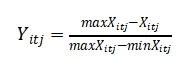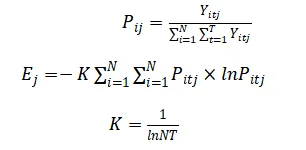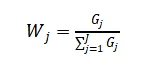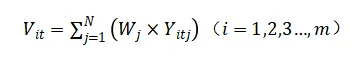概念
在信息论中,熵是衡量信息量不确定性或混乱程度的指标。
熵值越大:表示该指标的信息不确定性越大,即该指标的区分能力越弱。
熵值越小:表示该指标的信息不确定性越小,即该指标的区分能力越强。
根据熵的特性,我们可以通过计算熵值来判断一个事件的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响越大,权重也就越大。
举个例子,在对地区经济发展水平的评价案例中,若“平均GDP”这个指标在不同地区差异很大,说明这个指标能有效区分地区的经济发展水平,指标的信息熵较小,权重就相对较高。反之,如果所有地区的“财政收入”都一样大,这个指标的区分度就比较低,信息熵较大,权重比较低。
价值
客观赋权,减少人为偏差。熵值法完全基于数据本身的分布特征进行计算,避免了德尔菲法、层次分析法等主观赋权法中专家经验和个人偏好可能带来的系统性偏差。这使得评价结果更加中立、可信,尤其适用于数据充足且趋势明确的研究场景。
量化指标重要性,揭示内在结构。该方法通过计算每个指标的熵值和差异系数,能够精确量化每个指标对综合评价结果的贡献度(即权重)。这不仅为决策者提供了清晰的指标重要性排序,也帮助研究者深入理解系统内部的构成和运行机制。
适用于多指标、多对象的复杂评价。熵值法天然适用于对多个对象(如城市、企业、项目)进行多维度(如经济、社会、环境)的综合评估。它能够有效处理大量指标间的信息冗余和相关性问题,将高维数据浓缩为一个简洁的综合得分,极大地简化了评价过程。
动态监测与趋势分析。由于熵值法依赖于历史数据,因此可以用于构建评价指标体系的长期动态监测模型。通过比较不同时期的熵值变化,可以分析系统的发展趋势、稳定性以及面临的挑战,为战略规划和政策调整提供数据支撑。
广泛的跨学科适用性。熵值法的应用已超越经济学范畴,延伸至社会学、环境科学、管理学、医学等多个领域。
操作简便。Excel、SPSS、Stata等基本所有软件都可以操作。
计算步骤
第一,先对数据进行标准化,消除数据之间的差异和量级单位的不同;然后对正向指标(对综合指数会产生正向的影响)进行正向处理,对负向指标(对综合指标会产生负向的影响)进行负向处理,公式如下:
正向指标处理方法:
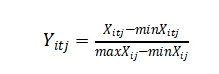
负向指标处理方法:
其中,i代表省份;t代表年份;j代表各项测量的指标;minXitj为j中的最小值;maxXitj为j中最大值;Yitj为处理后的结果。
第二,计算标准化后各个指标的信息熵,即Ej。公式如下:
其中,N代表数据中所选取省份的数量;T代表所选取年份的数量;NT代表样本的个数,Ej代表各个指标的信息熵。
第三,计算指标间的差异系数:Gj=1-Ej 第四,计算指标的权重
其中:J代表指标的个数。
第五,运用线性加权的方法进行指数的综合测度。其公式如下:
其中,Wj是各指标的权重;Yitj是各指标数据标准化后处理的结果。