组会、读书报告、课题进展汇报中最常见的类型。
测试流程
我们按一个最普通的使用流程测了一遍,分三步:
①上传论文,让豆包“生成汇报大纲 ”
↓
②让豆包“推荐PPT风格模板,并从方案中选定最适合的一种 ”
↓
③按模板+大纲+论文原文一键生成PPT

全程不到10分钟👇
裸测效果
豆包生成了一份9页的PPT
▼▼▼

大纲逻辑基本通,排版整洁,配色统一,整体完成度比预期高。但放到学术汇报的标准下,问题很明显:
方法论严重缩水: 核心技术只用1页简略概括,论文最重要的创新点完全没有展开 实验数据不精确: 只有概括性百分比,缺少多数据集对比 关键板块缺失: 没有研究局限性,缺少人机对比评测和临床场景分析 视觉风格不够学术: 墨绿灰配色,学术调性不够
一句话:框架有了,但方法论讲不清、数据不精确、关键板块缺失。
优化提示词后,豆包的学术PPT能到什么水平?
裸测是一句话直接生成的效果。下面我们重新设计提示词,看看豆包在学术PPT上的上限。
优化思路
做一份科研汇报PPT,本质上不是"模板好不好看",而是要让听汇报方(导师、答辩评委、基金评审)在十几分钟里看懂你这篇论文做了什么、做得怎么样。
所以PPT做得好不好,就看汇报人关心的几件事讲到位没:
主线有没有串起来
方法讲没讲明白 数据精不精确、能不能溯源 有没有自己的学术判断 结果有没有用图表讲出来
优化后效果
最终豆包输出了一份 21 页、深蓝白学术风格 的 PPT。
👇
下面我们按这几个维度逐个看,看豆包的科研PPT表现如何👇
① 主线:它能不能把整篇论文的主线讲清楚?
主线是一份汇报的骨架。
听汇报方要能在前几页就看明白:这篇论文要解决什么问题、用什么方法解决、最后得到什么结论——"背景→缺口→方法→实验→结论"串成一条线,逻辑顺了,PPT才立得住。
【裸测版】 主线感很弱——目录只是简单地按"研究背景/模型架构/实验结果/结论展望"四板块罗列,没有把整篇论文的逻辑串起来。
【优化后】 豆包做了一张技术路线图,把论文的关键步骤压在一页里,整篇论文做了哪几件事,一眼能看清。

【短板】:整体偏"论文结构重排",这张图本质上是"步骤展示",缺少"为什么这一步要接下一步"的因果说明——比如微调之后为什么还要做双策略增强、ER 和 CoR 之间是什么关系。
读者看完知道论文做了哪几件事,但不知道这些事串起来要回答什么问题。
主线是逻辑,不是流程;是"为什么这么走",不是"走了哪几步"。要把主线讲透,仍需要汇报人自己补。
② 方法:核心机制讲明白了吗?
方法是组会上最容易被追问的地方。光说"用了什么方法"远远不够,关键是把核心机制的关键步骤讲明白——怎么做的、为什么这么做。
【裸测】方法被压成 1 页带过,论文真正的核心机制基本没出现。拿去汇报,导师一问到关键方法的具体逻辑,PPT 上找不到对应内容。

【优化后】 豆包给两个核心机制各做了一张展开页,每页拆成几个关键步骤——核心方法终于有了独立页面,不再是裸测里那种"一笔带过"。

【短板】:有专属页面 ≠ 把方法讲明白。
豆包能把"步骤形状"画出来(拆成几个色块、加上箭头),但讲不透"机制为什么 work"——你能看到流程长什么样,看不到机制怎么转。
再加上排版本身也粗糙(颜色不统一、个别页有字符渲染错位、部分"流程图"其实是 3 栏卡片对比),离"讲透方法"到每一步细节,还有很明显的距离,仍需要人手动加节点和注释。
③ 数据:经得起导师追问吗?
数据是科研汇报的硬通货。空泛说"显著提升"经不起追问,精确数值 + 来源标注,才有说服力。
【裸测】 数据页只有"~95% / ~85% / ~80%"这种概括性百分比,能看出大致结论,但没有精确数值、没有数据来源,经不起追问。

