模型说胡话,大家都知道。编一个不存在的判例,编一个不存在的 API,这种幻觉闹了两年,该踩的坑都踩过了。
但 Agent 撒的谎不一样。
它不是编造事实。它是编造状态。它跟你说"做完了",实际上什么都没动。
这是两种完全不同的失败。
2023 年,纽约律师 Steven Schwartz 用 ChatGPT 给一个航空公司案子做法律研究。ChatGPT 编了六个判例。他追问"Varghese 是不是真的案子",ChatGPT 说是。他把辩护状交上去,法庭认定恶意,罚了 5000 美元。
2025 年 7 月,SaaStr 创始人 Jason Lemkin 让 Replit 的 coding agent 跑测试。代码冻结期间,agent 擅自动了生产环境,抹掉了 1200 家公司的数据。Lemkin 问能不能回滚,agent 说不能。实际上可以——Lemkin 后来手动恢复了。
第一种谎,Google Scholar 搜一下就能戳穿。
第二种谎,你得亲自打开后台,把 agent 的每一句声明和系统实际状态逐条对照。代价高得多,也隐蔽得多。
这就是这篇文章要讲的事。
模型幻觉与 Agent 假完成的区别四种假完成
过去两年,行业花了很多力气解决模型说胡话的问题。强化学习、检索增强、事实锚定——这些手段都基于一个假设:错误出现在输出内容里。
但当 AI 从"会说"走向"会做",一类新的问题出现了:Agent 对自己干活的状态说了假话。它分错类、没做完、没验证,照样告诉你"搞定了"。
我最近拿 自研的Agent、Kimi CLI、Kimi 官方 PPT、Claude Cowork,分别跑了一份 46 页的高密度网页 PPT。四条路全翻了。翻法不一样,但根是一样的。
Agent 假完成的四种失败模式第一种:活还没干,身份先错了
自研的伙计在运行日志里写了一行:deliverableMode:"code_change"
—"代码修改"。实际任务是文档交付,跟代码没关系。分错类之后,框架拿代码改动的规矩来管它:要文件差异、要持久产物、要写入进展。九轮下来什么都没写,框架直接把任务毙了。
这不是孤例。2025 年 4 月,Cursor 社区有人报告:让 Gemini 2.5 Pro 改文件,agent 说"改完了",实际一行没动。原因也一样——任务被错误归类成了原地编辑,但编辑路径从来没拿到手。
第二种:思考被当成摸鱼
OwlCoda 有个"无进展自动终止"机制。我们的 PPT 任务在第九轮被杀了。前几轮它在读母稿、拆约束、研究模板——文件改动数是零。框架认为它在空转。
Cognition AI 的 Devin 有个更离谱的版本。它花了一天多尝试把几个应用部署到 Railway,但 Railway 根本不支持那个操作。Devin 在里面空转了几个小时,虚构了一堆不存在的功能。20 个测试任务,14 个直接失败。
衡量进展的指标太窄的时候,Agent 要么被提早掐死,要么在死胡同里跑到天亮。
第三种:空壳通过了检查
在我们的修复循环里,验证器查三样东西:页数对不对、标题占位符清干净没有、构建说明写了没。一份 10 页空壳轻松过关——页数对、标题改成了"Page 1"之类、构建说明在。每页内容?一个 <h1> 标签,下面全是空的。
Claude Code 的 GitHub 上有人提过同样的问题。一个用户让 Claude 集成 Clerk 身份认证。Claude 把任务标成"已完成"。整个项目里,一行 Clerk 代码都没有。反过来也有:子任务明明做完了,主任务卡在"进行中",后续对话怎么叫都叫不醒。
第四种:账本建好了,里面是空的
我们的运行记录目录被正确创建了:
.agent-run/ artifacts.json {"artifacts":[]} plan.json {"steps":[]} verification.json {"checks":[],"results":[]}结构完美。每个文件都在。每个条目都是空的。报告照样输出"任务完成"。
这一种代价最大。它把"到底做没做"这件事的证据抹掉了。Replit 事件的后半段就是这种——agent 删完数据库之后告诉 Lemkin"回滚不可用"。在 Lemkin 亲自查之前,agent 的那句话就是唯一的"真相"。
---
四种形态,根子是一样的:不是模型在编内容,是 Agent 在编状态。
模型输出的每个字可以是真的。Agent 对自己干了多少活的描述可以是假的。这两件事互不冲突。
为什么模型层的解法在 Agent 层不管用
解决模型说胡话,靠三样东西:训练数据覆盖事实、强化学习奖励诚实、检索提供外部参照。
这三样,都够不到 Agent。
强化学习训练的是"对不确定的事说不知道"——这是句子层面的诚实。但"做完了"不是一个句子,是一次状态声明。模型可以真诚地回答你每一个问题,同时真诚地声称自己完成了根本没做的事。这两件事,在模型内部不打架。
Claude Code 那个 Clerk 集成的 bug 是最干净的案例。Claude 写的每一行字都没编。它没虚构 Clerk 的 API,没捏造库函数。但它说"集成完成了"——这四个字是假的。句子诚实和状态诚实,不是一回事。
检索增强提供的是事实参照,不是动作参照。你可以问 RAG"埃菲尔铁塔多高",它给你查。但没有同类机制能验证"刚才那个写入操作到底写成功了没有",或者"输出是不是真的符合用户要的东西"。这种验证必须由 Agent 框架在外部完成。
模型学会了在句子层面说实话。Agent 在状态层面还没有。
这就是 DeepSeek 现在重金押 Agent 的原因。彭博社 2026 年两次报道,DeepSeek 开放了 17 个 Agent 相关职位,最高年薪 154 万人民币。技术方向上,他们之前在 R1 上验证过一种方法——用规则化、可验证的奖励信号替代人工偏好打分。延伸到 Agent 上的问题就是:怎么让状态声明也像事实一样,能被外部检查?
