Google推出的NotebookLM与开源项目Bana-Slides,代表了AI辅助内容生产的两个方向。前者是知识管理工具向演示场景的延伸,后者则是原生为视觉输出设计的生成系统。
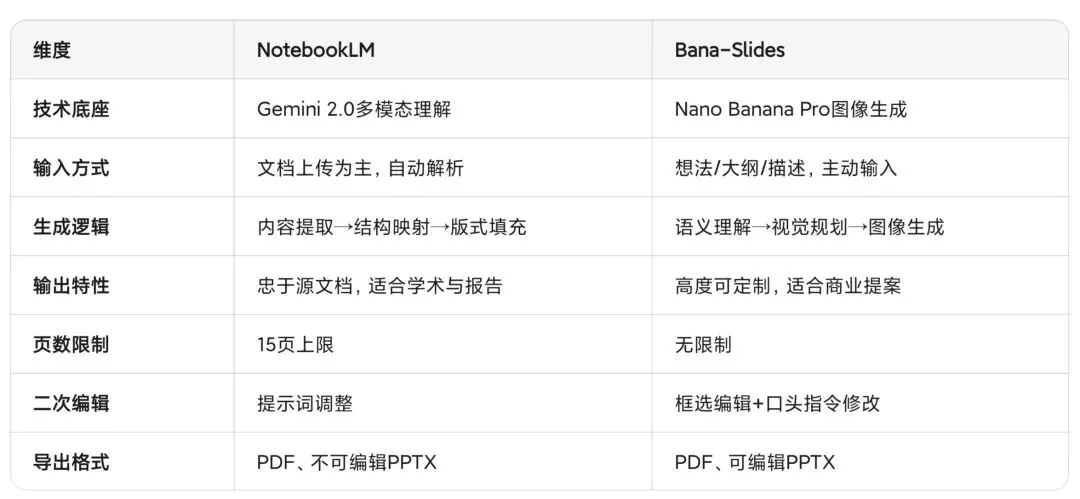
NotebookLM的核心架构建立在Gemini的多模态理解能力之上。它的功能本质上是文档分析的副产品——系统先深度解析用户上传的PDF、网页或视频内容,提取关键论点与数据关系,再将这些结构化信息映射到预设的版式模板中。这种路径的优势在于内容准确性:由于生成过程依赖于对源材料的深度理解,而非简单的关键词提取,输出的页面往往能保留原始文档的逻辑链条与数据细节。
Bana-Slides则采用了完全不同的技术路线。该项目基于Google的Nano Banana Pro图像生成模型构建,核心创新在于将PPT页面视为图像生成任务而非文档排版任务。系统接收用户输入的主题、大纲或页面描述后,直接调用多模态模型生成高分辨率的页面视觉,包括布局、配色、图表乃至文字渲染。这种方法突破了传统PPT工具"模板+填充"的范式,实现了真正意义上的"从零设计"。
NotebookLM更适合已有成熟文档、需要快速转化为演示形式的学术研究者或分析师;Bana-Slides则服务于从零开始构思、对视觉风格有特定要求的商业用户或创意工作者。
理解这两款工具的差异,需要回到AI生成PPT的技术本质。当前主流方案已超越早期的"模板匹配+文本填充"模式,进入多模态生成阶段。
内容理解层是系统的基础。
无论是NotebookLM的文档解析还是Bana-Slides的大纲扩展,都依赖大语言模型对输入语义的深度把握。
视觉规划层决定了页面的信息架构。
传统工具使用固定模板,而AI生成系统会根据内容语义动态规划布局。
渲染生成层是技术差异最大的环节。
NotebookLM采用的是"组件组装"策略:将规划好的内容映射到预设计的组件库,最终导出为结构化文档。Bana-Slides则使用端到端的图像生成,模型直接输出完整的页面像素,包括文字渲染、图形绘制和背景纹理。
值得注意的是,Bana-Slides近期迭代中加入了"可编辑PPTX导出"功能。这项技术通过OCR识别生成图像中的文字区域,再将其转换为PowerPoint原生文本对象,试图在视觉质量与编辑灵活性之间寻找平衡点。
Bana-Slides在GitHub上以AGPL-3.0协议开源,但其技术架构决定了它无法成为传统意义上的"自由软件"。项目的核心依赖——Nano Banana Pro——是Google的闭源商业模型,需要通过API密钥调用。这意味着即使代码完全开放,用户仍需为模型使用付费,且受限于Google的API服务条款与定价策略。
这种"开源外壳+闭源核心"的模式正在成为AI应用的新常态。开发者开源前端界面与业务逻辑,但将计算密集型任务委托给商业API。对于Bana-Slides而言,这种模式带来了两个直接后果:部署门槛与商业使用的灰色地带。
相比之下,NotebookLM作为Google官方产品,虽然功能受限,但在服务稳定性与合规性上更具优势。这种"官方封闭但可用"与"社区开放但昂贵"的张力,构成了当前AI工具生态的基本格局。
NotebookLM与Bana-Slides的技术路径,本质上是"理解优先"与"生成优先"两种AI哲学的具象化。前者试图让机器先读懂世界,再辅助表达;后者则让机器直接承担表达本身。
无论选择哪条路径,使用者都需要清醒认识到:AI生成的是幻灯片,而非思想。当效率提升到极致,人类的价值将愈发体现在提出正确问题的能力,以及对生成内容的批判性审视上。工具越强大,使用者的主体性就越珍贵——这或许才是这场效率革命留给我们最严肃的命题。
本文部分技术细节参考了Bana-Slides官方GitHub文档及台湾大学Computer Center的NotebookLM应用研究。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
