一.Excel文件基础知识
工作簿(workbook):Excel文档,后缀名常为.xls(旧版,Excel 2007以前)或者.xlsx(新版,Excel 2007以后,压缩版),一个工作簿可包含多个工作表。
工作表(worksheet):工作簿中的单个表格,默认名为sheet1、sheet2等。
行(row)与列(column):工作表中的横向的一行、纵向的一列。
单元格(cell):表格中行与列的交叉部分,是组成表格的最小单位。
Excel的功能:进行数据的输入、编辑、排序、筛选,可利用公式和函数引用相应单元格进行计算,并且可以将选中的数据绘制图表等。
二.Python处理Excel文件的9个常用库,每个库都有其特点和适用场景
.xls文件的三老友——xlrd,xlwt和xlutils
1.xlrd库
简介:意为.xls文件read库,用来读取文件。xlrd 2.0.1版本以上的只支持.xls文件,若要用此库读取.xlsx文件,则需安装旧版本xlrd 1.2.0版本。
安装:pip install xlrd(若需指定版本则需加上版本号例如pip install xlrd==1.2.0)
主要功能:
(1)打开工作簿:
workbook = xlrd.open_workbook(filename),其中filename是Excel文件的名字,一般使用相对路径;
(2)获取工作表:
workbook.sheet_by_index(0)或workbook.sheet_by_name('Sheet1'),分别通过表的索引或名称;
(3)获取工作表名称:
workbook.sheet_name(),获取工作簿中所有工作表的名称列表;
(4)读取单元格的值:
worksheet.cell_value()。
适用情景:只需要进行数据导入、数据预处理等读取操作,xlrd是合适的选择。
2.xlwt库
简介:与xlrd库相对应,意为.xls文件write库,用来写入新文件。xlwt只支持.xls文件。
安装:pip install xlwt
主要功能:
(1)创建工作簿和工作表:可以创建一个工作簿对象,并添加一个或多个工作表;
workbook = xlwt.Workbook(encoding = 'ascii')
worksheet = workbook.add_sheet('My Worksheet')
(2)写入数据:支持写入文本和数字到指定单元格;
worksheet.write(0, 0, label = 'Row 0, Column 0 Value')
(3)保存文件:将创建和编辑的Excel文件保存到磁盘,支持绝对路径和相对路径;
workbook.save('Excel_Workbook.xls')
(4)设置样式:包括设置字体、边框、对齐方式等,例如设置文本居中、调整列宽和行高。
适用情景:需要输出.xls文件,运行环境较旧,项目规模较小(单表不得超过65535行)。
3.xlutils库
简介:结合了xlrd和xlwt库的功能,打通了只读到可写,提供了对.xls文件进行读写、修改等常用操作。
安装:pip install xlutils(并且需要先安装过xlrd库和xlwt库)
主要功能:
(1)数据修改:将xlrd.Book复制,并转为可写的对象xlwt.Workbook,然后在现有.xls文件的基础上修改数据,并写入一个新的.xls文件,实现修改功能;
(2)数据拆分:xlutils.filter(),拆分、筛选数据并生成新文件;
(3)设置样式:xlutils.styles(),处理单元格样式信息;
适用情景:对于已有的.xls文件,想要追加或者修改数据时,xlrd和xlwt库单独使用无法完成任务,因此需要使用xlutils库。
专注于.xlsx文件的两剑客——openpyxl和XlsxWriter
4.openpyxl库
简介:用于.xlsx文件的读取、写入和修改。
安装:pip install openpyxl
主要功能:
(1)创建文件和写入数据:
wb = Workbook()
sheet = wb.active
sheet[‘A1’] = ‘姓名’
sheet[‘B1’] = ‘学号’
sheet.append([‘张三’,’1001’])
sheet.append([‘李四’,’1002’])
...
wb.save(‘学生表.xlsx’)
(2)读取文件和修改数据:
wb = load_workbook(‘成绩表.xlsx’)
sheet = wb[‘Sheet1’]
再for循环遍历表中数据
可用算法修改数据
wb.save(‘成绩表_new.xlsx’)
(3)单元格合并和样式设置
(4)插入图表
适用场景:对于.xlsx文件读写,需要精细控制文件的格式、处理复杂表头或多sheet数据、保留样式信息、插入图表或自动化生成格式化报表时,openpyxl是合适的选择。
5.XlsxWriter库
简介:与.xls的写入库xlwt功能类似,专注于.xlsx新文件的写入,不能修改已有文件的数据。
安装:pip install XlsxWriter
主要功能:
(1)创建文件和写入数据:
xlsxwriter.Workbook(),创建工作簿;
workbook.add_worksheet(),添加工作表;
worksheet.write(),写入数据;
(2)写入公式和插入图表:
worksheet.write方法写入公式,如=SUM(B2:B5);
workbook.add_chart创建图表,支持多种图表类型;
(3)设置格式:
workbook.add_format(),创建格式对象;
worksheet.set_row()和worksheet.set_column(),设置行高和列宽;
(4)合并单元格:
worksheet.merge_range();
(5)插入图片:
worksheet.insert_image()。
适用情景:针对.xlsx文件的写入,在数据报表生成、数据分析和可视化方面有广泛应用。比其他类似库支持更多的Excel特性,对Excel生成的文件具有很高的保真度,并且在处理大文件时可以配置为使用少的内存。
