第5课:3个python操作,让Excel数据透视表秒变咨询公司级图表!
- 2026-04-13 00:12:00
第5课:3个python操作,让Excel数据透视表秒变咨询公司级图表!
(想象这是一张包含数万行数据的表格:sales) 
✨ 运行结果: 
(注:

(所有低于 1 万的格子自动变成粉红色背景 + 深红字,老板一眼就能看到哪里需要改进!) 第3步:计算“同比增长率”并保留小数 痛点三: 算增长率公式容易写错,而且 Excel 默认的小数位数乱七八糟(有的3位,有的0位)。解法: Pandas 直接计算,并用 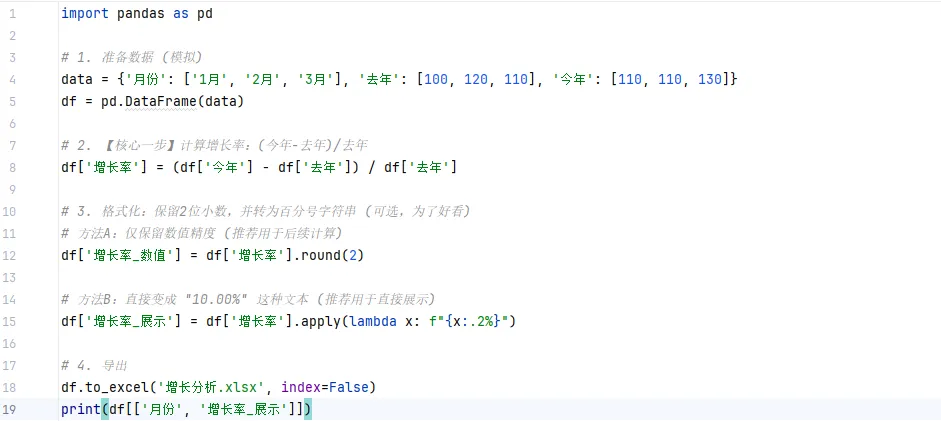
✨ 运行结果:
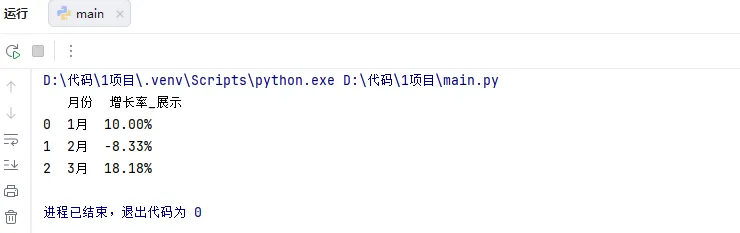
(亮点:不用在 Excel 里右键设置单元格格式,代码里直接搞定!负数自动带负号。) (只需15行代码,完成从数据到精美报表的全过程,可无限循环使用) 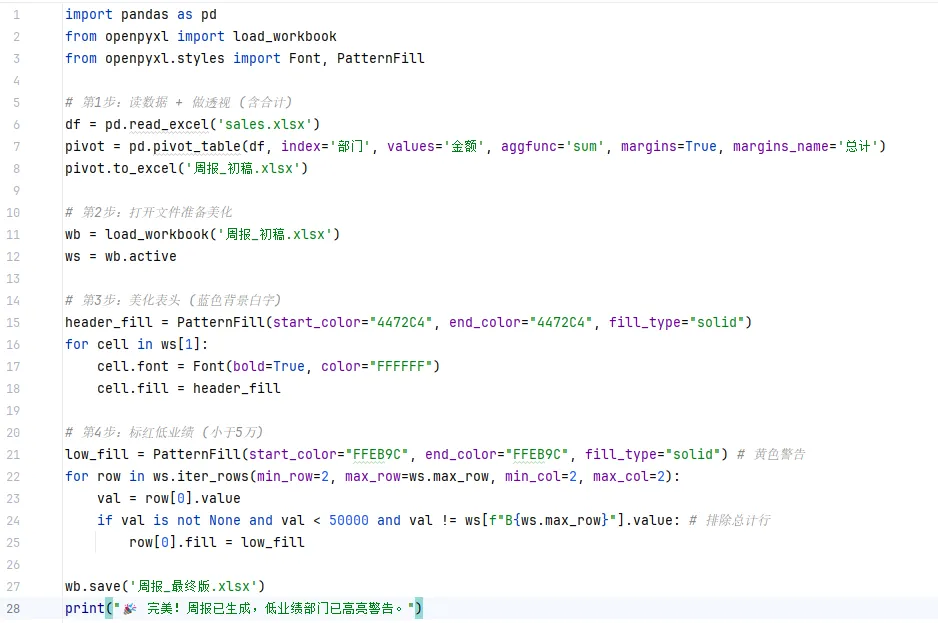