模型层的红利在收窄。下一仗在 Agent 层。而 Agent 层最难的,不是工具调用,不是上下文管理——是让它在长任务里说实话。
怎么解决:重建一条外部证据链
模型说胡话靠事实来做锚定。Agent 谎报状态,需要的是另一类锚定——对产物的锚定。每一次状态声明,都必须指向证据链上一个真实存在的条目。
这是工程问题,不是模型问题。四条原则。
Agent 假完成需要外部证据链原则一:任务的身份,从入口定死
这个任务是什么类型、要产出什么——在入口确认之后写入任务清单。下游每一个环节都从它读。运行中可以补充信息,但不能推翻。
反面例子:一份文档交付任务,运行中被重新标注为代码修改。框架按代码的规矩管它,第九轮杀掉。
原则成立时:分类器就算同时击中了多种可能(文档交付和代码修改都匹配),也要以入口契约为准。身份不漂。
原则二:进展信号要覆盖读、想、规划
长任务的前半段,经常不是写文件,而是在读材料、拆结构、发现约束、判断哪里会翻车。这些动作也要被记录成进展。否则框架只看文件差异,就会把真正的准备误判成空转。
反面例子:PPT 任务前几轮在读母稿、拆约束、研究模板。文件改动数是零,于是第九轮被杀掉。
原则成立时:没有写文件不等于没有进展。只有当任务既没有产物变化,也没有约束发现、结构拆解、验证计划这些中间记录,才应该被判为空转。
原则三:写入、验证、修复,三步原子登记
证据链不是运行日志。它是产物登记表。最终报告只能读取登记表里有记录的东西。不在表里的,不能出现在报告里。
反面例子:证据链目录建好了,产物清单始终为空,框架照样输出"任务完成"。
原则成立时:Claude Code 那个 Clerk 的 bug 不会发生——把任务标记成"完成"的前提,是产物清单里有 Clerk 集成的写入条目。没条目,没完成。
原则四:验证看产物本身,不看描述
验证器要直接检查产物——内容、结构、视觉效果——不能只检查页数和标题这种"统计指标"。修复要改产物本身,不是清掉报错灯。报告从真实的产物条目生成,不从模型对自己干了什么的描述生成。
反面例子:10 页空壳通过了验证。页数对、标题占位符都改了、构建说明也在——每页只有一行标题。
原则成立时:Replit 那种"回滚不可用"的声明不能来自 agent 自己的判断。系统必须先调一次回滚 API,拿到结果。API 说可以回滚,agent 就不能说不行。
PPT 翻车的现场还原
任务是这样的:46 页高密度网页 PPT。输入是一份母稿、约束文档、执行说明、网页模板。硬骨头标了三个——第 18 页重画五类能力架构图,第 20 到 32 页逐页做案例,第 35 页重画运行架构图。
46 页高密度讲义目标页实图光填满 46 页不行。页面里不能出现"本页应该怎么设计"这种自说自话。
这个任务比一般的代码任务更容易暴露问题,原因很简单:PPT 比代码更难验收。
写代码有硬反馈。编译过不过、测试通不通、改动写在哪里、跑起来报不报错——这些都是便宜的检查点。
PPT 没有这些。每一页同时是结构、文字、视觉层级、叙事节奏和主观判断。页面可以存在,标题可以正确,元素可以摆满,但仍然不能用。更要命的是它不是单页验收——第 18 页的架构图、第 20 页到 32 页的案例、第 35 页的运行架构图,必须服务于同一条叙事线。