【优化后】豆包把论文里的关键实验表自动转成了对比条形图——精确数值有、对比基准有、论文表号标注也有。"数据 + 对比 + 来源"一页内齐了,可溯源。
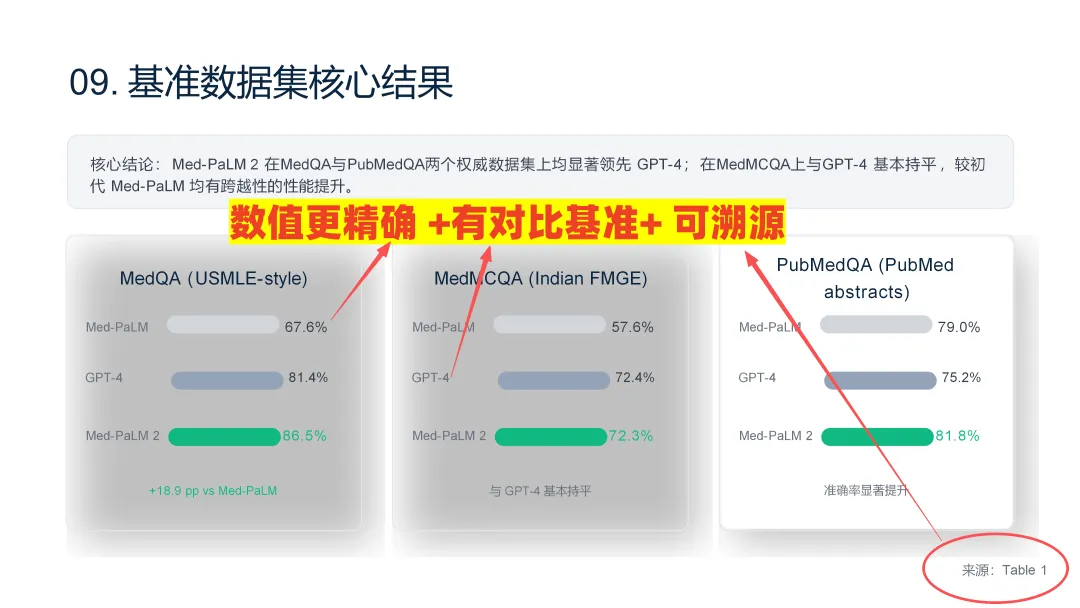
【短板】: 数据看着齐了,但不能直接信。
实测中发现,个别页面的数值跟论文原文对不上——不核对直接拿去汇报,导师追问就露馅。豆包可以帮你整理数据,但不能替你完成最后的数据审稿,这是所有AI工具的“通病”。
④ 学术判断:有没有超出"摘要搬运"?
一份合格的科研汇报,不只是"复述摘要"。除了讲清楚论文做了什么、得到什么,还要给出自己的判断——局限在哪、贡献是什么、未来怎么走。
【裸测】 完全没有"自己的判断"这一层——“研究局限、研究范式”这些板块一个都没有。
【优化后】 自动补出了"研究局限"和"研究范式"两个板块,有结构、有清单——已经不只是复述摘要。
【短板】:补出来的"局限"基本是论文作者自己写过的那些,属于"合格的摘要梳理",不是"自己的判断"。导师真正想听的是"作者不会主动挑自己刺的批判"——评测方法可信度、样本量够不够撑结论、盲法设计严不严格——这些豆包没写出来,且页面有明显文字错误。
⑤ 意外加分:它开始会用图表"讲"结果了
这一点是我们没料到的——豆包在可视化上的进展比预期明显。两方面表现尤其抢眼:👇
亮点1:自动生成科研可视化图表加入PPT中
豆包能根据论文里的数据,自动生成多种类型的可视化图表——雷达图,条形图等。这种"自动出图"的能力,是裸测里完全没有的。
把多维评估做成雷达图👇