✨ 运行结果: 
🎯 案例二:生成“专业级”销售周报 (Excel 的透视表很强大,但 Pandas 的 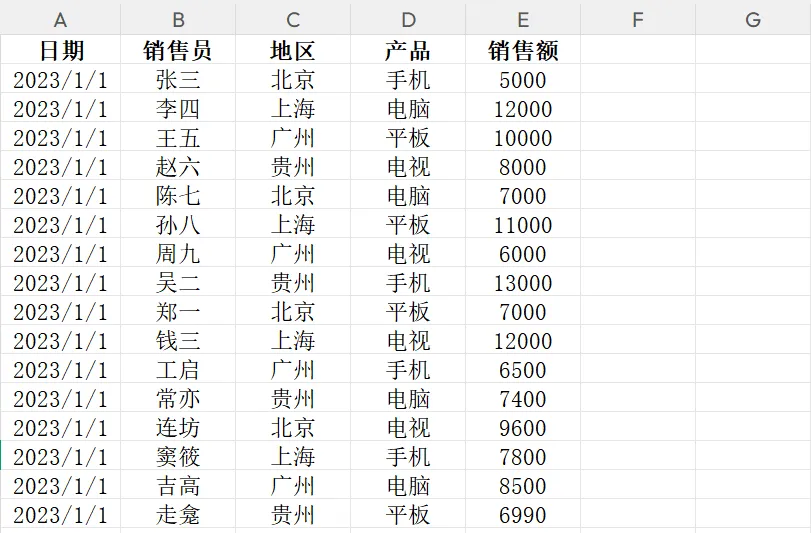
🐍 Python 代码:需求:统计 每个地区 的 每种产品 的 销售总额。 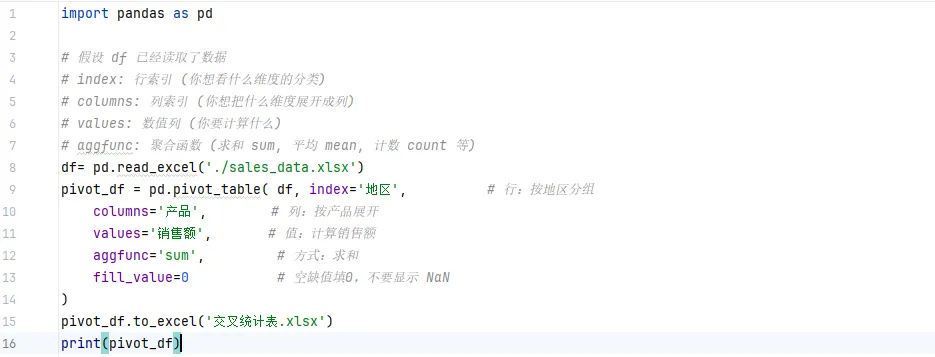
📊 运行结果 (透视表):(瞬间生成交叉统计表) 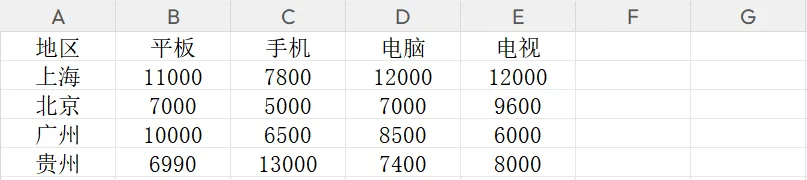
(如果想看“每个销售员的平均客单价”,只需把 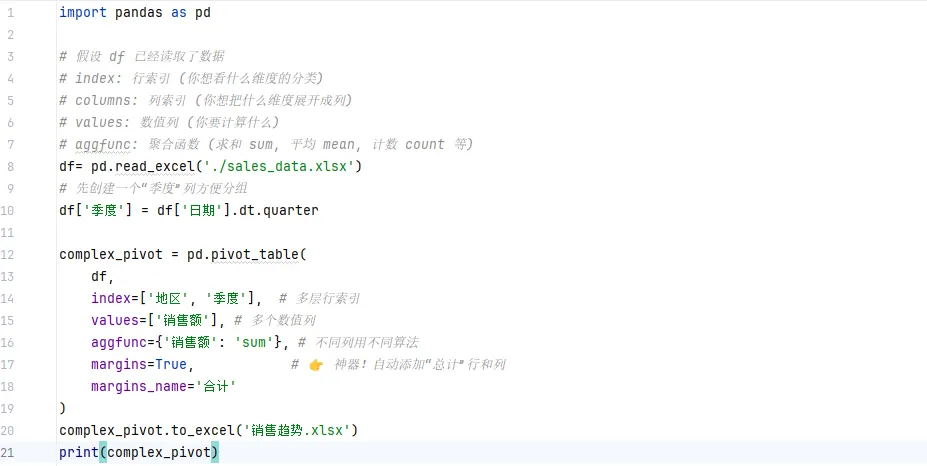
📊 运行结果: 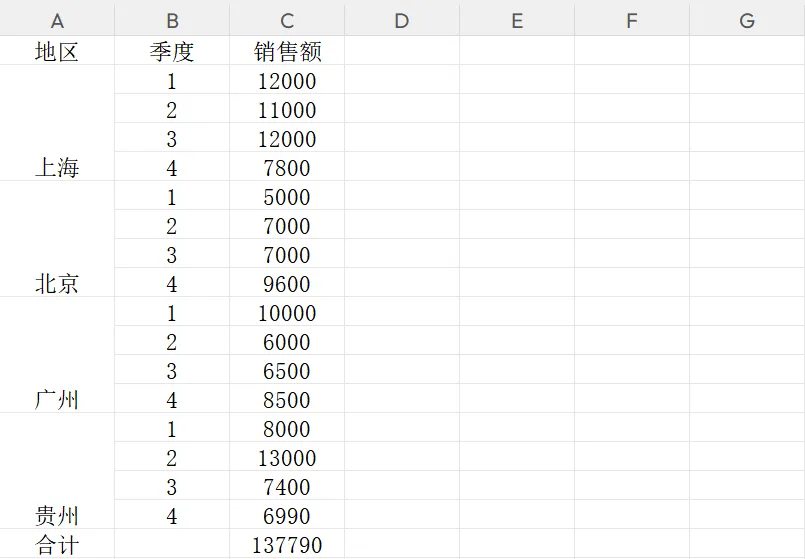
( 

