你有没有这样的经历——
花两小时写好一篇口播文案,然后对着空白编辑器发愁:做成视频 PPT 还得再花两小时排版、调动画、配节奏。文案写得好是一回事,把它变成能看的画面是另一回事。
更糟的是,大多数视频 PPT 工具要么太复杂(专业剪辑软件),要么太死板(模板套完千篇一律)。你想做的是"有自己风格的视觉呈现",但时间和技能都不够。
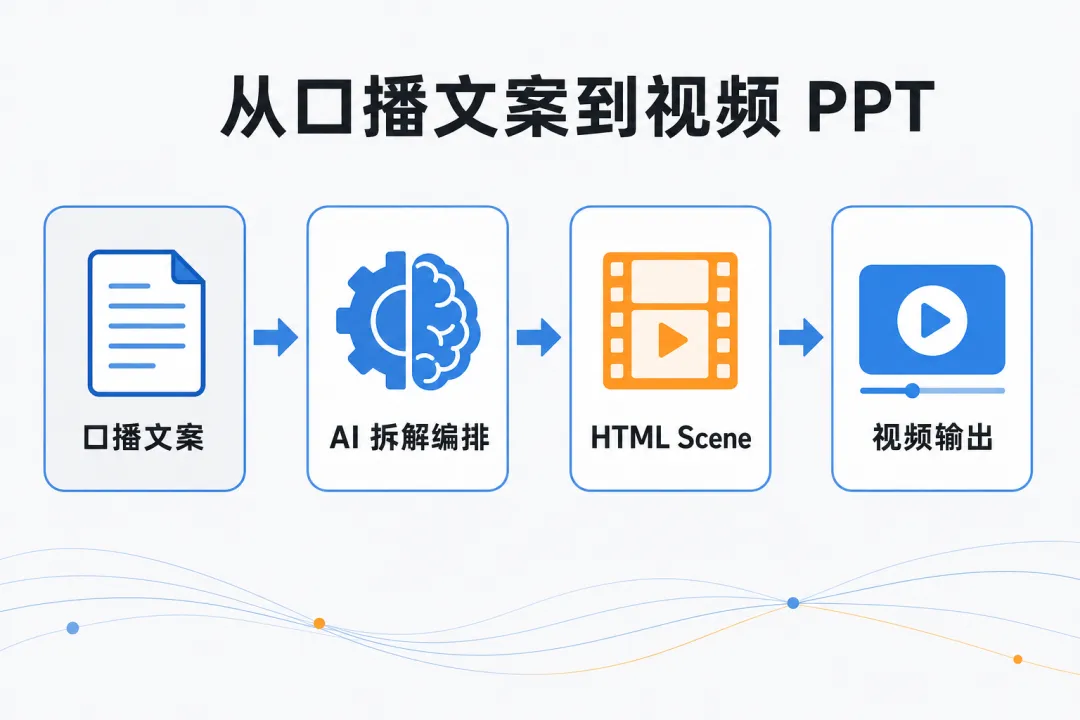
所以有了 ppt2video-skills。
这个 AI Agent 技能,能帮你在对话中完成"文案→视频 PPT"的全流程。你提供口播文案,它自动拆成 PPT 页、生成结构稿等你确认、让你选视觉主题,然后输出一套带 GSAP 动画的 HTML 视频画面。
这篇文章拆解它的一切:解决什么问题、怎么工作、技术底子是什么、实际用起来效果如何。
PART 01|它解决了什么核心痛点
先想一个问题:做视频 PPT 这件事,到底难在哪?
