1个Excel难题,今天终于有解了,让效率提升90%
- 2026-06-02 23:30:44
每天被 Excel 数据匹配折磨的人,举个手🙋♂️
名字差一个字、地址少一个符号、公司名称缩写不一样……明明是同一条数据,VLOOKUP 死活匹配不出来,手动核对到眼睛发酸,效率低到崩溃。
今天给你们终极的解法!只需一串公式,快速搞定相似度匹配,效率直接拉满 90%。效果如下图
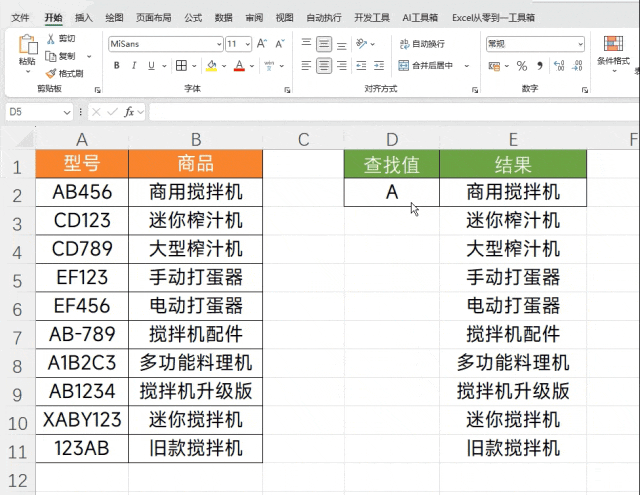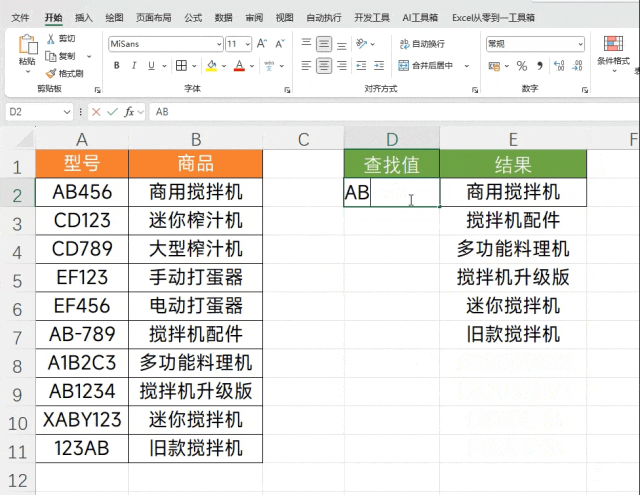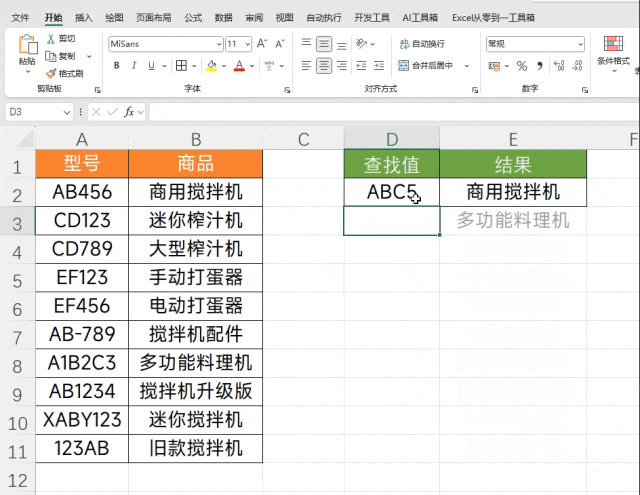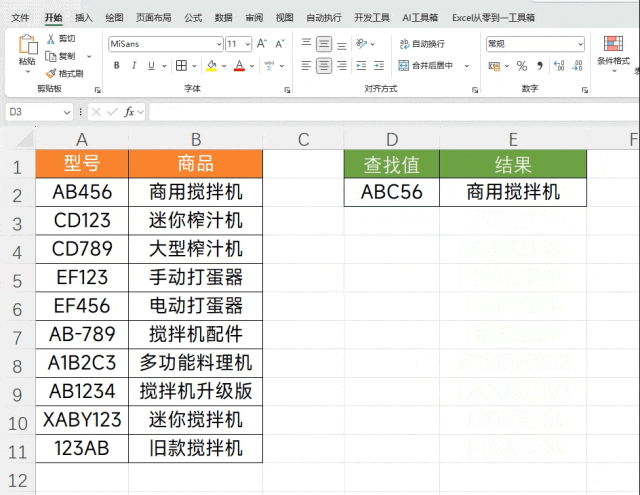
一、拆分数据
公式:=REGEXEXTRACT(A2,"["&D2&"]",1)
