继续我们的探索之旅,今天将深入探讨LatticeMind旗下的ExcelAgent产品模块的构建理念。首先,让我们简要回顾一下业务背景。LatticeMind 设有 AI 审核专项子模块,该模块的核心竞争力体现为:依托用户自定义审核策略簇与上下文信息,对附件内容及其与用户上下文的关联逻辑开展综合验证。模块通过匹配策略簇内具体策略完成核验,并以 “审核通过” 或 “审核驳回” 呈现最终结果,有效保障审核流程的风险控制。与此同时,ExcelAgent 凭借强大的 Excel 分析功能,为 AI 审核、预算控制等上游业务场景提供稳固的基础服务支持。以此作为LatticeMind下Agent建设技术方案开篇,主要基于两点考量:- Excel 数据分布规律清晰,解析时可围绕单元格、工作表两大核心单元,形成大文件分块与分组的标准化分析思路。
- 相较于其他附件类型,Excel 数据噪声更低,关键信息提取更容易。
我们先来看下真实存在于excel中数据风格有哪些:想象一下,你有一张 50000 行的销售明细表,要让 AI 帮你审核。如果直接把整张表发给模型进行分析:
成本爆炸:针对策略,每次都通篇将附件内容喂模型,产生高昂的token费用
效率低下:模型要读完所有数据才能开始思考,速度很慢
容易出错:太多无关数据会干扰模型的判断
所以我们需要一种方法:让 AI 先理解表格结构,需要时再精确查询数据。
传统做法:把整张 Excel 一股脑发给 AIAI,这是 50000 行数据,帮我检查有没有问题[发送 50000 行完整数据...]我们的做法:先发结构,按需查数据AI,这张表有 3 列(姓名、金额、日期),共 50000 行数据你需要查什么,告诉我,我给你取1.保留重要结构信息Excel不只是数据表格,它还有很多"文档特征",例如: | |
| A1:C1 = "2024年销售明细表" |
| 第 2 行 |
| 第 3 行 |
| A=姓名, B=金额, C=日期 |
为什么这样做?因为这些结构信息能帮 AI 快速理解"这是什么表",而不用逐行阅读。Excel 最大的浪费是什么?空白单元格,例如:一张 1000 行 × 50 列的表格,理论上有 50000 个单元格。但实际上可能只有 500 个格子有数据,其他都是空的。```json{ "A1": "张三", "B1": "100", "C1": "", "D1": "","E1": "", ... "T1": ""}```
{ "A1": "张三", "B1": "100"}
如果 1000 行数据,每行都要写 "姓名"、"金额"、"日期"这些列名,太浪费了。```json{ "第1行": { "姓名": "张三", "金额": "100", "日期": "1/15" }, "第2行": { "姓名": "李四", "金额": "200", "日期": "1/16" }, "第3行": { "姓名": "王五", "金额": "300", "日期": "1/17" }, ...}```
```json"列字典": ["姓名", "金额", "日期"]```