把临床子任务对比直接画成条形图👇
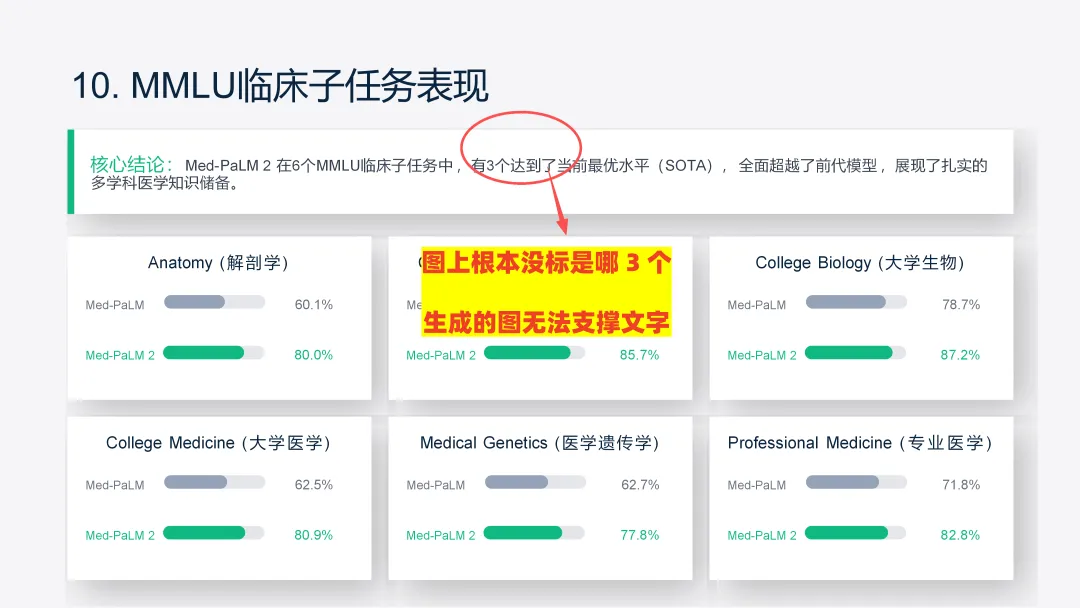
【点评】:豆包能生成"看着像可视化"的图,但图本身没真正承担"让结论一眼看出来"的功能,基本相当于摆设。画出来 ≠ 把结论讲出来。这一步还得人来收尾:给图加结论标注、做对比层级、突出关键数据点。
亮点2:能识别并截取论文原图,配上解读。
豆包能从论文里识别出关键的实验结果图,直接截取放进PPT,旁边自动配上一段解读——讲清楚图里在比什么、关键结果是什么、支撑了哪个结论。
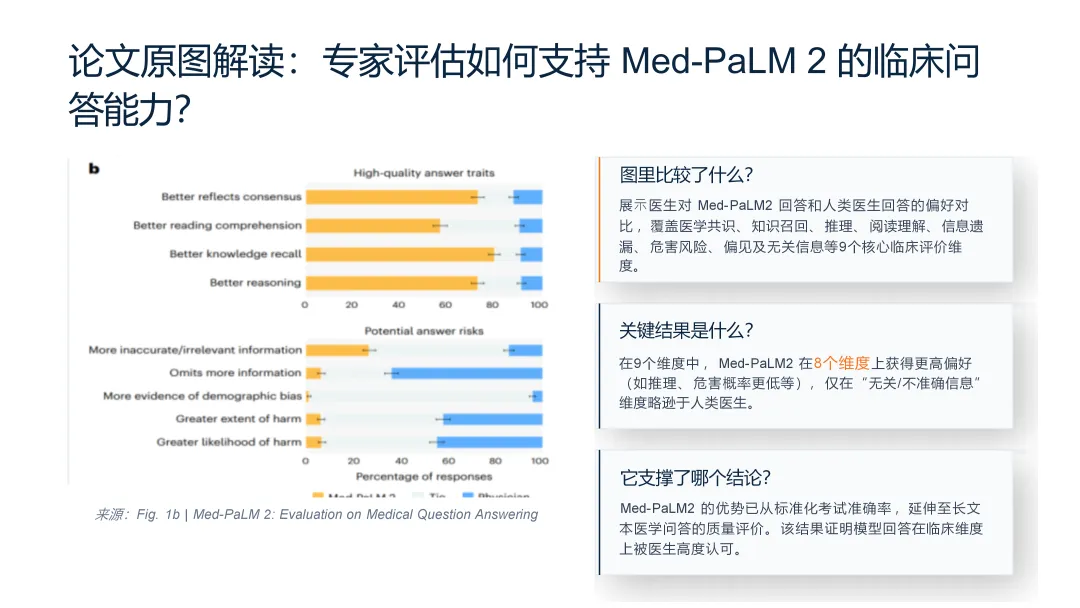
【短板】:截取的论文原图不完整,解读也偏摘要式描述——给到的关键结果基本是论文摘要里就能找到的话,没真正基于图本身做细节分析(哪一项差距最大、哪一项几乎持平、误差棒说明什么,这些"读图"内容豆包都没碰)
截图配解读 ≠ 把图讲明白,豆包能把"图 + 文字"摆在一起,但讲不透图本身要传达的信息——这一层还得人来收尾。
目前豆包做科研PPT的天花板
数据更精确了、方法有展开了、结论有图表撑了、板块也补齐了——但这不是"一句话生成"就能跑出来的,提示词得反复调。
几个目前改不了的天花板:
生成结果不稳定——同样的提示词跑两次,效果可能差很多,可控性有限 排版细节有错位——单页看着 OK,整体扫一遍能挑出各种文字遮挡、对齐问题 内容偏"教科书式概括"——缺少自己的判断和批判视角,靠它写不出"你自己的观点" 数据要逐页人工核对——整理的数值可能会出错,不能直接信
值得试试的几个实用小技巧
除了上面 5 个核心维度,实测中我们还摸索出几个豆包做 PPT 的实用技巧:
自动生成每页演讲备注稿——不用自己再写一份逐字稿 对话式"指哪改哪"——哪页不满意,直接说"把第 6 页的流程图改成纵向" 一句话换全局风格——一个指令就能换 PPT 配色和版式 导出无水印 PPTX——可以直接在 PowerPoint 里继续二次编辑
这几个用对了,能让你在汇报场景里省不少事。
光靠豆包做科研PPT,够吗?
说实话,豆包的定位很明确——零成本、最快帮你拿到一个"能看"的底
稿。组会、读书报告这种场合,提示词调一调够用了。
但答辩、基金、课题申报这种正式场景,光靠免费工具确实不够。
Claude、NotebookLM 、GPT等这类国外顶级模型在学术场景下的内容提炼和视觉呈现明显更强,而且多个工具组合使用,效果还能再上一个台阶——当然门槛和成本也高不少。
具体怎么搭配、哪套组合拳性价比最高,我们后面会单独出一篇深度横评,感兴趣可以先关注。
我们是稿研室——团队在 Nature Medicine、Lancet 发过 50+ 篇,带出的学生拿到剑桥、伯克利 offer。
这些真实走通的科研经验,我们正结合 AI 工具分享给你。👇添加微信,可领取「论文写作 AI 提示词合集」