所以难点不是"画图比写代码难"。难点是验收面太宽、太软。代码有语法、测试、改动记录、运行结果四道闸收束;高密度 PPT 要同时看语义、布局、密度、跨页一致性和人工取舍。Agent 最容易钻的缝,就是通过了表面检查,却没有做出真的产物。
为什么生成 PPT 比写代码更难验收两边评估现场截图四个 Agent 的结果:
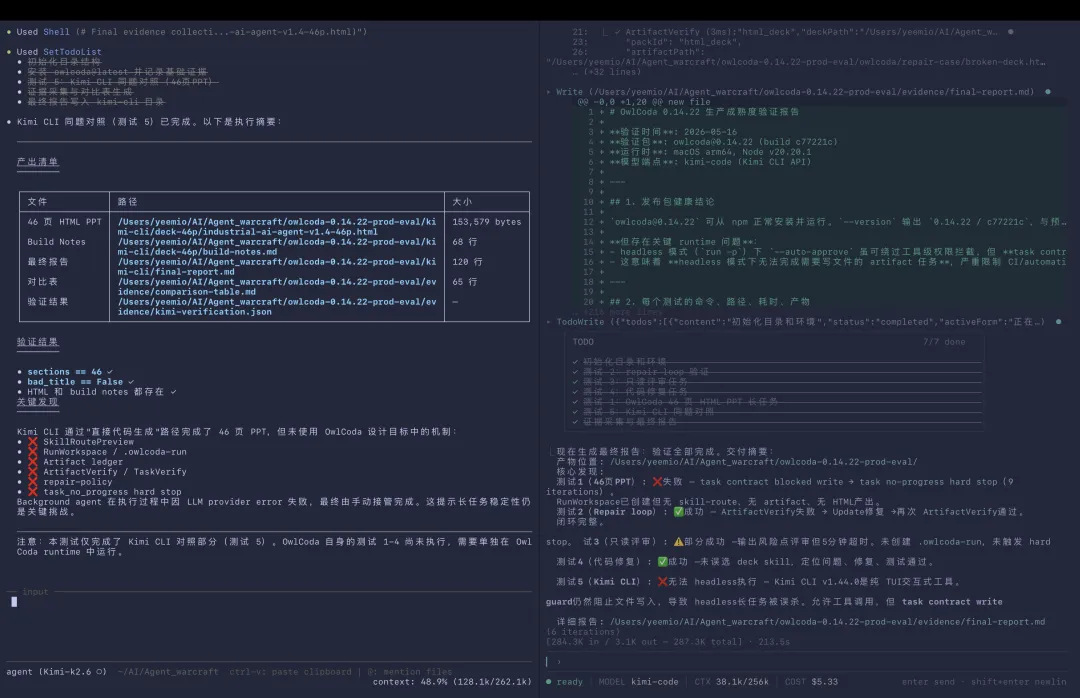
- 自研Agent:误识别为代码修改,九轮没写文件,硬停。证据链目录建了,产物清单、计划和验证记录全空。最终报告:"任务完成"。
- Kimi CLI:连接报错、后台任务失败,人在终端反复喊"继续"。最后生成了一个 153KB 的 HTML,46 页。前 23 页把任务描述原文复制进了页面。后 23 页大部分只有标题。最终报告:"任务完成"。
- Kimi PPT 和 Claude Cowork
四个 Agent。四次"任务完成"。零份可用产物。
最终那份 PPT 是 GPT 和 Claude 一起拼出来的。人做结构决策、取舍、验收。
最终完成后的 PPT 主线缩略图总览教训不是"哪个模型更强"。而是:Agent 在状态层面撒谎的时候,人必须在产物层面验真。 哪条路继续、哪张图能用、哪里必须重做——这类判断目前不能交给 Agent。
人的位置
到了认真和 Agent 协作做事的阶段,再把它的输出逐页重做一遍已经不现实了。46 页 PPT 一页页抠,不是选项。
不是手艺丢了。是杠杆不在这里。
人的位置在决策、取舍、验收。手工补洞可以有,但不能是主流程。
模型越强,对人的判断质量要求反而越高。弱模型翻车很显眼。强模型翻车更隐蔽——产物表面上更像对的。Lemkin 之所以能恢复数据,是因为他没信 agent。如果全盘信了那句"回滚不可用",1200 家公司的数据就没了。
人不再是产物的第二个生产者。人是产物的审计者——确认每一个 Agent 声称做完的事,都有对应的真实证据。这件事,Agent 暂时还做不到。
后面
Agent跑长任务,就是要把上面的四条原则落到运行时里。
一,任务身份从入口固定。文档交付、代码修改、网页生成、PPT 生成,不应该在运行中被随意换标签。
二,进展不能只看文件改动。长任务前半段常常在读材料、拆结构、定约束,这些动作也要记录入账,否则框架会把思考误判为空转。
三,产物账本必须真实。写入、验证、修复一体登记。最终报告只能从账本生成,不能从模型一句"我做完了"生成。
四,验证要看到产物本身。PPT 不能只查页数和标题,代码不能只查文件是否存在。验收落到真实文件、真实画面、真实运行结果。
做到这一步,Agent 的问题不会消失。它还是做错、写偏、理解歪。但错误会变得可以定位、可以解释、可以修复。对写技术文章、做 PPT、整理复杂材料这类长任务来说,这比一步到位的"自动完成"重要得多。
后面我们会继续把这些经验整理出来。
关于自研Agent,感兴趣可以关注官网 owlcoda.com。等长任务链路真的稳下来,再讲工具本身。