怎么用codex做一个可以修改的汇报 PPT的智能体
- 2026-06-11 11:31:08
比如让它“保持风格统一”“输出专业美观”“适合政府汇报”“注意版式和配色”。
这些话当然可以写。
但是你真拿它去做项目汇报 PPT,很快就会发现一个问题:提示词越写越长,页面还是会跑。
今天像模板,明天像海报。
第一页还算规矩,第三页突然变成科技发布会。
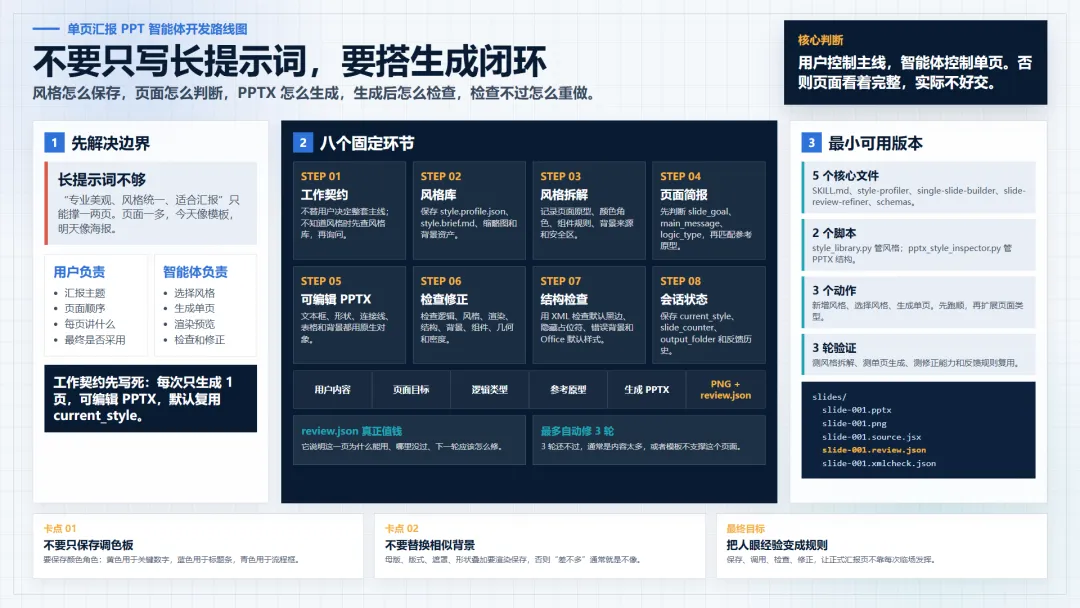
所以我觉得,做这种单页汇报 PPT 智能体,真正应该先做的,是把它拆成几个固定环节。
风格怎么保存,页面怎么判断,PPT 怎么生成,生成后怎么检查,检查不过怎么重做。
这些事情搭起来以后,智能体才像一个能干活的助手,不会每次都临场发挥。
适用读者
这篇适合已经有一点智能体基础的人。
比如说,你知道 Codex 技能、提示词、文件结构、脚本工具大概是怎么配合的,也知道 PPTX 最后要能编辑,不能只导出一张图片。
如果你现在只想使用这个智能体,可以先看上一篇使用教程。
这一篇讲开发。
更准确一点,讲怎么把一个“逐页生成、风格复用、用户控制主线”的 PPT 智能体做出来。
你将完成什么
做完以后,这个智能体要能处理 5 件事。
用户第一次提供 PPTX、截图或样张时,智能体能拆解并保存一套 PPT 风格。
用户后续做页面时,智能体能记住当前默认风格。
用户只说“这一页讲什么”,智能体能判断页面逻辑。
智能体每次只生成 1 页可编辑 PPT。
生成以后,智能体能导出 PNG,写检查文件,并根据检查结果最多修 3 轮。
最后的输出应该长这样:
slides/ slide-001.pptx slide-001.png slide-001.source.jsx slide-001.review.json slide-001.xmlcheck.json
真正值钱的地方,是 review.json 这个检查文件。
因为它告诉你这一页为什么能用,哪里没过,下一轮应该怎么修。
先想清楚:这个智能体到底管什么
做这个智能体之前,先把分工写死。
用户负责:
汇报主题;
页面顺序;
每一页讲什么;
哪些页面最终进入整套汇报。
智能体负责:
选择当前风格;
拆解模板;
生成单页 PPT;
渲染预览图;
检查页面;
修正当前页。
一定不要让智能体同时管所有东西。
它一旦开始替用户决定整套汇报主线,很容易把 PPT 做成“看起来完整,实际不好交”的材料。
这个智能体的边界就一句话:
用户控制主线,智能体控制单页。第一步:写清智能体的工作契约
先建一个技能。
最少需要一个 SKILL.md。
里面不要先写审美词,先写工作契约。
可以这样定:
# 单页汇报 PPT 智能体这个技能只负责单页汇报 PPT 的生成入口。工作契约:- 每次用户提出一页需求,只生成 1 页。- 用户选择或创建风格后,在当前会话里保存 `current_style`。- 后续页面默认复用 `current_style`,不要反复询问。- 如果还不知道 `current_style`,先检查风格库,再询问用户。- 如果风格库为空,要求用户先用 PPTX、截图或样张创建第一个风格。- 只有用户明确要求换风格或换模板时,才切换风格。- 不替用户决定整套汇报主线、总页数和最终页序。- 除非用户单独要求,否则不组装完整 PPT。
你看,真正有用的提示词,先解决的是权责问题。
它要知道自己什么时候能做,什么时候不能做,什么时候必须先问用户要模板。
如果这个契约不写,后面所有模块都会乱。
第二步:设计风格库
这个智能体不能每次从聊天记录里猜风格。
它需要一个风格库。
推荐路径:
%USERPROFILE%\.codex\ppt-style-library\ styles\ <style-slug>\ style.profile.json style.brief.md thumbnail.png assets\ backgrounds\ patterns\ logos\ references\
这里面最重要的是两个文件。
style.profile.json 给机器看。
它记录背景、颜色角色、版式区域、组件样式、页面原型、禁止替换项、用户反馈规则。
style.brief.md 给后续智能体看。
它用人话说明这套风格适合什么页面,哪些东西要保留,哪些东西一改就不像。
我的建议是,风格库至少保存这些信息:
{"style_name": "","style_slug": "","source_type": "pptx","canvas": {"aspect_ratio": "16:9","width": 13.333,"height": 7.5,"units": "in" },"backgrounds": {"content": {"asset": "assets/backgrounds/content-background.png","usage": "full_bleed","text_safe_area": {},"source_type": "layout_render","fidelity_required": true } },"reference_archetypes": [],"color_role_bindings": {},"component_tokens": {},"feedback_rules": []}
