一、核心价值与痛点解决
传统一维转二维的局限:
用最简洁的语法实现一维数组到二维矩阵的智能转换。
二、函数语法深度解析
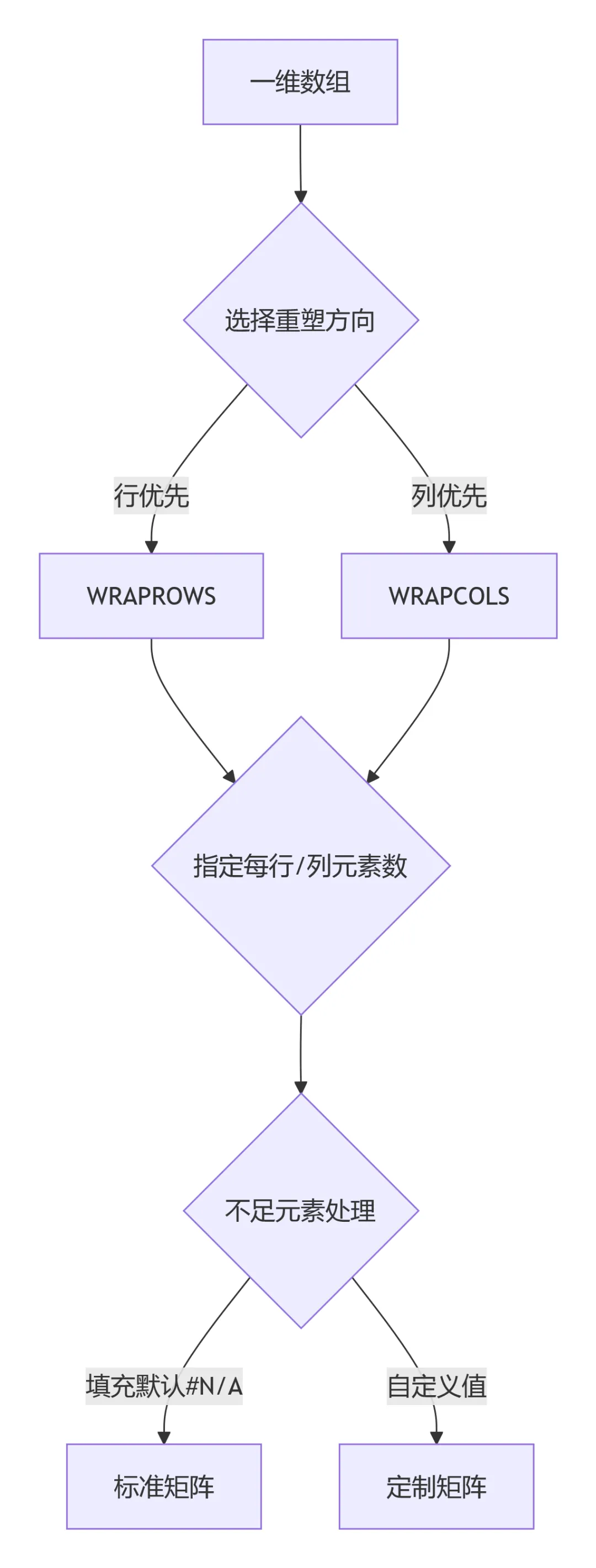
1. WRAPROWS - 按行包装(行优先)
=WRAPROWS(vector,wrap_count
,[pad_with])
功能:将一维数组按行优先顺序重塑为二维矩阵,每行包含指定数量的元素。
参数:
2. WRAPCOLS - 按列包装(列优先)
=WRAPCOLS(vector,wrap_count
,[pad_with])
功能:将一维数组按列优先顺序重塑为二维矩阵,每列包含指定数量的元素。
参数:
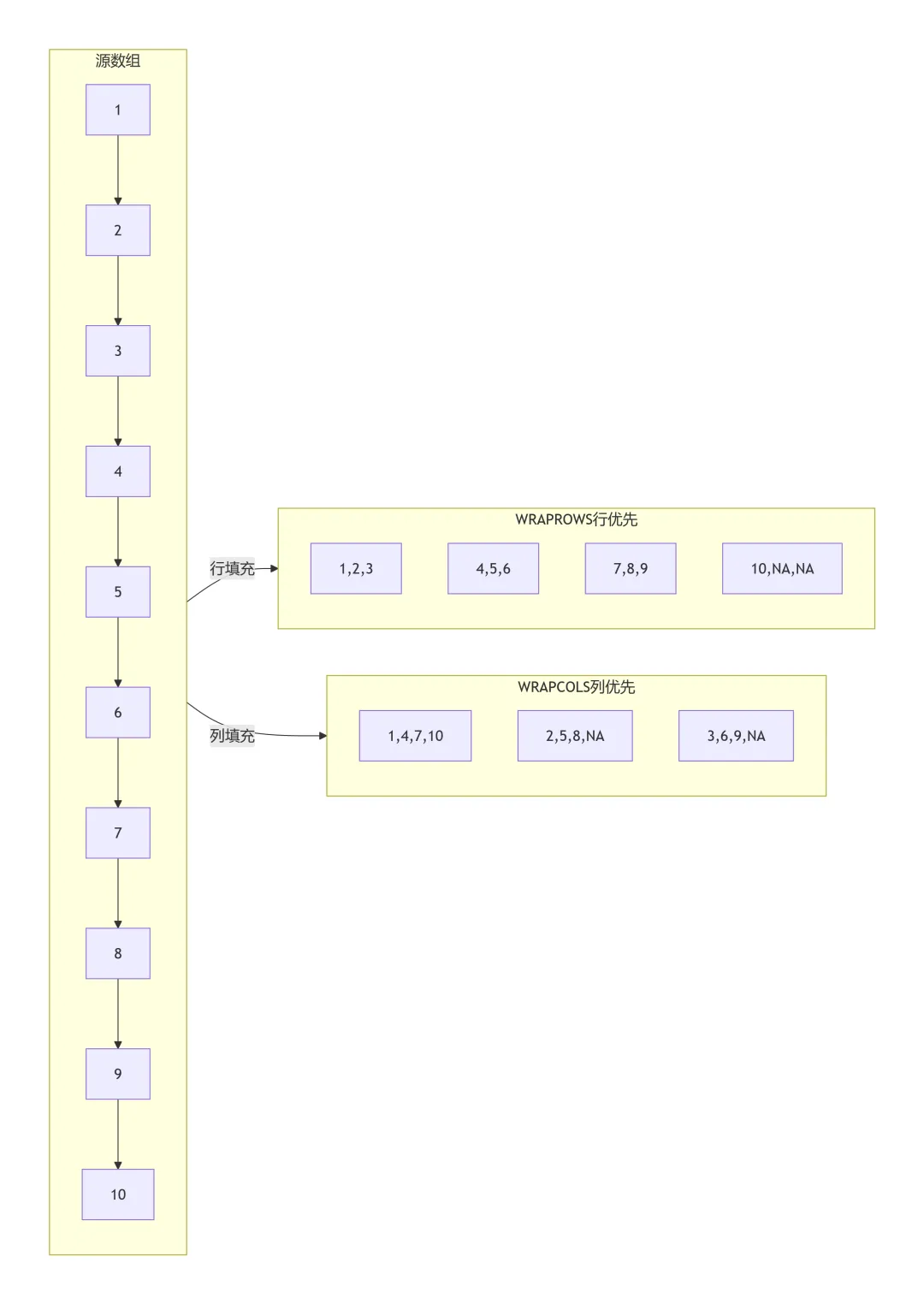
3. 核心原理可视化
源数组(一维):
[1,2,3,4,5,6,7,8,9,10]
WRAPROWS(源数组,3)
行优先(每行3列):
WRAPCOLS(源数组,3)
列优先(每列3行):
4. 行优先 or 列优先
三、五类重塑场景
1.基础一维转二维
//将A列100个数据转为10行×10列矩阵
=WRAPROWS(A2:A101,10)
//指定填充值为空字符串
=WRAPROWS(A2:A101,10,"")
2.列优先重塑
//按列填充(先填满第一列
,再填第二列...)
=WRAPCOLS(数据列,5)
//每列5行
3.动态分组
//按用户指定列数分组每行列数: B1=4
=WRAPROWS(数据列,B1)
4.转置矩阵
//将一维数组转为2行多列
=WRAPROWS(数据列,CEILING
(ROWS(数据列)/2,1))
5.自定义填充值
//不足位置填0=WRAPROWS(数据列,5,0)
//不足位置填"无数据"
=WRAPROWS(数据列,5,"无数据")
四、动态报表系统搭建
1. 参数化矩阵生成器
=LET(源数据,A2:A101,每行列数
,选择列数,填充值,IF(填充空值
="是","",NA()),WRAPROWS
(源数据,每行列数,填充值))
2. 自动分页打印器
//将长列表转为多列布局,
方便打印每页行数: 20列数: 3
=LET(data,A2:A1000
,rows_per_page,20,cols,3
,wrapped,WRAPROWS(data,cols
,""),//后续可配合TAKE/DROP
实现分页wrapped)
3. 卡片式布局
//将数据转为卡片式布局
(每张卡片N个字段)卡片字段数: 4
=WRAPROWS(平面数据,4,"")
效果:
4. 可视化流程
五、实战案例解析
1.批量生成工牌标签
需求:将员工名单(100人)按5列排版打印
=LET(员工表,A2:A101,姓名,INDEX
(员工表,,1),部门,INDEX(员工表,
,2),工号,INDEX(员工表,,3)
