如何将任何Excel文件转换为Web应用程序
- 2026-06-22 20:38:38

将Excel文件转化为Web应用程序,是数据处理领域中一项较为成熟的技术方案,笔者此前已在《使用streamlit库轻松搭建数据看板》一文中,对该方法进行过相关介绍。
在IT审计工作中,从业人员需要频繁对接券商、企业及注册会计师,开展数据核对、数据分析结果核验与沟通研讨等工作。相较于传统操作方式,该方案具备直观高效的优势,可有效规避在Excel表格中反复调整、处理数据的繁琐操作,也是笔者在实际项目落地过程中高频使用的实用方法。
基于此,本文将再次围绕Excel文件转Web应用这一主题展开探讨。本次内容将在原有基础上进行升级优化,实现对各类Excel文件的通用适配,同时新增数据筛选功能,进一步提升数据筛选与处理的便捷性。
我们的需求:将Excel电子表格数据迁移并搭建为现代化Web应用程序,同时为程序增设下拉筛选功能、搭建数据表格与可视化图表,全方位优化数据探索与分析体验。核心优势在于,整个过程无需掌握HTML、JavaScript等任何前端开发技术,仅通过少量Python代码即可完成全部操作。
Web应用程序的构建将依托三款核心工具库完成,分别为 Streamlit、Pandas 与 Plotly,各库的核心功能及环境安装方式具体说明如下。
其中,Streamlit主要用于搭建浏览器端网页应用程序,可快速实现Web应用的开发部署;Pandas专注于结构化数据的清洗、整理与处理工作,为应用提供数据支撑;Plotly负责可视化图表的制作与生成,实现数据可视化展示。
在工具库的安装环节,可根据开发环境选择对应安装方式:若基于 Anaconda 开发环境,可通过 Anaconda 提示符执行对应安装命令完成库的安装;若未使用 Anaconda 环境,则可通过 pip 工具执行安装操作。
#1、导入库
import streamlit as stimport pandas as pdimport plotly.express as pximport osos.chdir(r'E:\TestData')
#2、加载数据
df = pd.read_excel("carData.xlsx", sheet_name="Sheet1")#3、添加页面标题和副标题
st.title("汽车销量排行榜")st.write("爱尔兰最畅销车型")
#4、添加下拉控件
st.header("筛选")brands = ["所有品牌"] + sorted(df["品牌"].unique())selected_brand = st.selectbox("按品牌筛选",brands)fueltypes = ["所有燃料类型"] + sorted(df["燃料类型"].unique())selected_fueltype = st.selectbox("按燃料类型筛选",fueltypes)
#5、应用筛选
if selected_brand != "所有品牌":df = df[df["品牌"] == selected_brand]if selected_fueltype != "所有燃料类型":df = df[df["燃料类型"] == selected_fueltype]filtered_df = df.sort_values("销量",ascending=False)
#6、显示表格
st.subheader("排行榜")if filtered_df.empty:st.warning("没有找到您要的数据")else:st.dataframe(filtered_df, width="stretch", hide_index=True)
运行程序后,我们选择“奥迪”品牌和“汽油”燃料,看一下结果:
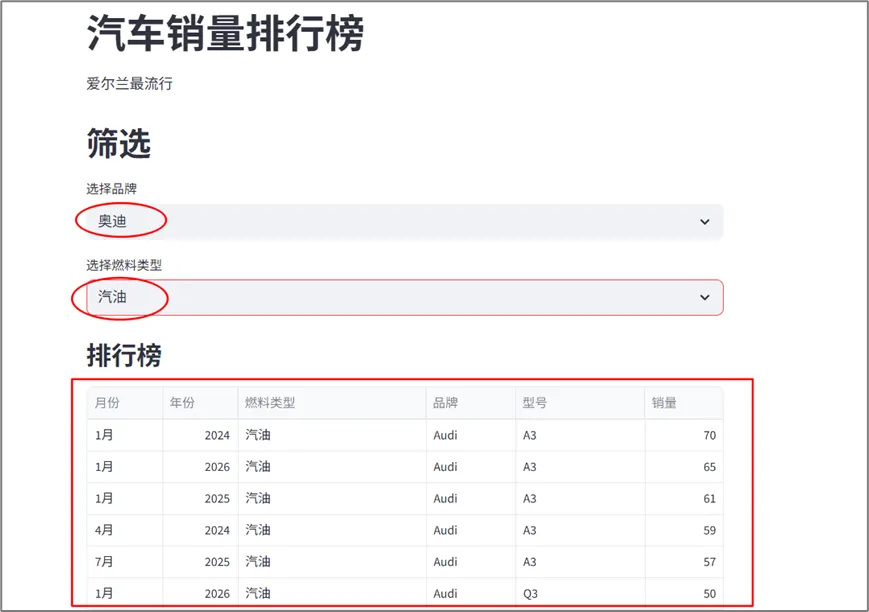
#7、显示图表
st.subheader("按燃料类型统计销量")fuel_df = df.groupby(["年份", "燃料类型"], as_index=False)["销量"].sum()fig = px.line(fuel_df,x="年份", y="销量",color="燃料类型",markers=True)fig.update_layout(xaxis=dict(type="category"))st.plotly_chart(fig, width="stretch")
还是以上面的“奥迪”品牌和“汽油”燃料为例,我们再看一下结果:
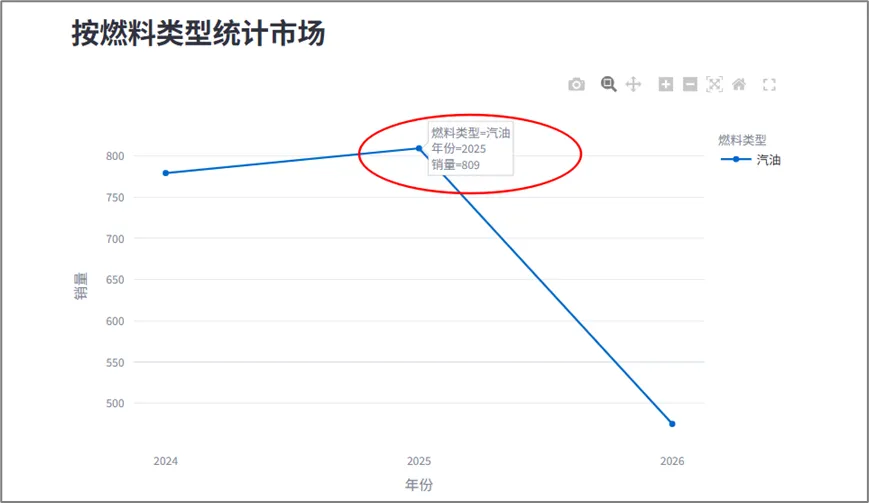
今天的分享就到这儿啦,非常感谢您对“Python SQL审天下”公众号的关注和点赞。如果您觉得我的公众号能给您带来一丝丝的收获,请多多转发给您的朋友圈,让更多的人看到并了解。也许您不经意间的点赞和转发,会给他人带来独特的体验和感受。