📊 运行结果: 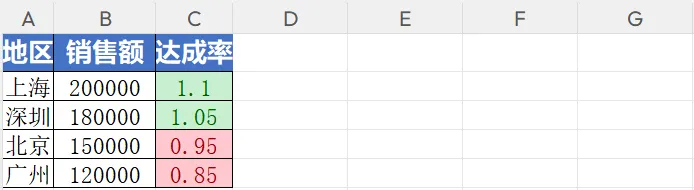
任务目标:输入原始流水账,输出一个包含以下 3 个 Sheet 的 Excel 报告: 

📊 运行结果: 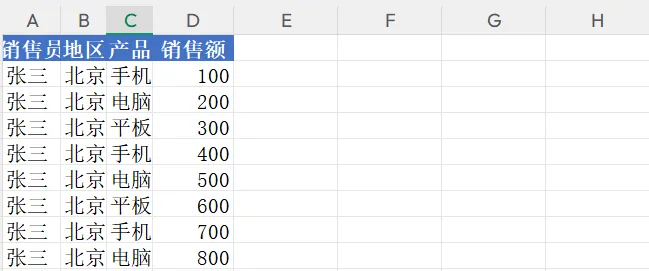
(明细数据太多就不一一截图了) 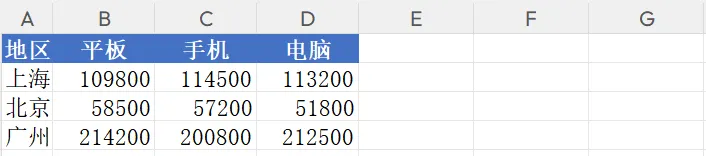
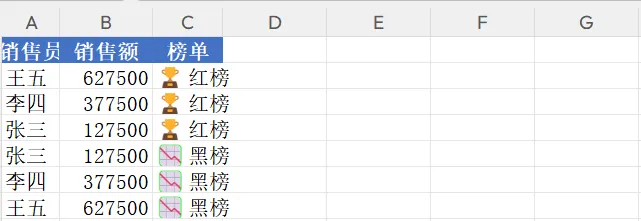
💬 互动环节
导语:上节课我们学会了用 Pandas 处理海量数据。
但老板拿到数据后,通常会问三个灵魂拷问:
哪个地区卖得最好? 每个销售员的季度趋势怎么样? 能不能把这张表做得漂亮点,直接能放进 PPT 汇报?
今天,我们不讲大道理,只给“小药方”!精选 经典职场微案例,解锁 Pandas 的终极武器——pivot_table(数据透视),并联手 openpyxl 给报表穿上“高定西装”。