这里有一个非常容易被忽略的点。
颜色不要只存成调色板。
调色板只告诉你有哪些颜色,不能告诉你颜色该怎么用。
比如黄色在原模板里只用来标关键数字,你就要写成:
{"metric_highlight": {"color": "#F6C244","rule": "只用于行内关键数字或关键词;除非页面原型允许,否则不要做成独立指标卡" }}
否则智能体很可能把黄色铺满整页,最后页面直接变味。
第三步:做风格拆解模块
风格拆解模块负责把用户给的 PPTX、截图、样张变成风格包。
这个模块可以叫:
references/style-profiler.md它要做 4 件事。
第一,规范输入。
如果用户给的是 PPTX,先把代表性页面渲染出来。
不要只看文件里的图片素材。
很多 PPT 的背景来自母版、版式、遮罩、形状叠加。你只抽媒体文件,很容易抽错。
第二,拆页面结构。
要记录:
标题区在哪里;
正文区在哪里;
标签区在哪里;
图表区在哪里;
页脚和页码在哪里;
安全边距是多少;
页面常见原型有哪些。
这里的原型很重要。
比如一个模板里常见的页面可能是:
顶部标题条 + 左侧责任主体标签 + 中间多段流程框 + 小节点 + 细连接线 + 行内黄色指标这个东西比“蓝色科技风”有用太多。
第三,拆视觉规则。
要记录:
颜色角色;
字体层级;
透明度;
边框;
阴影;
圆角;
节点尺寸;
节点间距;
页面密度;
表格和图表样式。
第四,保存特殊背景。
如果模板有非纯色背景,就保存成资产。
比如:
assets/backgrounds/cover-background.pngassets/backgrounds/content-background.pngassets/backgrounds/data-background.png
而且要记录来源。
比如:
{"source_type": "layout_render","source_slide_index": 3,"source_layout_name": "Content Layout","contains_master_layers": true,"fidelity_required": true}
这一步的价值,是防止后续智能体找一个“差不多”的科技背景糊弄过去。
差不多,通常就是不像。
第四步:做单页生成模块
单页生成模块可以叫:
references/single-slide-builder.md它的任务很明确:
用户说一页内容,智能体生成一页 PPT。
生成之前,先做一个页面简报。
可以长这样:
{"slide_goal": "","main_message": "","logic_type": "parallel","reference_archetype": "","relation_direction": "left_to_right","layout_pattern": "","content_slots": [ {"role": "title","content": "" } ],"visual_priority": "","background_role": "content"}
这个页面简报解决一个老问题:智能体不能拿到文字就直接摆版。
它要先判断页面关系。
常见逻辑可以先定 10 类:
parallel 并列sequence 流程hierarchy 上下层级comparison 对比cause_effect 因果problem_solution 问题方案progressive 递进matrix 矩阵data_evidence 数据证明conclusion 结论页
然后再从风格包里找最接近的 reference_archetype。
这里的顺序不能反。
先找风格原型,再决定怎么适配页面内容。
如果直接按逻辑类型自由设计,页面很容易变成另一套模板。
一个比较稳的内部流程是:
用户内容 -> 提取页面目标 slide_goal -> 提取核心信息 main_message -> 判断页面逻辑 logic_type -> 匹配参考原型 reference_archetype -> 写适配计划 adaptation_plan -> 生成 PPTX -> 渲染 PNG
adaptation_plan 里至少要写清:
使用哪个背景;
保留哪些结构;
哪些组件必须沿用;
哪些颜色只能用在指定角色;
哪些替换行为要避开;
页面密度要接近什么范围;
用户之前的反馈规则有没有用上。
比如:
