pandas.read_excel()是将Excel文件中的数据读取到pandas DataFrame中的函数。它支持从本地文件系统或URL读取的xls,xlsx,xlsm,xlsb和odf文件扩展名。 支持读取单一sheet或几个sheet。
pandas.read_excel()的官方文档地址为:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
语法
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None,
usecols=None, dtype=None, engine=None, converters=None,
true_values=None, false_values=None, skiprows=None, nrows=None,
na_values=None, keep_default_na=True, na_filter=True, verbose=False,
parse_dates=False, date_parser=<no_default>, date_format=None,
thousands=None, decimal='.', comment=None, skipfooter=0,
storage_options=None, dtype_backend=<no_default>, engine_kwargs=None)
主要的参数对应的含义如下:
- io:这是必需的参数,指定了要读取的 Excel 文件的路径或文件对象。
- sheet_name=0:指定要读取的工作表名称或索引,可以传入数字和文本。默认为0,即第一个工作表,数字表示顺序。如果使用文本就是读取对应的工作表名称
- header=0:指定用作列名的行。默认为0,即第一行。
- names=None:用于指定列名的列表。如果提供,输出的dataframe中列名会被修改为传入的列名
- index_col=None:指定用作行索引的列。可以是列的名称或数字。
- usecols=None:指定要读取的列。可以是列名的列表或列索引的列表。
- dtype=None:指定列的数据类型。可以是字典格式,键为列名,值为数据类型。
- engine=None:指定解析引擎。默认为None,pandas 会自动选择。
- converters=None:用于转换数据的函数字典。
- true_values=None:指定应该被视为布尔值True的值。
- false_values=None:指定应该被视为布尔值False的值。
- skiprows=None:指定要跳过的行数或要跳过的行的列表。
- na_values=None:指定应该被视为缺失值的值。
- keep_default_na=True:指定是否要将默认的缺失值(例如NaN)解析为NA。
- na_filter=True:指定是否要将数据转换为NA。
- verbose=False:指定是否要输出详细的进度信息。
- parse_dates=False:指定是否要解析日期。
- date_parser=<no_default>:用于解析日期的函数。
- date_format=None:指定日期的格式。
- skipfooter=0:指定要跳过的文件末尾的行数。
- storage_options=None:用于云存储的参数字典。
- dtype_backend=<no_default>:指定数据类型后端。
- engine_kwargs=None:传递给引擎的额外参数字典。
用法
以如下样式的Excel为例,下载链接:https://download.csdn.net/download/qq_42692386/92562285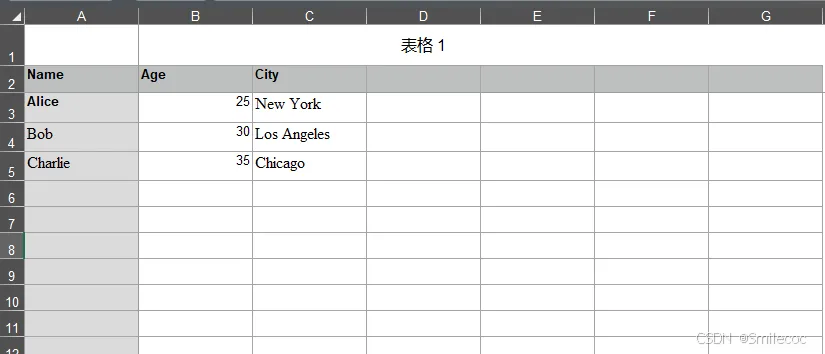
导入数据
import pandas as pd
# 读取 data.xlsx 文件
df = pd.read_excel('pandas_read_excel_data.xlsx')
# 打印读取的 DataFrame
print(df)
输出结果如下:
表格 1 Unnamed: 1 Unnamed: 2
0 Name Age City
1 Alice 25 New York
2 Bob 30 Los Angeles
3 Charlie 35 Chicago
程序默认导入第一个sheet的数据。同时原始数据第一行不是列名导致输出的结果并非是需要的数据格式
指定列名所在的行
使用header参数指定列名所在的行,可以指定表格作为列名的行
import pandas as pd
# 读取 data.xlsx 文件
df = pd.read_excel('pandas_read_excel_data.xlsx',header=1)
# 打印读取的 DataFrame
print(df)
也可以通skiprows来控制读取数据时跳过的行数,从而控制导入数据的范围
import pandas as pd
# 读取 data.xlsx 文件
df = pd.read_excel('pandas_read_excel_data.xlsx',skiprows=1)
# 打印读取的 DataFrame
print(df)
在这个示例文件中,两种方法读取的结果相同:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
指定工作表名
如果需要读取不同的工作表可以通过sheet_name参数控制。如果传入的是数字则是按照顺利选取,0表示第一个工作表,1表示第二个工作表以此类推。如果传入的是文本,就是按照工作表名称选取,如下示例就是读取工作表名为Sheet2的数据
import pandas as pd
# 读取 data.xlsx 文件
df = pd.read_excel('pandas_read_excel_data.xlsx',sheet_name='Sheet2')
# 打印读取的 DataFrame
print(df)
修改数据类型
使用dtype传入列名和数据类型可以定义每列数据的类型
import pandas as pd
# 读取 data.xlsx 文件
df = pd.read_excel('pandas_read_excel_data.xlsx',header=1,dtype={'Name': str, 'Age':float,'City':str})
# 打印读取的 DataFrame
print(df)
可以看到输出的结果中'Age'已变为浮点型的数据类型
Name Age City
0 Alice 25.0 New York
1 Bob 30.0 Los Angeles
2 Charlie 35.0 Chicago

