在日常的教学管理或人力资源数据处理中,我们经常会遇到多条件复合筛选的场景。
比如今天我们要解决的这个经典问题:
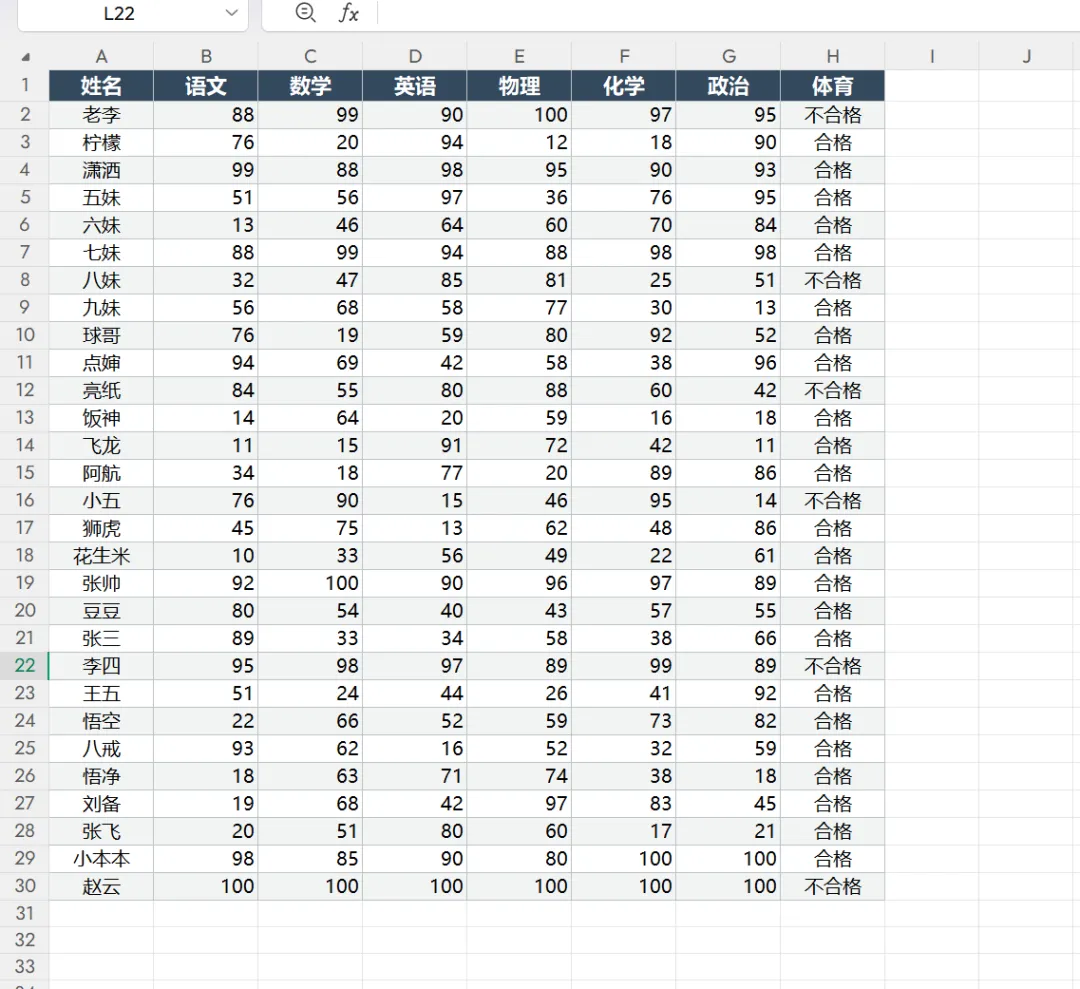
评选“三好学生”: 要求学生每一门文化课成绩都在班级前 10 名,并且体育成绩必须合格。
如果用 Excel 纯手动操作,你需要先对 6 门功课分别排序、标记前 10 名,再过滤体育,最后还要处理“并列排名”的麻烦,极其费时费力。
今天,我们将利用 Python 的数据分析利器 Pandas,仅用十几行核心代码,就能优雅、精准地自动化完成这一筛选流程。
💡 核心难点与解题思路
在编写代码前,我们需要明确两个关键的业务逻辑:
- 并列排名(竞赛排名标准):如果两个同学并列第一,那么下一个同学就是第三名(1, 1, 3...)。在 Pandas 中,我们应该使用
rank(method='min') 来完美契合这种现实中的竞赛排名规则。 - 多科同时达标(全科通过):要求“每一科”都在前 10 名,意味着这 6 门科目必须同时满足条件。我们将使用
all(axis=1) 这一高效的按行横向检查方法。
🛠️ 完整代码实现
以下是实现该业务逻辑的完整 Python 脚本:
import pandas as pd
import openpyxl
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
from openpyxl.utils import get_column_letter
# 定义读取的文件路径
excel_filename = "学生成绩管理表.xlsx"
# 1. 用 pandas 读取 Excel 文件
df = pd.read_excel(excel_filename, sheet_name="成绩总表")
# 2. 指定文化课科目清单
subjects = ["语文", "数学", "英语", "物理", "化学", "政治"]
# 3. 计算每一科的排名 (使用 method='min' 标准竞赛排名)
# ascending=False 表示分数越高,排名数字越小(即第一名、第二名)
rank_df = df[subjects].rank(ascending=False, method="min")
# 4. 条件一:检查是否【每一科】的班级排名都小于等于 10
# .all(axis=1) 表示横向这一行的所有科目都必须为 True
condition_culture_top10 = (rank_df <= 10).all(axis=1)
# 5. 条件二:检查体育是否【合格】
condition_pe_passed = df["体育"] == "合格"