第一关:文案到画面的转换。 你有一段口播文案,但它不是 PPT 结构。哪里该新开一页?哪里该合并?哪句话适合做标题?哪段适合做金句?这些判断依赖叙事逻辑感——不是人人都有。
第二关:排版与视觉呈现。 确定页结构之后,每一页怎么排?标题放哪?配什么图?什么颜色?什么字体?这一关把绝大多数内容创作者挡在门外。模板能解决一部分,但一旦想跳出模板,难度陡增。
第三关:动画与节奏。 视频 PPT 和静态 PPT 最大的区别是"动"。文字怎么入场?什么时候切换?每页停留多久?动画节奏对口播的配合——这已经是专业动效设计师的领域了。
第四关:输出与渲染。 做好之后还得导出成视频。传统做法是在剪辑软件里重新拼一遍,或者用 PPT 自带的录制功能——质量和效率都打折扣。
ppt2video-skills 把所有四关串成一条自动化流水线。
它的定位很明确:让内容创作者只关心文案本身,画面呈现交给 AI。
它不是一个独立软件,而是一个 AI Agent 技能(Skill)。它运行在 AI Agent 环境中(Claude Code 或兼容的 Agent 框架),你通过对话来驱动它。你说"我有一篇口播文案,帮我做成视频 PPT",它就开始工作。
核心价值可以浓缩为一句话:把"做视频 PPT"这件事,从一场需要设计技能的马拉松,变成一次可以对话完成的任务。
PART 02|从文案到视频:四步流水线
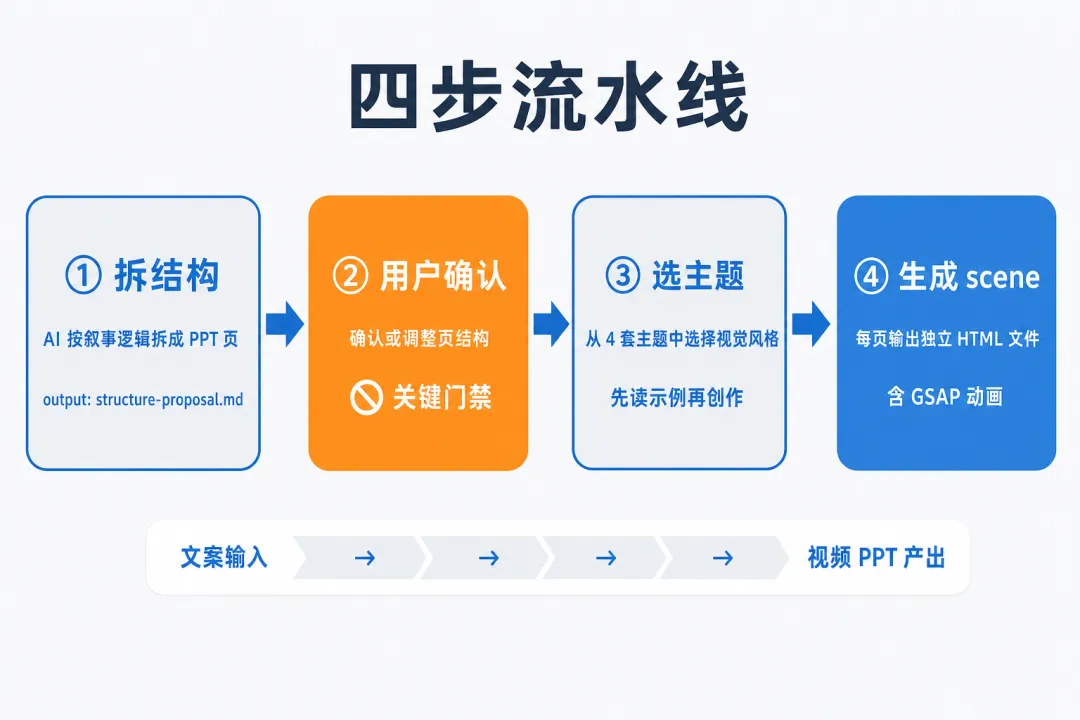
整套流程分四步走,每一步都有明确的输入和产出。
第一步:拆结构——让 AI 读懂你的文案
收到口播文案后,技能不做别的事,先读文案。
它会把文案按叙事逻辑拆成 PPT 页。但不是简单地按段落切——它会判断每一段的叙事角色:
- • 这是论证过程?→ 可能分 2-3 页,每页讲一个要点
拆完后输出一份 结构确认稿(structure-proposal.md),包含:
这份确认稿就是第一阶段的产出。
第二步:用户确认——人与 AI 协同
结构确认稿推给你看,你确认或调整。
这是整个流程中最关键的设计。它不是黑盒全自动——AI 拆的结构不一定完美,需要你来把关。
你可以说"第 3 页和第 4 页合并"、"第 5 页拆成两页"、"给第 2 页加一句话"。改完确认后,技能才会进入下一步。
第三步:选主题——决定视觉风格
确认完页结构后,你需要选择一套视觉主题。技能预置了 4 套主题,展示给你预览:
| | |
|---|
| guizang-magazine-demo | | |
| guizang-swiss-demo | | |
| handdrawn-whiteboard-demo | | |
| launch-minimal-demo | | |
选好主题后,技能会先读取该主题目录下的 3-5 个真实 HTML 示例,总结它的风格语法——背景怎么处理、标题层级怎么用、颜色角色怎么分配——然后再生成新页面。
这是"先看示例再创作"的设计,保证产出风格统一,而不是 AI 凭空想象出来的画面。
第四步:生成 scene——每页一个独立 HTML