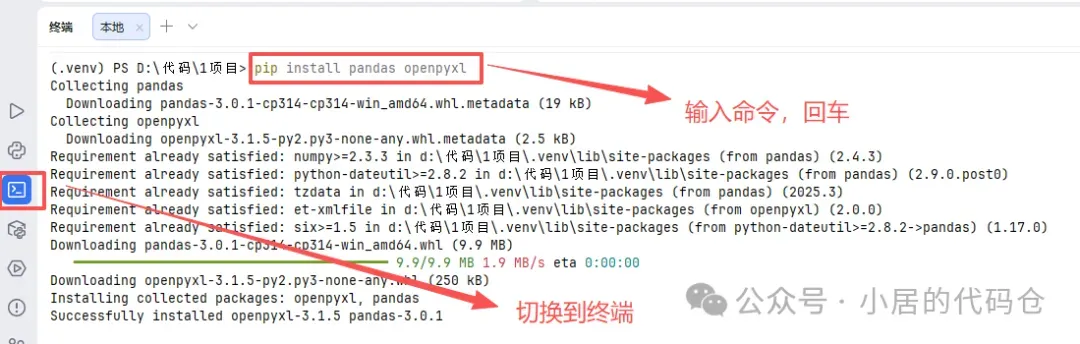
🛠️ 环境准备
我们需要两个核心库:
- pandas: 负责数据的透视、计算、逻辑处理。
- openpyxl: 负责 Excel 文件的样式美化(Pandas 本身不擅长画图和调整样式,需要它来辅助)。
🎯 案例一:生成“老板爱看的周报”
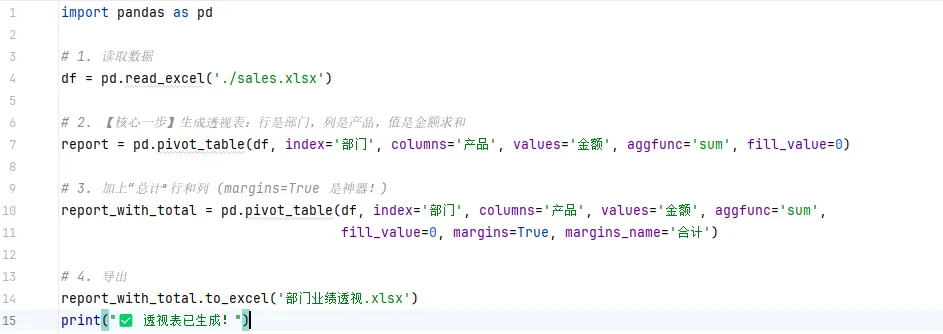
第1步:一键生成“部门业绩透视表”
痛点一: 老板问:“每个部门卖了多少?哪个产品最火?解法: 用 pivot_table 一行代码,自动生成交叉统计表。
📊 场景模拟
💻 极简代码:
(注:fill_value=0 保证没销量的格子显示0而不是 NaN。)
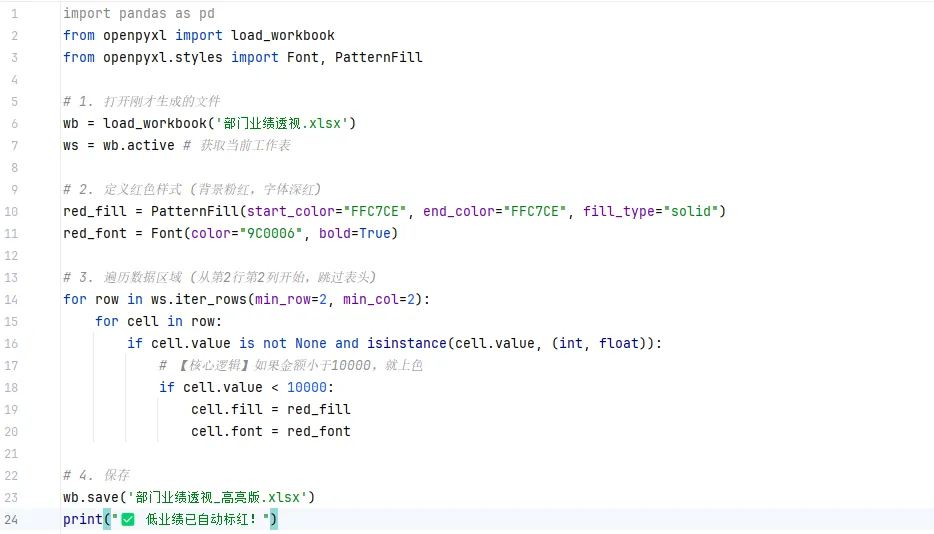
第2步:自动标红“未达标”数据
痛点二: 导出的表格里,哪些人业绩没达标?还得肉眼一个个找,或者在 Excel 里设规则。解法: 用 openpyxl 加几行代码,自动给小于目标值的单元格涂红。