,合并数据,TOCOL(HSTACK(姓名
,部门,工号)),WRAPROWS
(合并数据,3,""))
2.考试座位安排
需求:将考生名单按考场座位布局排列(8列×6行)
考场容量: 48人每行列数: 8
=LET(考生名单,A2:A49,WRAPROWS
(考生名单,8,"空位"))
3.数据批量分组统计
需求:将销售数据每5个分为一组,计算每组总和
=LET(销售额,B2:B101,分组矩阵
,WRAPROWS(销售额,5,0),BYROW
(分组矩阵,LAMBDA(row,SUM(row))))
4.时间序列转日历视图
需求:将每日数据转为月历视图(按周排列)
=LET(每日数据,B2:B32,//当月1-31日
WRAPROWS(每日数据,7,""))
//结果:7列(周日至周六),
行数根据天数自动计算
六、高阶应用技巧
技巧1:TOCOL + WRAPROWS 数据清洗流水线
//将杂乱的多区域数据清洗后重塑
=LET(raw,VSTACK(区域1,区域2
,区域3),cleaned,TOCOL(raw,1)
,//忽略空值WRAPROWS(cleaned,5,""))
技巧2:动态矩阵尺寸
//自动计算最优列数(使矩阵接近正方形)
=LET(data,A2:A101,n,ROWS(data)
,cols,ROUNDUP(SQRT(n),0)
,WRAPROWS(data,cols,""))
技巧3:交错排列(蛇形填充)
//实现蛇形填充效果(第2行反向)
=LET(data,A2:A101,cols,5
,matrix,WRAPROWS(data,cols
,""),rows,ROWS(matrix)
,VSTACK(TAKE(matrix,1),
//第1行正常DROP(REDUCE("",SEQUENCE(rows-1),LAMBDA
(acc,i,VSTACK(acc,IF(
ISEVEN(i),INDEX(matrix,i+1
,SEQUENCE(1,cols,cols,-1)),
//偶数行反转INDEX(matrix,i+1
,)))),1)))
技巧4:分组聚合增强版
//每5个一组,计算平均值和标准差
=LET(data,B2:B101,grouped
,WRAPROWS(data,5,0),HSTACK
(BYROW(grouped,LAMBDA(r
,AVERAGE(r))),BYROW(
grouped,LAMBDA(r
,STDEV.S(r)))))
七、性能优化指南
与其他函数对比:
优化建议:
预清洗数据:先TOCOL清理空值再WRAP
避免过大矩阵:超过10万单元格考虑分批处理
使用LET缓存:减少重复计算
//低效
=SUM(BYROW(WRAPROWS(A2:A101,5)
,LAMBDA(r,SUM(r))))
=AVERAGE(BYROW(WRAPROWS(A2:A101