{"selected_archetype": "multi_scenario_stacked_flow","background_asset": "assets/backgrounds/content-background.png","must_preserve_components": ["top_title_bar","left_owner_labels","cyan_rounded_section_frames","small_process_nodes","thin_connectors","inline_yellow_metrics" ],"forbidden_substitutions_checked": ["large_kpi_card","generic_dashboard_card","new_tech_ring_background" ]}
只有这个计划写清楚了,后面生成 PPTX 才有依据。
第五步:生成可编辑 PPTX
这个智能体最好不要把整页做成一张截图。
办公汇报材料最后大概率还要改。
标题要改,数字要改,某个节点要删,领导一句话下来,页面就得微调。
所以最终输出要用 PPT 原生对象:
文本框;
形状;
连接线;
表格;
图表;
图片背景;
页脚;
标注。
可以用 JSX、Python PPTX 工具,或者现成的 PowerPoint 生成能力。
不管用哪种工具,都要守住一个原则:用户拿到 slide-001.pptx 后,要能继续编辑。
输出文件建议固定在当前工作区:
slides/ slide-001.pptx slide-001.png slide-001.source.jsx slide-001.review.json
slide-001.source.jsx 这个源码文件,可以记录这一页是怎么生成的。
后面要重做、查问题、复用结构,都靠它。
第六步:做检查和修正模块
检查模块可以叫:
references/slide-review-refiner.md这个模块要在 PPTX 生成以后马上运行。
它至少做 8 类检查。
第一,逻辑检查。
看这一页有没有保留用户原意,页面结构和内容关系是否匹配。
第二,风格检查。
看颜色、字体、组件、线条、卡片、箭头、图表是否符合当前风格。
第三,渲染检查。
看 PNG 有没有空白、资产缺失、文字溢出、遮挡、对比度过低。
第四,结构相似度检查。
看页面有没有保留选中的参考原型。
第五,背景来源检查。
看背景是否来自风格包里的资产,有没有被临时生成的相似背景替换。
第六,组件来源检查。
看流程节点、边框、连接线是否用了风格包里的组件规则。
第七,几何比例检查。
看标题条高度、节点尺寸、边距、间距有没有漂。
第八,页面密度检查。
看信息量是否接近参考模板。
最后写一个检查文件:
{"pass": true,"logic_pass": true,"style_pass": true,"render_pass": true,"fidelity_pass": true,"layering_pass": true,"geometry_pass": true,"text_layout_pass": true,"density_pass": true,"background_origin_pass": true,"component_origin_pass": true,"issues": [],"revision_instruction": "","style_used": "","reference_archetype": "","logic_type": "","layout_pattern": "","repair_loop_count": 0}
如果没过,revision_instruction 必须写得很具体。
不要写“优化一下风格”。
要写成这样:
请按选中的参考页面原型重新生成。保留顶部标题条、左侧责任主体标签栏、青色圆角分区框、小号蓝色流程节点、细连接线和行内黄色指标。复用 assets/backgrounds/content-background.png。删除大面积亮色面板和独立 KPI 卡片。这样下一轮才知道怎么修。
最多自动修 3 轮。
3 轮还没过,就停下来问用户。
因为这个时候大概率有两个问题:内容太多,或者模板本身支撑不了这个页面。
第七步:加一个 PPTX 结构检查脚本
只看 PNG 还不够。
有些页面看起来差不多,但 PPTX 里面已经乱了。
比如:
有隐藏占位符;
节点用了默认黑边;
背景关系丢了;
出现了 Office 默认样式;
多了一个大色块;
文字被拆成很多碎片。
所以最好再加一个脚本:
scripts/pptx_style_inspector.py它负责检查导出的 PPTX 结构,并保存:
slide-001.xmlcheck.json这个文件可以和 review.json 合并判断。
如果 XML 检查发现默认黑边、错误背景、占位符残留,就算 PNG 看起来能过,也要判失败。
这个检查对办公 PPT 很有用。
因为正式材料最后要编辑,PPTX 结构脏了,后面改起来会很痛苦。