在这列D2是查找值,我们查找值的前后连接方括号作为正则的匹配规则,它就表示会在数据源中匹配【ABC2】这四个字符,如果可以匹配到就会返回对应的字母,具体效果如下图所示
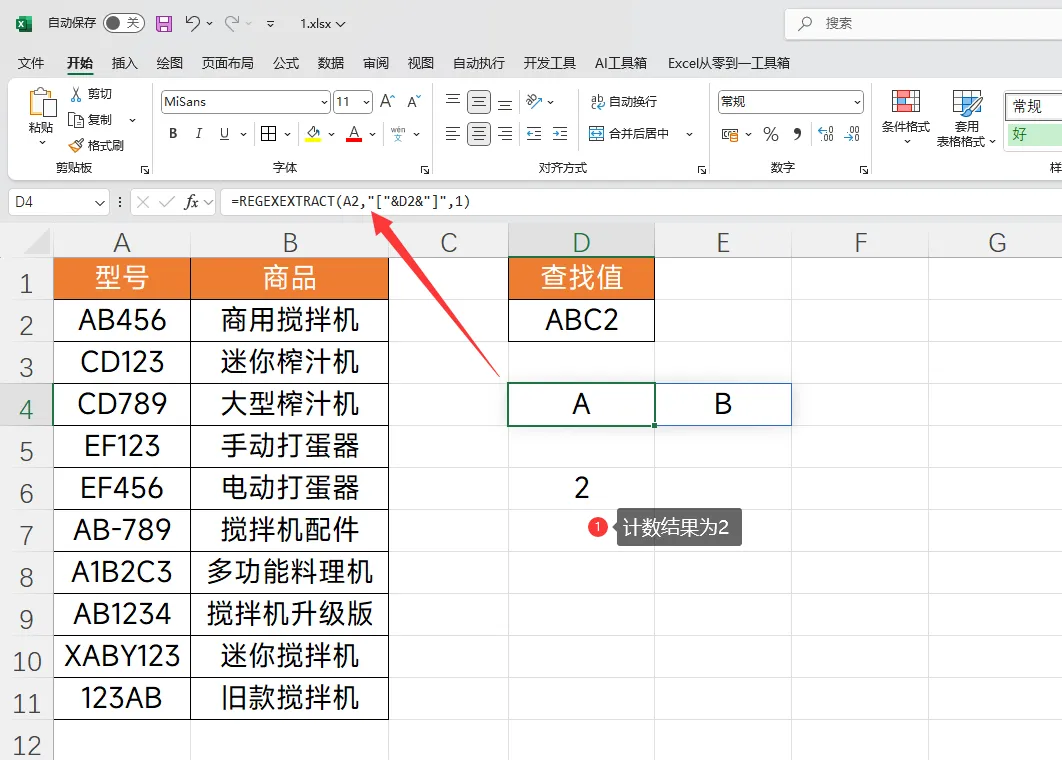
得到了字母就可以使用COUNTA函数对这个区域进行计数,来得到数据提取的个数
公式:=COUNTA(REGEXEXTRACT(A2,"["&D2&"]",1))
二、公式扩展
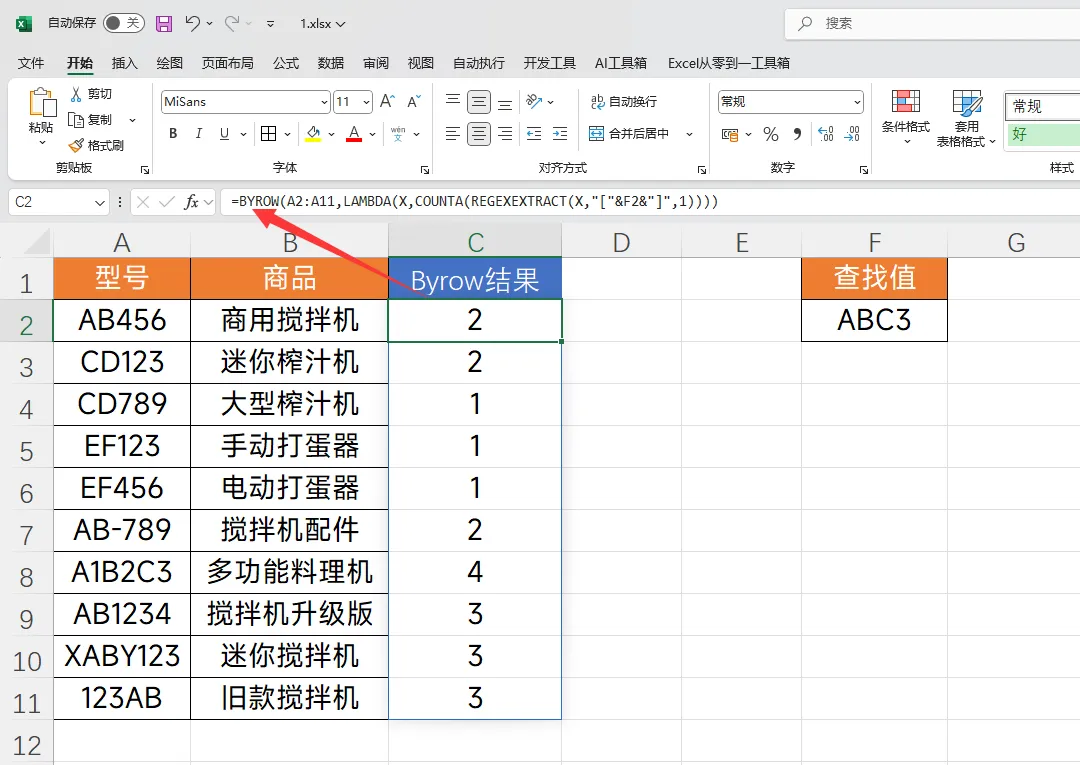
上面演示的仅仅是一个结果,我是要对整列的数据进行比较,所以就需要对这个公式进行扩展,让他对一整列的数据进行计数,就可以考虑使用BYROW,它的作用是将函数应用于整行中,结果如下图所示
公式:=BYROW(A2:A11,LAMBDA(X,COUNTA(REGEXEXTRACT(X,"["&F2&"]",1))))
这个公司的关键点就是将A2:A11这区域代入到正则函数中,对整行数据进行拆分计数,在当前的表格中最大的数据,就是我们需要的最相似的数据