📊 场景模拟
你想把上面的透视表发给老板,希望低于 10000 元的数字自动变红,提醒注意。
💻 极简代码:
.round() 统一保留2位小数,再转成百分比格式。📊 场景模拟
你有两年的数据,想算一下今年比去年涨了多少。
💻 极简代码:
🛠️ 综合实战:把上面三个小技巧串起来生成“老板爱看的周报”
pivot_table更灵活,且易于自动化。)1️⃣ 基础透视:多维度聚合
📊 原始数据 (sales_data):(想象这是一个包含数万行记录的 DataFrame)
index 改成 '销售员',aggfunc 改成 'mean',无需重新拖拽!)2️⃣ 进阶透视:多层级索引 & 自定义计算
场景: 老板想看“各地区 - 各季度”的销售趋势,并且要同时看“总额”。
margins=True 自动帮你算好了总计,省去了在 Excel 里再写 SUM 公式的麻烦!)3️⃣openpyxl 报表美化 —— 给数据穿上“高定西装”
Pandas 导出的 Excel 通常也是“素颜”的(默认字体、无边框、列宽自适应差)。我们要用openpyxl进行“化妆”。
核心思路:
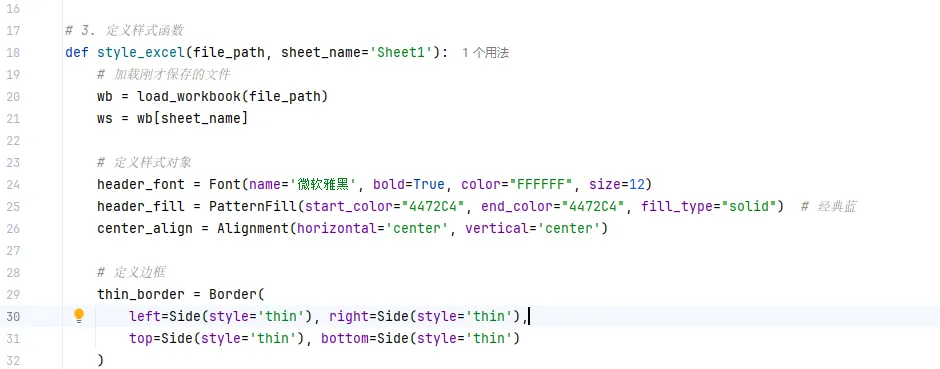
- 用
pd.ExcelWriter引擎指定为openpyxl。 - 保存后,通过
writer.book和writer.sheets获取工作表对象。 - 使用
openpyxl.styles设置字体、颜色、边框、对齐。 - 自动调整列宽。
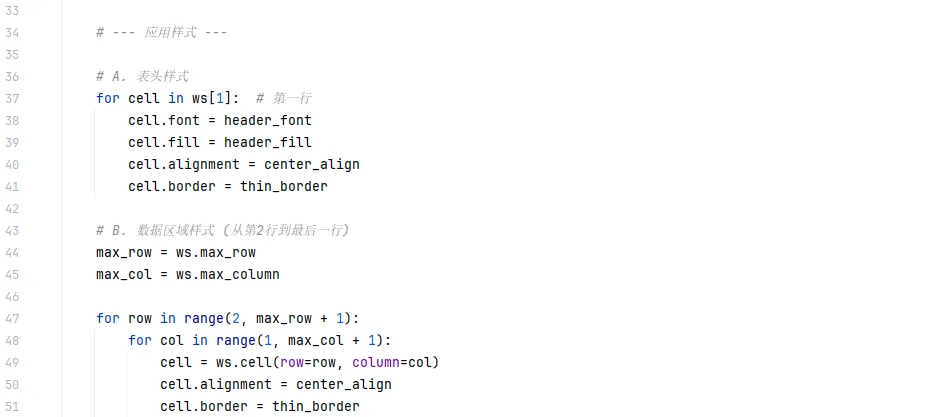
🐍 完整代码:
表头:深蓝色背景,白色加粗字体,居中对齐,看起来非常专业。
边框:所有单元格都有细黑线边框,不再散乱。
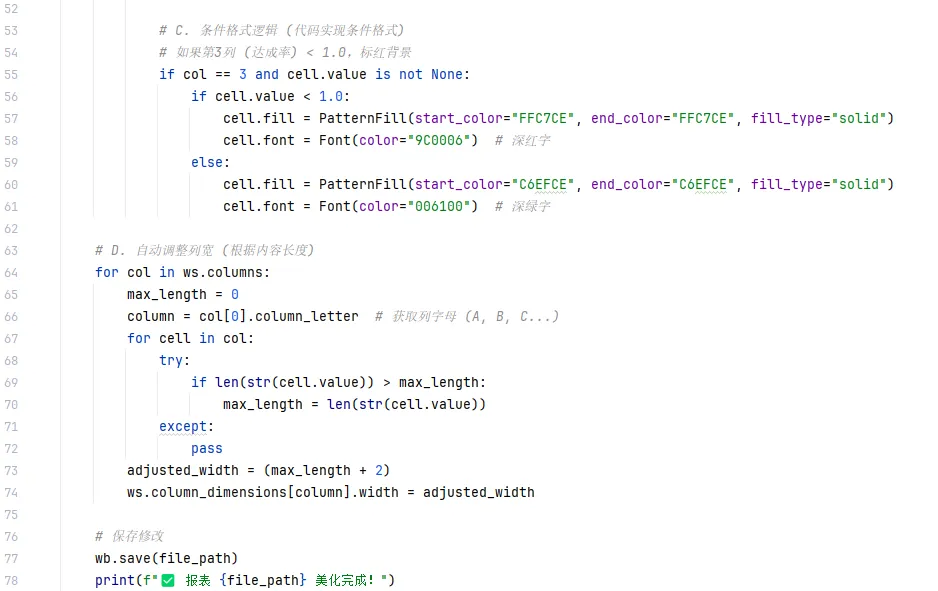
条件格式:
- 达成率 > 100% 的单元格自动变 绿色背景 + 深绿字。
