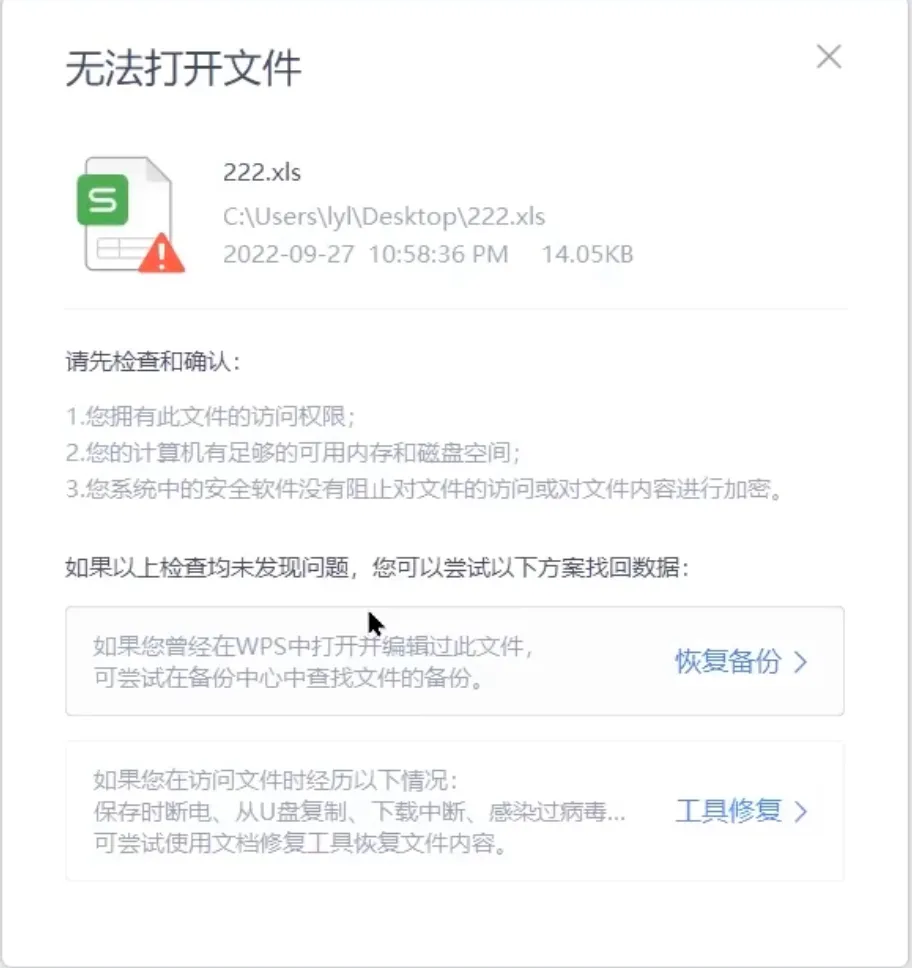
你是否遇到过HSSFWorkbook对象的getBytes()方法得到的byte数组内容不完整而导致写入文件损坏;如下图:
下边给出解决方式。
package com.dragon7531.bdemo.stream.test;import com.alibaba.nacos.client.naming.utils.IoUtils;import org.apache.poi.hssf.usermodel.HSSFWorkbook;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.Row;import org.apache.poi.ss.usermodel.Sheet;import java.io.*;public class ByteTest { public static void main(String[] args) { try (FileInputStream fi = new FileInputStream(new File("/Users/long/software/code/111.xls")); HSSFWorkbook wb = new HSSFWorkbook(fi); ) { Sheet sheetAt = wb.getSheetAt(0); Row row = sheetAt.createRow(1); Cell cell = row.createCell((0)); cell.setCellValue("新加的值"); ByteArrayOutputStream bo = new ByteArrayOutputStream(); wb.write(bo); // 刷新并关闭流,确保所有数据都被写入 bo.flush(); //此行写入会提示文件损坏 //ByteArrayInputStream in=new ByteArrayInputStream(wb.getBytes()); //此行是正确写法 ByteArrayInputStream in = new ByteArrayInputStream(bo.toByteArray()); FileOutputStream fo = new FileOutputStream("/Users/long/software/code/222.xls"); IoUtils.copy(in, fo); } catch (Exception e) { e.printStackTrace(); } }}
HSSFWorkbook 的 getBytes() 方法内容不全的核心原因和解决方案可总结为:
1. 核心原因:方法设计的本质问题getBytes() 方法并非为完整导出Workbook 内容设计,它的底层实现是直接将 Workbook 的内部数据结构序列化,而非按照 Excel 文件格式完整写入字节流。
该方法会跳过 Excel 文件格式的一些关键结构(如文件头、索引表、数据流结束标记等)
只序列化了 Workbook 的部分核心数据,导致生成的 byte 数组天然不完整
2. 最佳实践:必须使用 workbook.write(OutputStream) 方法将 Workbook 写入 ByteArrayOutputStream,再通过 toByteArray() 获取完整字节数组;
https://www.bilibili.com/video/BV1xB4y177aq
如果觉得文章内容不错,免费点个赞、推荐、分享一下,如果想第一时间收到推送,可以星标⭐下。更多精选干货,可以点击下方卡片进行查阅!