```json[ [1, 0, "张三", 1, "100", 2, "1/15"], [2, 0, "李四", 1, "200", 2, "1/16"], [3, 0, "王五", 1, "300", 2, "1/17"]]```
解读第一行:- `1` = 第 1 行- `0` = 第 0 列(姓名)- `"张三"` = 值- `1` = 第 1 列(金额)- `"100"` = 值- `2` = 第 2 列(日期)- `"1/15"` = 值
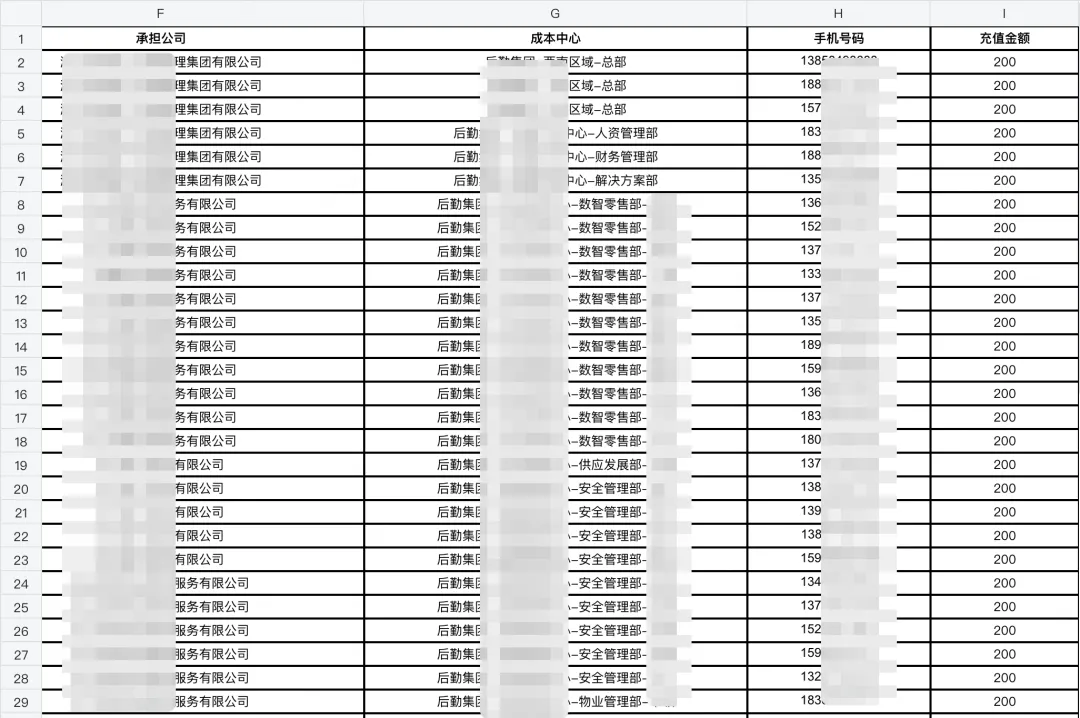
节省了多少?如果列名平均 3 个汉字(6 字节),1000 行 × 3 列 = 18000 字节。压缩后只需要存 1000 行 × 3 个数字(每个 1 字节)= 3000 字节。节省了 83% 的空间。基于压缩后的数据结合用户上下文以及策略簇交给模型判断具体需要的审核策略有哪些。 在单一审核场景中,策略簇内通常包含50 条以上审核策略。若直接交由大模型进行判断,System Prompt 往往只能给出简单的思维链指引:“先识别可能命中的策略,再逐条对照策略检查附件内容并给出审核结果”。但同一场景下不同策略的审核重点各不相同,大量策略会显著分散模型注意力,影响判断准确性。此外,即便对文件内容做了压缩处理,由于缺乏清晰的执行指引,模型在数据分析与策略匹配过程中仍会出现大量无效推理,导致效率低下。 最后,如果你是一个精打细算的人,我以Qwen3.5-plus为例,模型输入的价格是输出的1/6。如果你可以顺利开启显(隐)式缓存,那么这个输入的价格会更低,所以比起大篇幅的总结输出,仅规则的产出可能从审核准确率和经济角度看都是更好的选择。 excel说明书,ok,我们又开始"省钱"了,首先对于多sheet的excel(目前遇到的最多是单个excel拥有45个sheet),考虑一个点,我们应该每个sheet都交给模型分别去执行获取其对应的索引么?显然不是,这种方式潜在的风险是流控和处理时间。笔者采用了贪心算法,对多sheet进行分组,如果多个sheet的字符数相加接近设定阈值,那么这一组的sheet就分配完毕,他们会一起交给模型,产出sheet级别的索引。还记得第一章那个信息重复度很高的sheet么,它的索引是这样(为了方便理解,这里json的key并没有压缩,实际的key更短):{ "sheetRef": "s1", "sheetName": "Sheet1", "rowCount": 29, "columnCount": 4, "titleRegions": [ {"value": "承担公司","rowStart": 1, "rowEnd": 1, "colStart": 6,"colEnd": 6,"type": "main_title","level": 1 }, {"value": "成本中心","rowStart": 1, "rowEnd": 1, "colStart": 7,"colEnd": 7,"type": "main_title","level": 1}, {"value": "手机号码","rowStart": 1, "rowEnd": 1, "colStart": 8,"colEnd": 8, "type": "main_title","level": 