- 达成率 < 100% 的单元格自动变 红色背景 + 深红字。
列宽:自动根据文字长短调整,不会出现“#####”或文字被截断的情况。
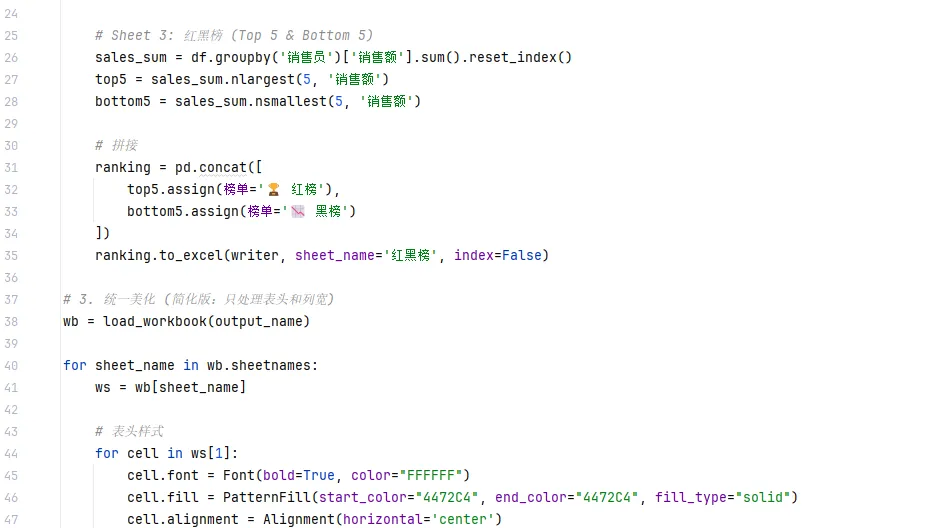
🚀 综合实战:一键生成“多 Sheet 分析大屏”
- 明细数据:清洗后的原始数据。
- 地区透视:各地区产品销售汇总(带样式)。
- 红黑榜:销售额最高和最低的 Top 5 销售员。
🐍 代码实现:
在评论区分享一个你曾经为了做透视表或美化 Excel 加班到深夜的经历!或者晒出你用本课代码生成的第一张“高颜值”报表截图(脱敏后)。
记住: 编程不是为了炫技,而是为了少加班。哪怕只用这十几行代码,也能让你从“做表两小时”变成“做表两分钟”。
👉 点赞 + 收藏,下节课我们彻底解放双手!☕️
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

