正则表达式是VBA/Python里的重要表达式,Excel 365将其新增为工作表函数,作为文本处理函数,大幅提升了工作表中文本处理的能力。新增的正则表达式函数有三个:REGEXEXTRACT函数主要用于提取文本(相当于之前的left、mid、right等文本提取函数),但相对于之前的文本提取函数该函数更加高效。同时新增的还有REGEXTEST和REGEXREPLACE,这两个函数分别用于文本测试和文本替换,正则表达式的三个函数都可以用来处理规则复杂的文本(比如邮箱,手机号等等)。 这里以文本提取函数REGEXEXTRACT为例,介绍其一般用法。 REGEXEXTRACT 函数允许基于提供的正则表达式从字符串中提取文本,函数所提取的字符为文本形式,如要转换为数值则需要减负运算或使用value函数。 可以从第一个匹配中提取第一个匹配项、所有匹配项或捕获组。
语法结构为:
REGEXEXTRACT (文本、模式、[return_mode]、[case_sensitivity])
参数说明:
文本:文本或对包含要从中提取字符串的文本的单元格的引用。
模式:正则表达式 (“regex”) ,用于描述要提取的文本模式。注意该参数必须用""符号括起来,比如"\d+"。
return_mode:
一个数字,指定要提取的字符串。 默认情况下,返回模式为 0。 可能的值为:
0: 返回与模式匹配的第一个字符串
1: 以数组形式返回与模式匹配的所有字符串
2: 以数组的形式返回第一个匹配项中的捕获组
注意:捕获组是正则表达式模式的一部分,用括号“ (...) ”括起来。 它们允许单独返回单个匹配的单独部分。
case_sensitivity:
确定匹配项是否区分大小写。 默认情况下,匹配项区分大小写。 输入以下内容之一:
0: 区分大小写
1: 不区分大小写
模式中最常用的规则有:
1、[]方括号:匹配方括号中任意一个字符。如下表:
也可使用以下简写法:
2、控制重复的次数:默认情况下正则匹配最长的可能。当需要控制次数时,参考下表方式:
3、()分组捕获:
4、选择(或)|
优先级最低,表示“或”关系。
示例:"苹果|香蕉|橙子" → 匹配三者中任意一个。
5、转义\
如果要匹配 . * + ? ^ $ { } [ ] ( ) | \ 这些元字符本身,前面加反斜杠。
6、常用实战模版(可直接套用)
| |
| [A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,} |
| |
| \b((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)\b |
| [一-龟]+ 或者 [一-龢]+ |
| |
| |
| |
比如以下示例:
| | | |
| 联系人:王晓明;电子邮件:Wxming012@Aiedu.cn;电话:13890453674 | | | |
| =INDEX(REGEXEXTRACT(A57,"[一-龟]+",1),2) | =REGEXEXTRACT(A57,"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}") | =REGEXEXTRACT(A57,"1[3-9]\d{9}") |
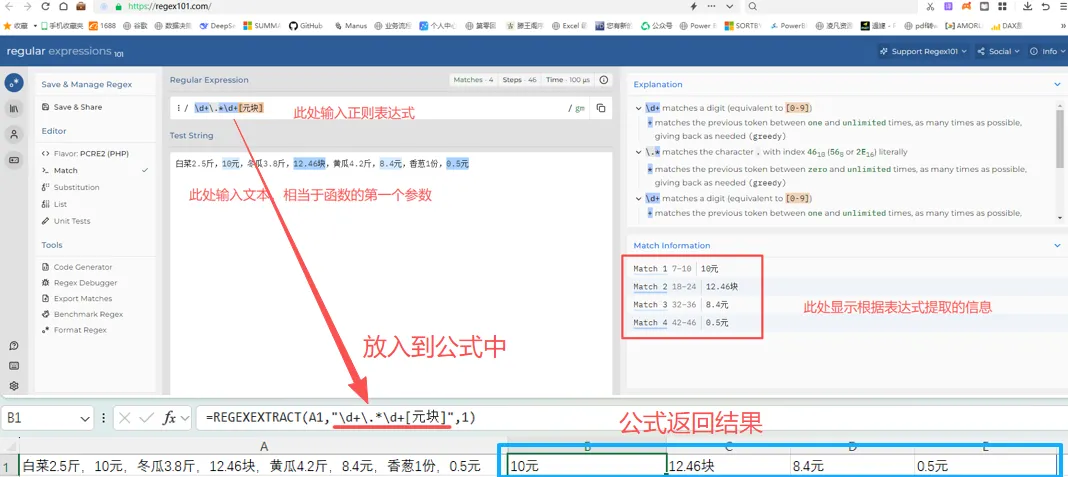
正则表达式可以在网站“https://regex101.com/”进行测试,看所写模式是否正确。比如获取文本中的金额:如下图所示:
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