1}, {"value": "充值金额","rowStart": 1, "rowEnd": 1,"colStart": 9,"colEnd": 9,"type": "main_title","level": 1} ], "headerAnalysis": {"headerRowNum": 1,"dataStartRow": 2,"isMultiRowHeader": false}, "columns": [ {"colKey": "F","header": "承担公司","colIndex": 1}, {"colKey": "G", "header": "成本中心","colIndex": 2}, {"colKey": "H","header": "手机号码", "colIndex": 3}, {"colKey": "I","header": "充值金额","colIndex": 4} ], "tableDescription": "这是一张手机充值明细表,包含承担公司、成本中心、手机号码和充值金额等信息" }
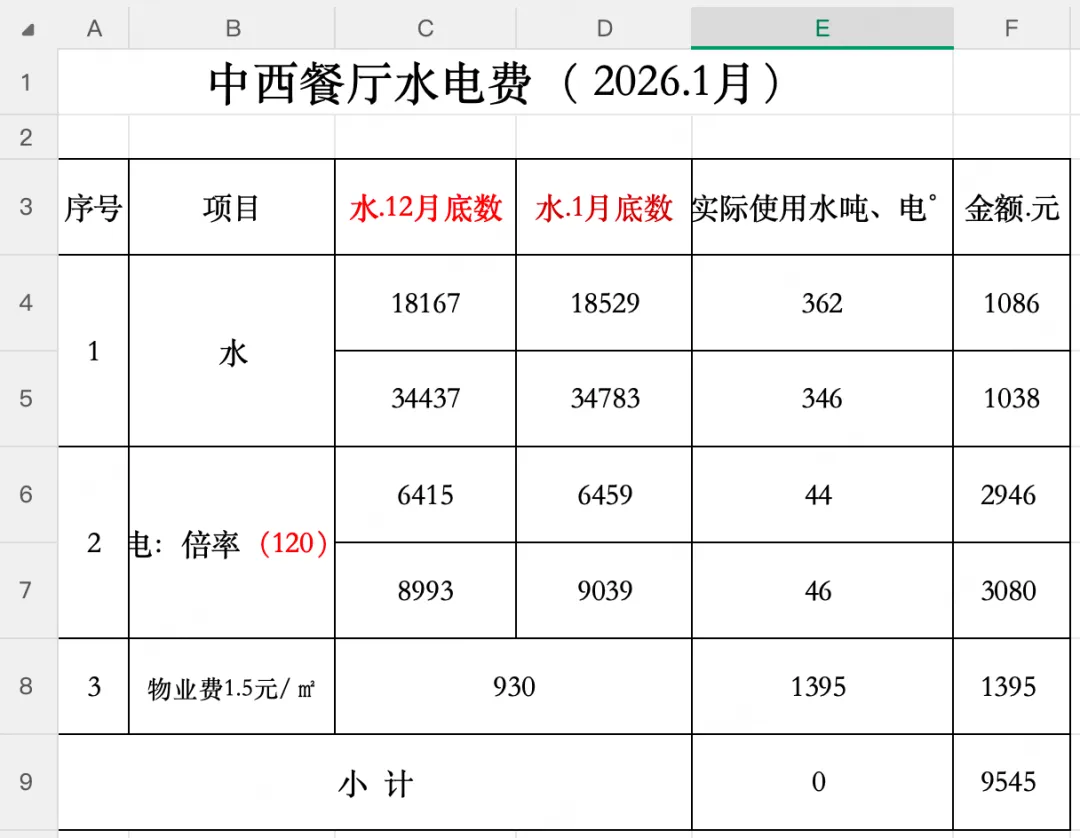
第一章表格标题分布自由的例子,这种情况的索引密集度是远远大于数据密集度的。{ "sheetRef": "s1", "sheetName": "中西餐厅水电费", "rowCount": 9, "columnCount": 6, "titleRegions": [ {"value": "中西餐厅水电费(2026.1月)","rowStart": 1,"rowEnd": 1,"colStart": 1,"colEnd": 6,"type": "main_title","level": 1}, {"value": "小计","rowStart": 9,"rowEnd": 9,"colStart": 2,"colEnd": 3,"type": "summary_row","level": 2} ], "headerAnalysis": {"headerRowNum": 3,"dataStartRow": 4,"isMultiRowHeader": false}, "columns": [ {"colKey": "A","header": "序号","colIndex": 1}, {"colKey": "B","header": "项目","colIndex": 2}, {"colKey": "C","header": "水.12月底数","colIndex": 3}, {"colKey": "D","header": "水.1月底数","colIndex": 4}, {"colKey": "E","header": "实际使用水吨、电°","colIndex": 5}, {"colKey": "F", "header": "金额.元","colIndex": 6} ], "tableDescription": "这是一张中西餐厅2026年1月水电费用明细表,包含水、电、物业费三个项目的期初期末读数、实际用量和金额,并带有小计汇总行" }