第八步:管理会话状态
这个智能体还要记住当前状态。
最少要有这些字段:
{"current_style": "style-slug","temporary_style": null,"style_library_checked": true,"style_library_empty": false,"slide_counter": 1,"output_folder": "slides","last_slide_summary": "","style_history": []}
这里最重要的是 current_style。
用户选定风格以后,后面每一页默认沿用它。
只有用户明确说这些话,才切换风格:
换个风格换一种模板后面换一个模板新增一个风格用这个 PPT 当模板按这张截图的风格来这一页临时用另一个模板
如果用户说“这一页临时用另一个模板”,生成完以后要恢复之前的 current_style。
这个细节很重要。
否则用户只是想让某一页临时变化,结果后面所有页面都跟着换了。
一个最小可用版本怎么做
如果你先做最小可用版本,不用一口气做得很复杂。
我的建议是先做 5 个文件。
single-slide-ppt-agent/ SKILL.md references/ style-profiler.md single-slide-builder.md slide-review-refiner.md schemas.md scripts/ style_library.py pptx_style_inspector.py
第一版只支持 3 个动作:
新增风格;
选择风格;
生成单页。
新增风格时,先把 PPTX 或截图整理成 style.profile.json。
选择风格时,把它写进 current_style。
生成单页时,只做当前页,并输出 PPTX、PNG、源码文件和检查文件。
等这 3 个动作跑顺,再加更多页面类型、更多检查指标、更多风格反馈。
不要一开始就做“自动生成整套 PPT”。
这个功能听起来很爽,但是很容易把系统带乱。
如何验证这个智能体做成了
你可以用 3 轮测试来验证。
第一轮,测风格拆解。
给它一个真实 PPTX,看它能不能生成:
style.profile.jsonstyle.brief.mdthumbnail.pngassets/backgrounds/content-background.png
然后检查 style.profile.json 里有没有这些字段:
reference_archetypescolor_role_bindingsbackground_fidelity_ruleslayout_fidelity_rulesforbidden_substitutionscomponent_tokensfeedback_rules
第二轮,测单页生成。
给它一个流程页需求:
这一页讲项目推进流程,包括前期调研、方案设计、系统建设、联调测试、上线运行。看输出里有没有:
slide-001.pptxslide-001.pngslide-001.source.jsxslide-001.review.json
再看页面是否用了当前风格,有没有临时换成另一个模板。
第三轮,测修正能力。
故意指出一个问题:
这一页的流程节点边框太重,不像原模板,请修正当前页。看它有没有把这个反馈写入当前页修正。
如果是反复出现的问题,还要写进 feedback_rules,影响后续页面。
这样才算真正做到了可复用。
常见卡点
1. 只写一段超长提示词
超长提示词能撑一两次。
页面多了以后,智能体还是会漂。
要把风格、生成、检查、修正拆成模块。
2. 只保存调色板
调色板不够。
你要保存颜色角色。
黄色给关键数字,蓝色给标题条,半透明青色给流程框,这些都要写清楚。
3. 背景用相似图片替代
办公模板最容易在背景上露馅。
如果原 PPT 有母版背景,就从母版或版式里提取。
不要找一个“差不多”的科技背景顶上去。
4. 页面原型没保存
只保存颜色和字体,后面还是会乱。
你还要保存页面语法。
比如顶部标题条、左侧标签栏、多段流程框、小节点、细连接线,这些东西组合在一起才像原模板。
5. 只看 PNG,不看 PPTX
PNG 只能看表面。
PPTX 里面如果有默认样式、隐藏占位符、错误背景关系,后面编辑会很麻烦。
所以要加 XML 或结构检查。
6. 自动修太多轮
自动修正最多 3 轮。
3 轮还过不了,就让用户介入。
继续自动修下去,通常只会越修越乱。
最后总结
做一个这样的智能体,重点是让它守规矩。
它要知道当前风格是什么,哪些背景必须复用,哪些颜色只能用在固定位置,哪些页面原型要保留,哪些默认样式一出现就要判失败。
换句话说,这个智能体真正的能力,是把办公 PPT 里那些以前靠人眼判断的东西,拆成可以保存、可以调用、可以检查、可以修正的规则。
你把这套东西搭起来以后,它才适合做政府汇报、项目汇报、数据治理成效展示这类正式材料。
否则它生成再快,也只是多给你几个需要返工的页面。

