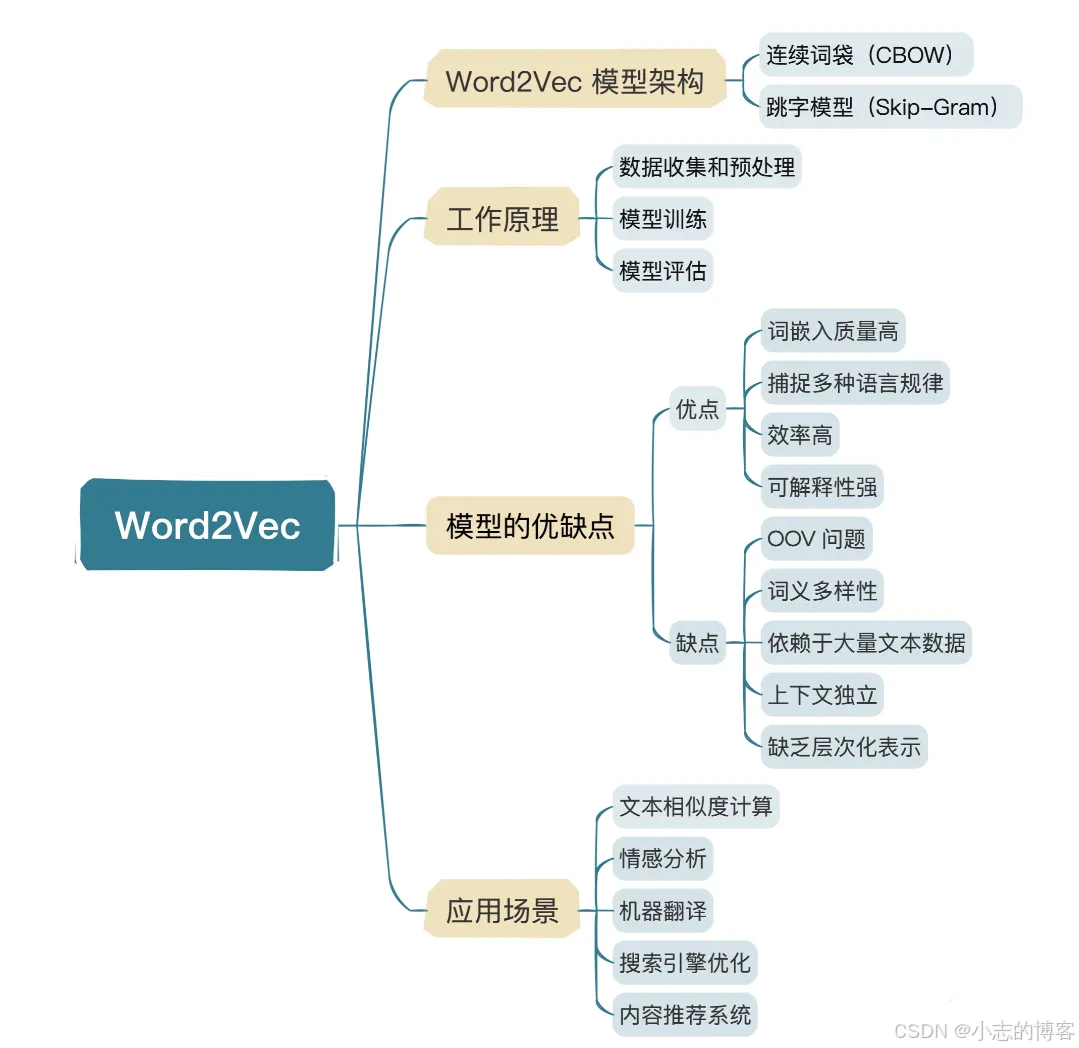
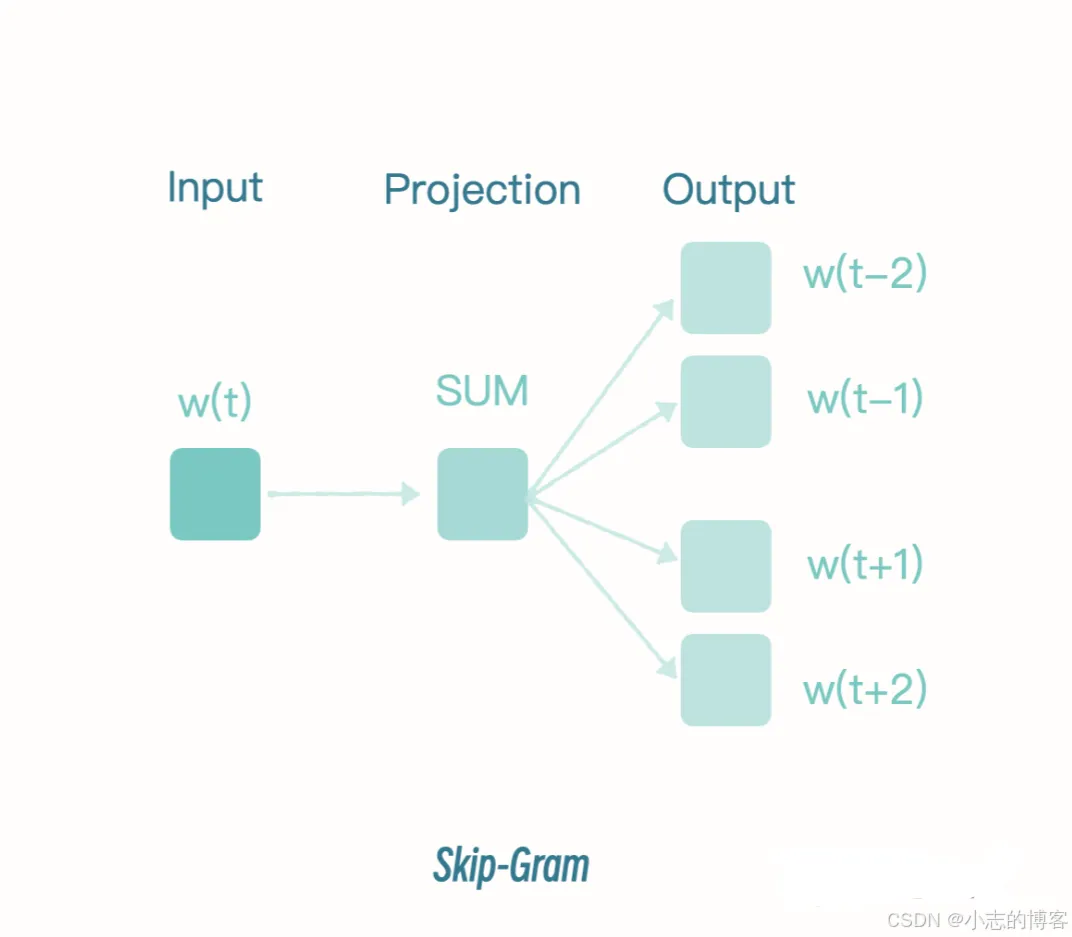
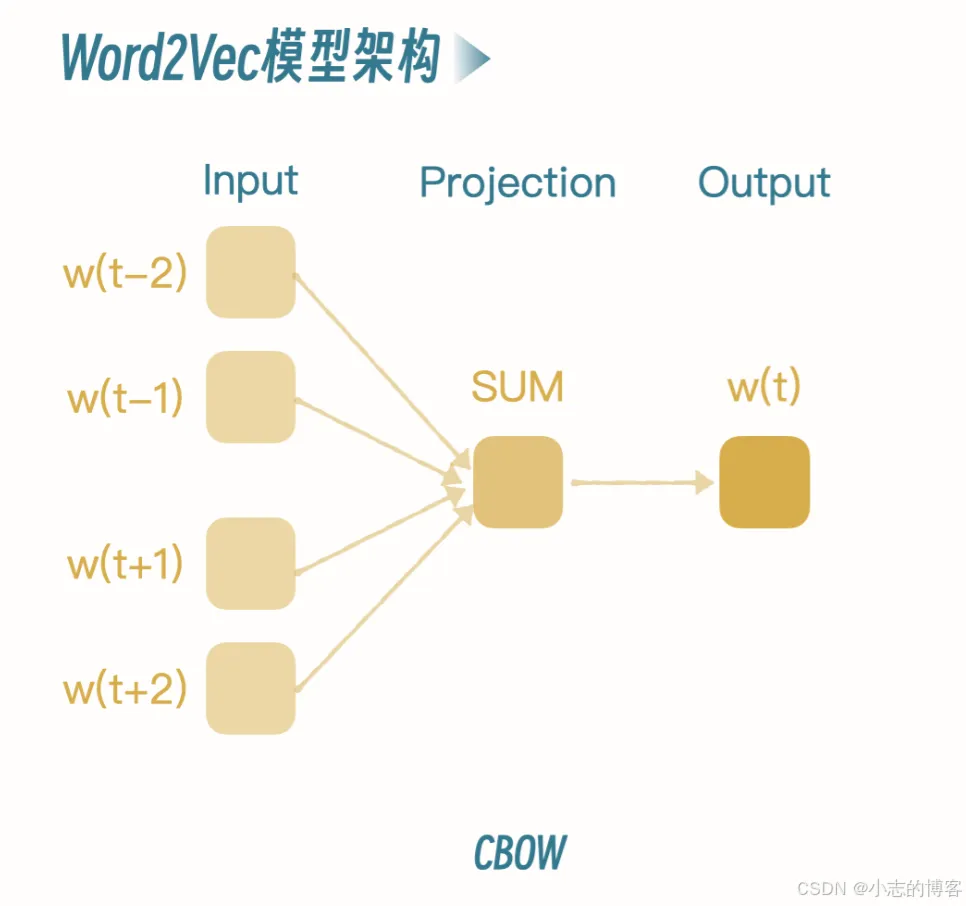
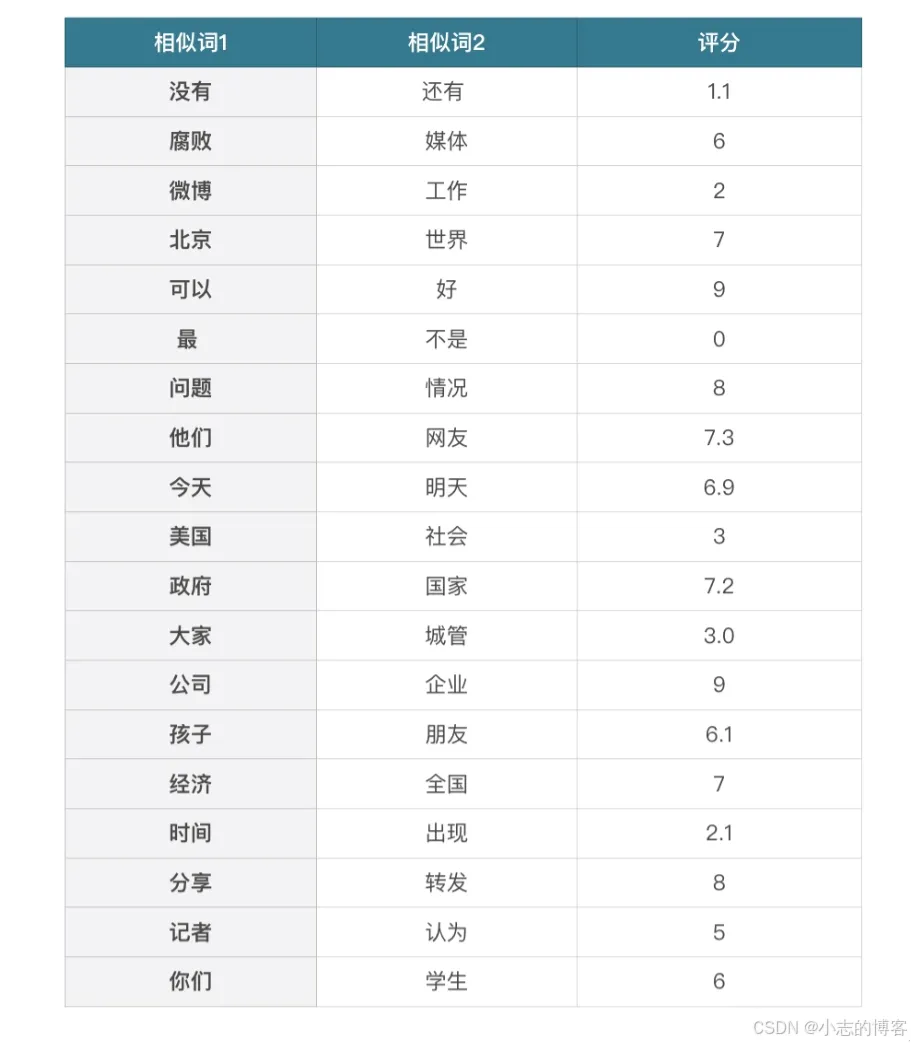
网上下载了一个公开的微博内容数据集。我们先进行文本预处理。回想一下我们前几节课提到的方法,步骤就是数据加载 -> 去除停用词 -> 分词等等。这里我们就进行这些简单的预处理操作。
import jieba
import xml.etree.ElementTree as ET
# 读取XML文件并解析
file_path = 'data.xml'
tree = ET.parse(file_path)
root = tree.getroot()
# 获取所有<article>标签的内容
texts = [record.find('article').text for record in root.findall('RECORD')]
print(len(texts))
# 停用词列表,实际应用中需要根据实际情况扩展
stop_words = set(["的", "了", "在", "是", "我", "有", "和", "就"])
# 分词和去除停用词
processed_texts = []
for text in texts:
if text is not None:
words = jieba.cut(text)
processed_text = [word for word in words if word not in stop_words]
processed_texts.append(processed_text)
# 打印预处理后的文本
for text in processed_texts:
print(text)