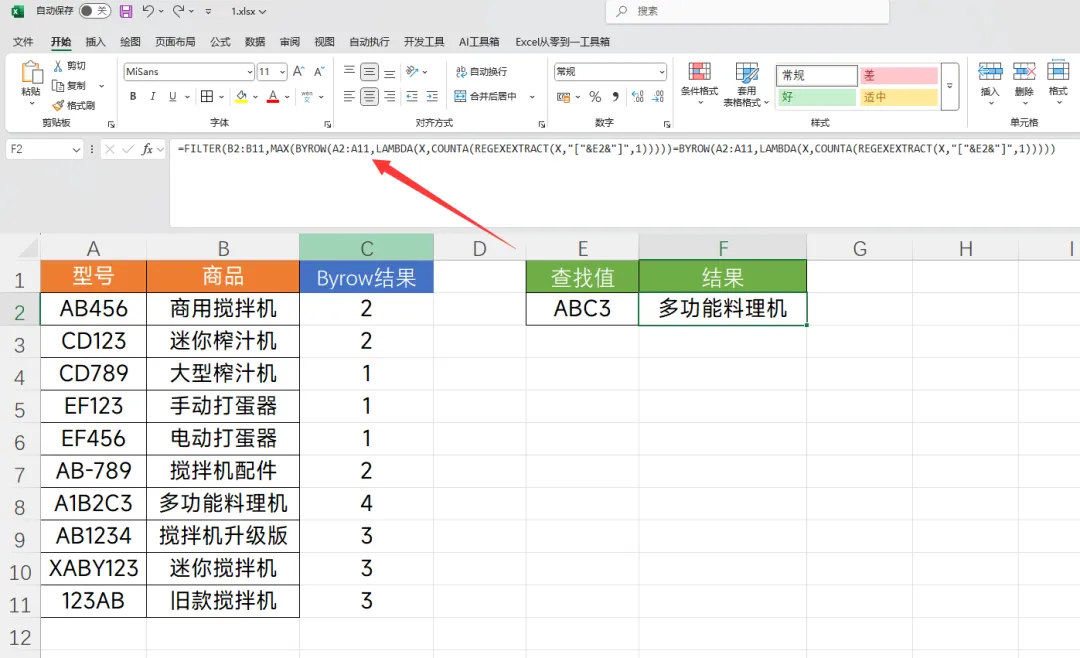
三、提取数据
公式:=FILTER(B2:B11,MAX(BYROW(A2:A11,LAMBDA(X,COUNTA(REGEXEXTRACT(X,"["&E2&"]",1)))))=BYROW(A2:A11,LAMBDA(X,COUNTA(REGEXEXTRACT(X,"["&E2&"]",1)))))
公式虽然比较长,但是并不难理解,主体是一个FILTER函数来做数据筛选,我们使用MAX函数提取计数结果来得到最大值,最大值对应的就是最相似的数据
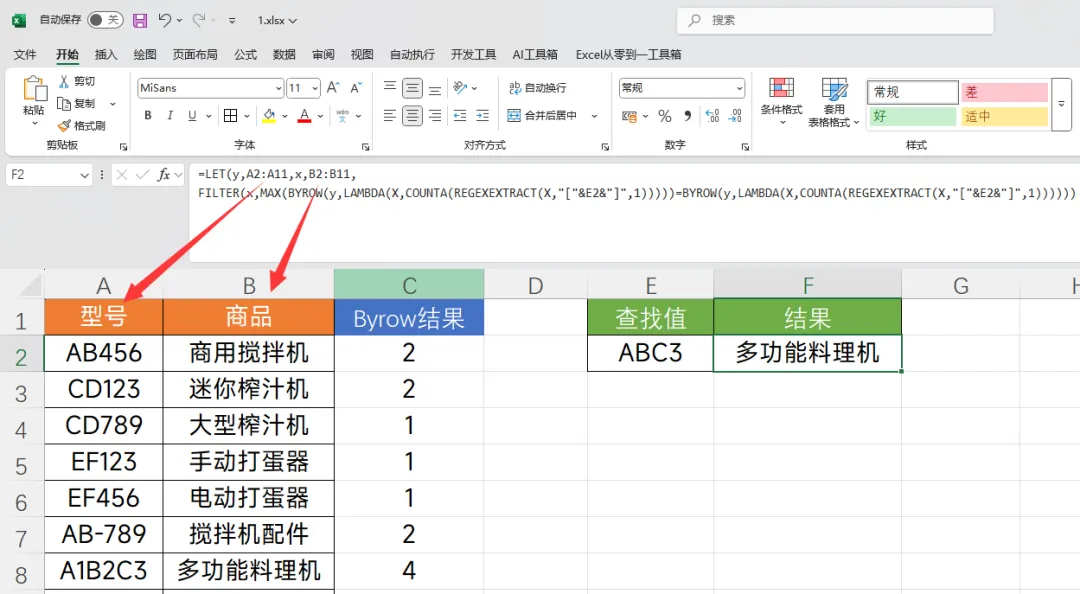
四、直接套用
这个函数想要看懂还是需要有一定的基础的,如果你看不懂也没关系,粘贴下方公式直接使用,只需要修改2处即可
公式=LET(y,A2:A11,x,B2:B11,FILTER(x,MAX(BYROW(y,LAMBDA(X,COUNTA(REGEXEXTRACT(X,"["&E2&"]",1)))))=BYROW(y,LAMBDA(X,COUNTA(REGEXEXTRACT(X,"["&E2&"]",1))))))
1. A2:A11修改为你表格的查找列
2. B2:B11修改为你的表格的结果列
五、注意事项
使用这个函数,大家需要注意2点,不然有可能会造成无法使用的情况
1. 如果你是WPS,请将REGEXEXTRACT替换为REGEXP,它们的名字不一样,用法是一样的
2. 查找值不要添加任何的标点符号,如果你的标点符号恰好是正则中的元字符,这个函数就无法使用了
想学跟我Excel,可以在下方了解下我的课程,函数、透视表、图表、数据看板、AI都有,购买后免费答疑,点击下方链接了解详情

Excel系列课程(Deepseek、函数、透视表、图表、数据看板)

END

