从脑机接口开始,二级市场确认进入了风投化时代。
估值范式早已不是曾经的PE、PB,而是变成了终局*概率。
人形机器人虽然现在只有几万台产量,但是预期每个人要配3台,150亿台销量。
脑机接口虽然成功案例还没有,但是预期未来每个人都要配备,可以从神经层面重构我们的认知。
相比之下,我认为国产大模型仍然是被大家显著低估的一个领域。
大逻辑非常清晰,2026的大模型,就是2006年的互联网。
咱们刚经历了持续三年的大规模AI基建,砸了几万亿美金到高速公路上面,接下来就是让公路上跑起来车(AI应用),而AI应用能蓬勃发展的核心驱动力,就是大模型的效能提升。
但一直以来的一个分歧在于,很多人认为模型具有头部效应,中国买不到卡,所以模型的差距会越来越大以至于无法追赶。
关于这点,众说纷纭,但是我们只要看世界上最有影响力的人怎么看待就行了,也就是老马或者老黄。
不知道大家有没有关注黄仁勋昨天在CES(国际消费电子产品展览会)的开年首场演讲,没想到全场几乎没咋提到Open AI、Gemini这些硅谷公司,倒是把中国的开源模型御三家(Kimi、Deepseek、Qwen)放进了PPT,并且大谈特谈开源模型的贡献。
这就很有意思,老黄为啥放着大客户不吹,专门要点名中国模型呢?
主要还是在过去一年,中国主导了当前的开源模型创新。
从互联网的历史来看,开源使得创新可以迅速分享传播,帮助硅谷完成了互联网蛮荒时代的开拓,从IBM、红帽到Tesla的Autopilot,一代代的开源王者崛起。
而现在,最大开源社区Hugging Face大模型开源趋势榜单上,前10名已经全都是中国的开源模型。
随着大模型从科学问题演化成工程问题,中国的工程师红利逐渐展现出来。
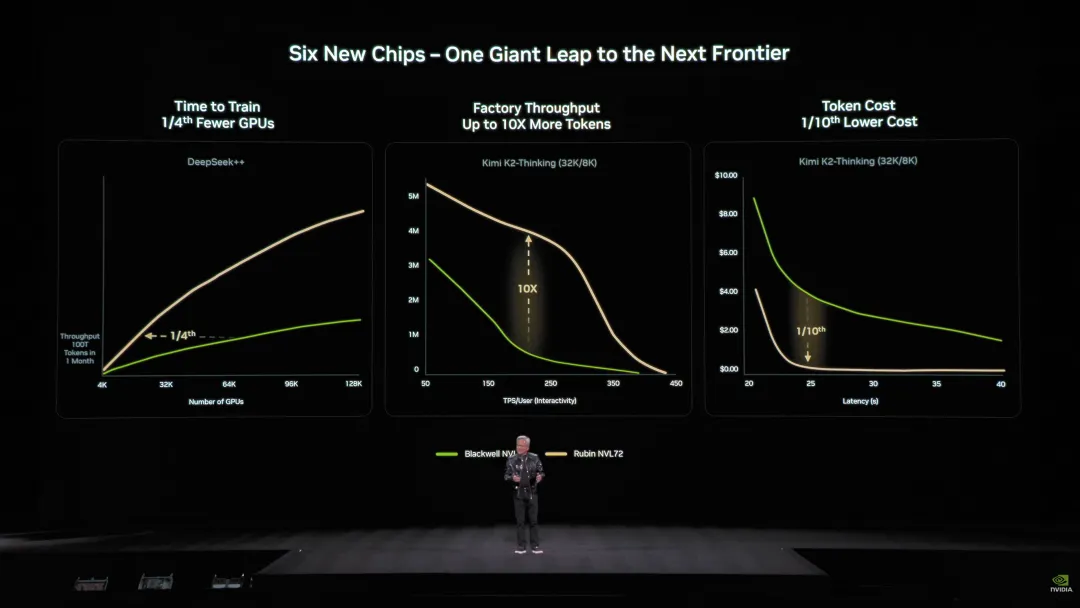
还有一点,在展示的新一代Rubin芯片架构时,老黄直接把Kimi K2 Thinking和 Deepseek 当作benchmark,证明Rubin 架构可以让 AI 的训练更省钱、推理更快、成本更低。
前者作为万亿参数的推理模型,被当作全球参数规模和推理效率的天花板;后者则是训练成本优化的极致代表。
这其实也透露了一个信号:模型并不是只有计算能力一个维度,成本、时延也非常重要,这很有可能是中国玩家的一个重大机会。
随着Kimi、Deepseek这些国产开源模型走上世界舞台,一场与美国闭源厂商Open AI/Claude/Gemini的竞争,已经不可避免。
刚好今年是全球大模型的上市元年,Anthropic下半年就要在纳斯达克IPO了,肯定会掀起新的一轮讨论热度…………
任何新兴事物,都是从看不懂,到看不起,再到赶不上。
这不,虽然不少人质疑国产大模型的未来,但也听说kimi默默完成了5亿美金的C轮融资,让整个一级市场惊叹。
敢于在早期下注的人,虽然承受了很多不确定性和压力,但确实有可能获得最高的回报。
对这些为创新押注的投资人,笔者在此表达一下敬意。感谢你们的努力,为沉闷的经济系统注入了一股源头活水,也让二级市场的科技板块活跃了起来。