最后一步,技能为每一页 PPT 生成一个独立的 HTML 文件,称为一个 "scene"。
每页 scene 的结构:
- • 固定画布尺寸(默认 1080×1440 竖屏)
- • GSAP 动画时间线(3-6 个入场动作,以 opacity / x / y / scale 为主)
- • HyperFrames 兼容结构(可被视频渲染框架识别)
同时产出的配套文件:
- • subtitle-scene-map.md:脚本行与 scene 编号的映射
- • scene-design-plan.md:每页的设计思路说明
整套流水线的价值不在某一项技术有多强,而在每一步之间无缝衔接——文案进,一套完整的视频 PPT 素材出。
PART 03|技术基础:HyperFrames + GSAP
ppt2video-skills 的输出是 HTML,但这不是普通的网页——它是可以被渲染为视频的视频画面。
HyperFrames:用 HTML 做视频
HyperFrames 是一个开源框架,它的核心思路是:用 HTML + CSS + JavaScript 来描述视频画面,然后渲染成视频文件。
每一页 scene 是一个独立的 HTML 文件,包含固定尺寸的画布、视觉内容、和动画时间线。HyperFrames 框架可以识别这些 HTML,按时间线播放并录制为视频。
这在业界被称为"声明式视频"——你声明每一帧长什么样,框架负责把它变成视频。好处是:可编程、可版本控制、可精确到毫秒。
GSAP 动画
每一页的动画使用 GSAP(GreenSock Animation Platform)驱动。GSAP 是业界最成熟的 Web 动画库之一,相比 CSS animation 更可控,相比手写 JavaScript 动画更高效。
每页的动画设计原则:
- • 以 opacity / x / y / scale 为主,这些属性渲染性能最好
- • 先写静态画面,再加动画——确保最终画面正确,动画只负责"怎么出现"
- • 禁止 repeat: -1——视频 PPT 不需要无限循环
一条典型的时间线:标题从下方滑入(y: 100 → 0),正文渐显(opacity: 0 → 1),装饰元素依次入场。每页 4-8 秒,配合同步口播。
主题机制:先看示例再创作
主题系统是 ppt2video-skills 最有特色的设计。
它不是让 AI 凭空"设计"风格,而是让 AI 先读真实主题 HTML,提取风格规则,再按规则生成新页面。
工作流:
- 1. 技能读取选中主题目录下的 3-5 个 scene HTML
- 2. 提取背景处理、颜色角色、标题层级、布局模式、动画节奏
这意味着:主题目录里的示例越多,AI 生成的质量越稳定。主题不是一个配置文件,而是一组真实 HTML 示例——AI 通过阅读它们来理解你想要的风格。
渲染安全:为什么不用复杂 CSS
视频渲染引擎对 CSS 的支持度不如浏览器。一些在浏览器中正常的效果,在渲染时可能丢帧、错位或不显示。
禁止使用的 CSS 特性:
- •
backdrop-filter — 视频渲染器不支持 - •
mix-blend-mode — 混合模式在渲染时不可预测 - •
filter: blur() — 多层模糊会严重拖慢渲染
推荐的样式策略: 实色背景、简单渐变、高对比文字、轻量边框与单层阴影。
这也是 ppt2video-skills 的设计哲学之一:宁可设计上克制一点,也要保证渲染稳定。
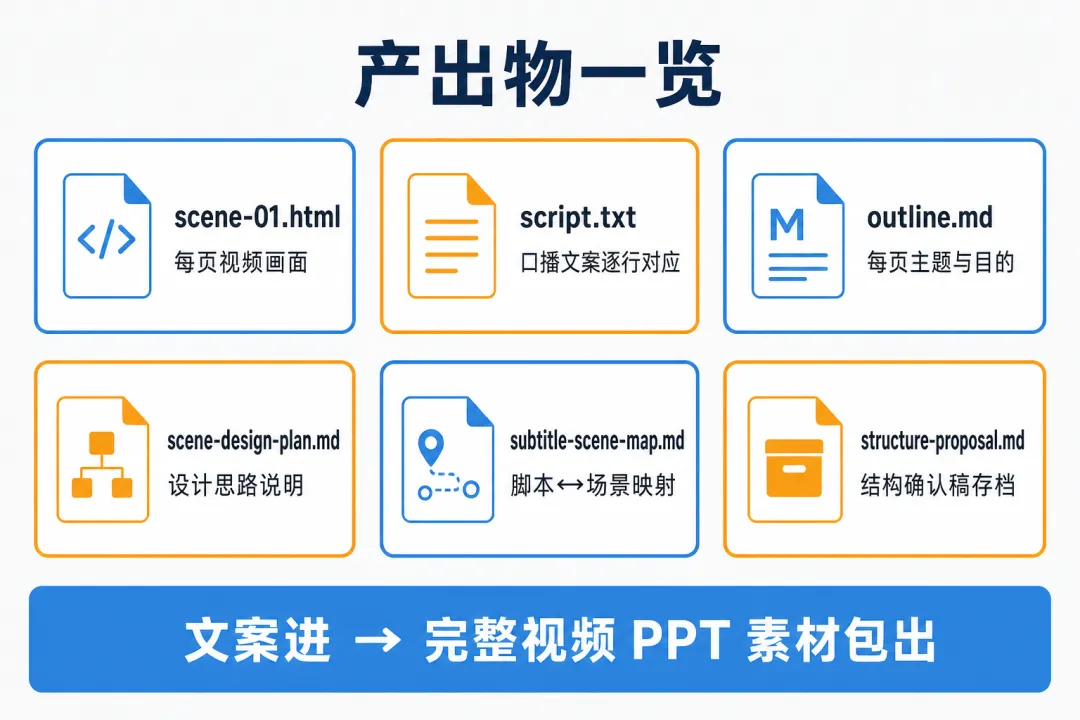
产出物一览
| |
|---|
scene-01.html | |
script.txt | |
outline.md | |
subtitle-scene-map.md | |
scene-design-plan.md | |
structure-proposal.md | |
每个文件都有明确用途,组成一套完整的视频 PPT 制作素材包。
PART 04|上手实操:完整流程演示
下面用一个简化的例子,看实际走一遍是什么效果。
输入
假设你的口播文案开头是这样:
很多人觉得做视频很难,但其实只需要三步。第一步,想清楚你要说什么。第二步,写下来。第三步,把它讲给别人听。就这么简单。
第一步输出:结构确认稿
技能读完后,输出结构确认稿:
# PPT 结构确认稿- 核心主题:做视频只需要三步- 建议尺寸:1080 × 1440- 建议页数:5 页| 页码 | 页面主题 | 对应原文 | 拆分理由 ||------|---------|---------|---------|| 01 | 开场:你觉得做视频难吗? | 第一句 | 制造共鸣,作为第一眼钩子 || 02 | 原因分析:为什么觉得难 | 隐含前提 | 过渡页,引出解决方案 || 03 | 第一步:想清楚说什么 | "第一步..." | 核心方法第一步 || 04 | 第二步:写下来 + 讲出来 | "第二步...第三步..." | 两个短步骤合并一页 || 05 | 总结金句 | 最后一句 | 收束结尾,留印象 |
用户确认
你说"第 4 页内容有点多,拆成两页"。技能调整后进入下一步。
选主题
你打开主题预览,选了 guizang-swiss-demo(瑞士风,干净极简)。
技能读取该主题下的示例 HTML,总结风格规则:黑白配色为主、少量蓝色强调色、网格布局、标题用无衬线字体、内容区有左右分栏和上下分层两种模式。
最终产出
output/├── scene-01.html├── scene-02.html├── scene-03.html├── scene-04.html├── scene-05.html├── script.txt├── outline.md├── subtitle-scene-map.md├── scene-design-plan.md└── structure-proposal.md
每个 scene HTML 打开后,可以看到对应的动画画面:标题滑入、正文渐显、元素依次入场。
这个过程,在对话中完成。从你给出文案到拿到全部产出,核心操作只有两件事——确认页结构、选择主题风格。