既然存在多个sheet的贪心聚合,那有没有可能一个sheet的内容就超过了阈值上限呢?当然,这种情况可以采用二分查找的思路处理,先对sheet内容横向一切为二,通过工具:searchLine,他的参数只有:rowNumber和searchLimit,其中rowNumber表示开始查询的行起点位置,searchLimit表示从起点位置查询的行数量5,10,20。通过双向的查找(比如,一共100行数据,横向切分后,其中0~49和50~99分为两组。searchLine会分别从49的位置向上查找,以及50的位置向下查找)确定索引首次出现所在的行,将sheet按完整分布信息重新切割。这个loop的过程,采用30B的模型足以完成工作。现在万事俱备只欠东风,需要为前面构建的索引和命中的策略们装上工具,聪明的大脑就可以Run起来了。对此我设计了如下基础查询工具供AgentLoop分析使用: |
| |
queryByHeader | 在 Excel 数据中按列头条件查询。支持精确匹配、数值比较(>、<、>=、<=)和模式匹配(contains)。多条件默认 AND 逻辑,可通过 logicOp 切换为 OR。适用于 "查 XX 部门的员工"、"找金额大于 10000 的记录" 等场景。 |
| 按行 / 列范围查询 Excel 数据。适合获取特定区域的数据,如 "前 10 行数据"、"第 3 列到第 8 列"。也支持只查询指定的几列。 |
| 在 Excel 数据中按列头模糊查询(正则匹配)。适用于不确定完整值的场景,如 "查所有姓王的员工"、"包含北京的部门"。使用正则表达式匹配,不区分大小写。 |
| 对 Excel 数据中的数值列进行聚合计算。支持 sum(求和)、count(计数)、avg(平均值)、min(最小值)、max(最大值)。可按指定列分组聚合。适用于 "计算总金额"、"按部门统计人数"、"求各区域平均工资"、"按人员汇总充值金额" 等场景。 |
| 获取 Excel 中指定行的完整数据。适用于已知行号、需要查看该行全部字段的场景。 |
| 获取 Excel 中表头行(或指定行)的内容。用于确认表格有哪些列、列名是什么。不传 rowNum 时返回表头行(通常是第 1 行)。 |
| 搜索 Excel 表格中包含关键词的列名。适用于不确定列名完整写法、需要查找相关字段的场景。如搜索 "金" 可能找到 "金额"、"奖金" 等列。 |
| 获取已解析 Excel 文件的索引信息,返回文件包含的 sheet、表头位置、列名列表、标题层级关系等元数据。在查询具体数据前,先调用此工具了解文件结构。 |
我们已经可以成功实现让AI依据策略内容和索引,灵活地结合工具查询所需数据,并在AgentLoop的每一步中进行验证。这种按需获取数据的方式,确保了每次工具交互仅提取特定sheet中的局部数据,从而有效控制了工具执行的上下文质量。 在未来的文章中,我们会放大下面这些问题,延续对这些问题在AI建设上的讨论:- 附件名字带有一些关键线索,但是命名往往不规范,比如有特殊符号,空格,在使用上有什么需要注意的地方?
- AgentLoop阶段一个step是否应该只对一个sheet进行审核?
聊一聊ReAct,AgentLoop,Ralph Loop的真实落地场景