,5),LAMBDA(r,SUM(r))))
//高效
=LET(wrapped,WRAPROWS(A2:A101
,5),row_sums,BYROW(wrapped
,LAMBDA(r,SUM(r))),HSTACK(
SUM(row_sums),AVERAGE(row_sums)))
八、避坑指南
错误1:源数据非一维
错误:源数据是多行多列
=WRAPROWS(A2:C10,3)
//实际是3列×9行,不是一维
正确:先用TOCOL转为一维
=WRAPROWS(TOCOL(A2:C10,1),3)
错误2:wrap_count为0或负数
错误:参数无效
=WRAPROWS(数据列,0)
//VALUE!
正确:wrap_count至少为1
=WRAPROWS(数据列,MAX(1,用户输入))
错误3:填充值类型不匹配
问题:源数据为数字,填充值为文本
=WRAPROWS({1;2;3},2,"空")//混合类型,建议:保持类型一致
=WRAPROWS({1;2;3},2,0)//数字填充
=WRAPROWS({"A";"B";"C"},2,"")//文本填充
错误4:数据量巨大导致溢出
问题:10万行数据每行100列
1000万单元格
=WRAPROWS(A2:A100001,100)
解决方案:1.分批处理
2.使用Power Query
3.增加辅助列分页
九、行业应用场景
教育培训
//考场座位表生成
=LET(考生,学生名单,考场列数,8
,WRAPROWS(考生,考场列数,"缺考"))
零售管理
//商品货架陈列图
=WRAPROWS(商品编码列表
,货架层板容量,"空位")
生产制造
//批次追踪矩阵每托容量: 24
=WRAPROWS(批次号列表,每托容量,"")
数据分析
//时间序列重采样(日转周)
=LET(日数据,B2:B366,周矩阵
,WRAPROWS(日数据,7,0),BYROW
(周矩阵,LAMBDA(week
,AVERAGE(week))))
十、总结
核心公式:
=WRAPROWS(一维数组
,每行列数,[填充值])
//行优先
=WRAPCOLS(一维数组
,每列行数,[填充值])
//列优先
参数速记:
WRAPROWS:先填满一行,再换行(像打字)
WRAPCOLS:先填满一列,再换列(像爬楼)
最佳搭档:
工作流示意:
终极验证:
=LET(data,SEQUENCE(12)
,rows_wrap,WRAPROWS(data,4)
,cols_wrap,WRAPCOLS(data,4)
,"行优先:"&TEXTJOIN(",",TRUE,INDEX(rows_wrap,1,))
&"列优先:"&TEXTJOIN(",",TRUE,INDEX(cols_wrap,1,)))
输出:行优先:1,2,3,4 列优先:1,5,9 → 重塑方向验证成功!