PART 05|适用场景与边界
谁最适合用
核心优势
可控。 每一页 scene 是独立的 HTML 文件,可以单独打开、修改、替换。不需要在剪辑软件里重新拼一遍。
可编辑。 懂一点 HTML 的人可以直接改代码——改文字、换颜色、调动画时长。不需要专业视频编辑技能。
渲染稳定。 有明确的"渲染安全 CSS"规则,避免了大多数导出问题。
主题化。 预置 4 套风格各异的主题,且主题是"可阅读的 HTML 示例"而非配置文件——这意味着主题库可以不断扩展。
无需设计基础。 你不需要会排版、动效、配色。AI 帮你完成,你只需要判断"这个结构对不对"和"这套风格适不适合"。
当前边界
依赖 AI Agent 环境。 ppt2video-skills 是一个技能,不是独立应用。它需要运行在 Claude Code 或兼容的 AI Agent 框架中。
主题库目前 4 套。 4 套主题覆盖了常见风格,但如果你有非常特定的品牌视觉要求,可能需要定制主题。
适合竖屏内容。 默认 1080×1440 竖屏尺寸,适合视频号、抖音、快手等竖屏平台。横屏内容需要额外适配。
非实时渲染。 输出的是 HTML scene,不是 MP4 视频。需要配合视频渲染工具(HyperFrames)来生成最终视频文件。
写在最后
视频内容创作这件事,这几年发生了两次变化。
第一次是智能手机普及——人人都有了拍摄设备。第二次是剪映这类工具普及——人人都有了剪辑能力。
第三次正在发生:AI 开始介入内容制作的中台环节。不是你写好文案后再"顺便"做个视频配图,而是 AI 自动把文案变成画面、排好版、加好动画、准备好渲染。
ppt2video-skills 是第三次变化中的一个具体产品。它的价值不在于技术复杂——HyperFrames 和 GSAP 都是成熟技术——而在于它把"从文案到视频 PPT"这条链路,变成了一个可对话、可确认、可自动执行的流程。
如果你已经在用 AI Agent,又有口播文案需要做成视频,可以试试。输入文案,AI 帮你排好版、配好动画,你只需要确认方向和选主题。
剩下的交给技能就好。
技能信息
- GitHub:https://github.com/dayuanlog/ppt2video
- 预置主题:4 套(杂志风 / 瑞士风 / 手绘白板 / 极简发布)
- 运行环境:Claude Code 或兼容 AI Agent 框架
安装方法
将仓库克隆到 AI Agent 的技能目录即可:
git clone https://github.com/dayuanlog/ppt2video.git ~/.claude/skills/ppt2video-skills
或者直接和Claude Code / Openclaw /Hermes 说:
请帮我安装这个skill:https://github.com/dayuanlog/ppt2video
既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见