兼容.xls和.xlsx的全能王——xlwings,win32com,DataNitro
6.xlwings库
简介:用于在Excel和Python之间交互的库,能进行文件的读写、复杂运算和自动化任务等。
安装:pip install xlwings
主要功能:
(1)读取文件,将数据转为Python数据结构:
app = xw.App(visible=False, add_book=False)
wb =app.books.open(文件名)或Book(文件名)打开文件;
sheet = wb.sheets[index]或sheet =wb.sheets['sheet名']访问工作表;
data = sheet.range('A1').expand().value读取数据;
app.quit()退出Excel应用程序;
(2)将Python中的数据写入到Excel文件:
List1 = [1, 2, 3, 4, 5]
Sht = xw.Book().sheets('sheet1') 新增一个表格;sht.range('A1').options(transpose=True).value = list1通过一维列表配合特定options参数写入一列数据;
(3)VBA集成(.xlsm文件):
wb.macro()函数调用VBA宏;
(4)自动化操作:
通过代码控制Excel界面行为,设置单元格格式,插入图表;
(5)开发Excel插件:
将脚本封装为自定义功能区按钮,让非编程用户通过点击按钮运行Python脚本。
适用情景:通过xlwings,用户可以将Python中的数据分析工具(如Pandas、Numpy)与Excel无缝集成,实现高效的数据处理和分析;需要使用VBA宏的场景;以及自动化生成报表。
7.win32com库
简介:win32com是pywin32库的一部分模块,用于Python脚本与Windows COM组件交互。
win32com库允许Python代码直接操作Windows应用程序,如Excel、Word等,而不需借助VBA。
安装:pip install pywin32(在Windows系统中,由于xlwings库依赖于pywin32库,所以如果已经安装了xlwings,则已自动安装过)
主要功能:
(1)批量读写数据:
xlApp = Dispatch('Excel.Application')
xlApp.Visible = True
xlApp.Workbooks.Add()
xlSheet = xlApp.Sheets(1)
xlSheet.Cells(1, 1).Value = 'Hello from Python!'
(2)公式计算:
excel = win32.Dispatch('Excel.Application')
wb = excel.Workbooks.open('test.xlsx')
ws = wb.Worksheets('Sheet1')
ws.Range('E1:E10').Formula = '=SUM(A1:D1)'
wb.Save()
wb.Close()
(3)生成图表;
(4)报表批量导出。
适用情景:适用于需要在Windows环境下操作Office组件、处理特定文档格式、进行办公自动化以及与Windows系统组件交互的场景。
8.DataNitro库
简介:支持.xls,.xlsx文件的读写的内嵌插件(需要收费,略过)。
擅长数据分析的功夫熊猫——pandas
9.pandas库
简介:用于数据处理与分析的一个强大库,提供了类似Excel表格的数据结构,主要数据结构是Series(一维数据)与DataFrame(二维数据),它们可以用来处理多种类型的数据,包括时间序列数据和结构化数据等,方便用户进行数据的存储、查询和操作。
安装:pip install pandas
主要功能:
(1)数据读取与写入:
df = pd.read_excel(filename),读取文件;
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False),写入数据;
(2)数据清洗:
cleaned_data = data.dropna(),删除含有缺失值的号;
unique_data = data.drop_duplicates(),去重;
(3)数据类型转换:
df['列名'] = df['列名'].astype('int64'),将该列转换成整型;
(4)数据过滤与筛选:
filtered_data = data[data[‘列名’]>value],筛选出某列大于某特定值的行;
(5)数据排序:
sorted_data = data.sort_values(by='成绩'),按照成绩排序;
(6)数据的分组与聚合:
grouped_data = data.groupby(‘班级’)[‘成绩’].mean(),按“班级”分组,并计算成绩均值;
(7)数据的合并与连接:
merged_data = pd.merge(data1, data2, on=’common_column’),根据功能的列进行连接;
(8)数据统计分析:可以计算各种统计量,如均值、方差、相关系数等;
(9)数据重塑:结合melt和pivot等操作;
(10)时间序列分析:支持时间索引、时间切片和重采样等操作。使用rolling()方法可以进行移动平均、移动标准差等计算,适用于金融数据分析;
(11)数据可视化:pandas本身并不直接提供可视化功能,但它可以与Matplotlib和Seaborn等Python库无缝集成,允许用户快速创建各种图表和可视化。
适用情景:适合处理小到中等规模的数据,尤其是在数据清洗、处理和分析过程中。
三.总结(只总结免费的8个库)
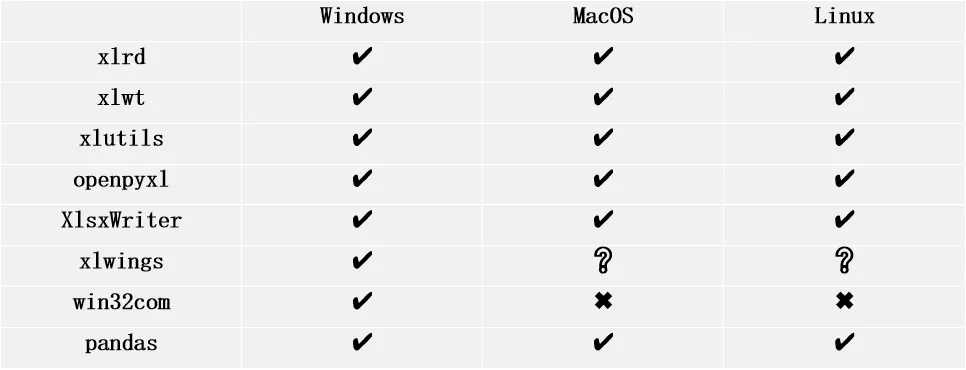
1.不同运行环境下各个库的适用性如下表:
(✔表示适用,❓表示可能有兼容问题,✖表示不适用)
2.不同Excel文件类型各个库的适用性如下表:
(✔表示适用,❓表示可能有兼容问题,✖表示不适用)