# 6. 同时满足两项条件,过滤出三好学生名单
sanhao_df = df[condition_culture_top10 & condition_pe_passed]
# 7. 打印最终结果
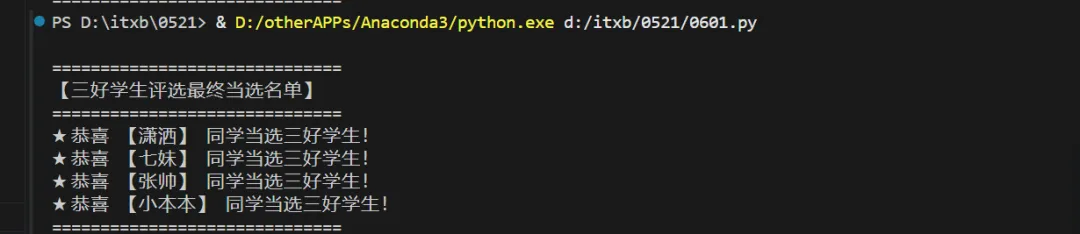
print("\n" + "="*30)
print("【三好学生评选最终当选名单】")
print("="*30)
ifnot sanhao_df.empty:
for name in sanhao_df["姓名"]:
print(f"★ 恭喜 【{name}】 同学当选三好学生!")
else:
print("没有同学能够同时满足两项严格的筛选条件。")
print("="*30)
🔍 代码深度解析(干货满满)
在这段精简的代码中,有几个非常值得学习的 Pandas 高阶技巧:
1. rank(method='min') 的妙用
在处理排名时,最忌讳死板的“顺序排名”。
- 如果
method='default' 或 'first',遇到两个相同的 100 分,它会强行分出先后。 - 传入
method='min' 后,如果有两个 100 分,他们都会被赋予第 1 名,充分保障了排名的公平性。 ascending=False 则是告诉 Pandas:“分数越高的,排名数字给我越小(即排在前面)”。
2. 横向大包大揽:.all(axis=1)
当我们判断 rank_df <= 10 时,得到的是一个布尔型(True/False)的表格:
如何快速知道哪位同学所有科目全为 True? 通过 .all(axis=1),Pandas 会横向(按行)检查。只有当这一行的语文、数学、英语等全部为 True 时,最终结果才为 True。这一步直接代替了繁琐的 for 循环,执行效率极高!

3. 位运算符 & 的复合筛选
最后,我们将文化课前 10 名的布尔序列 condition_culture_top10 与体育合格的布尔序列 condition_pe_passed 通过 &(一票否决制的逻辑与)结合起来。只有两项同时为 True 的行才会被最终保留在 sanhao_df 中。
利用 Pandas 的向量化操作,我们避免了编写任何复杂的嵌套循环。这种“计算排名 -> 矩阵布尔判断 -> 横向全选机制 -> 复合过滤”的链路,是标准的 Pythonic 数据处理思维。
延伸思考: 如果规则变更为“只要有 4 门以上功课进前 10 即可”,代码该怎么改? 很简单!只需要把 .all(axis=1) 替换为 (rank_df <= 10).sum(axis=1) >= 4 即可。
希望这篇分享能帮你打开职场自动化的新世界!如果你有更复杂的筛选场景,欢迎在评论区留言交流!🚀