资料解读:工业大数据采集处理与应用
详细资料请看本解读文章的最后内容。本文围绕工业大数据全流程技术体系展开系统解读,覆盖基础认知、采集、预处理、建模、分析、可视化及行业应用七大核心模块,完整呈现工业大数据从理论到实践的全套知识框架与实操方法。
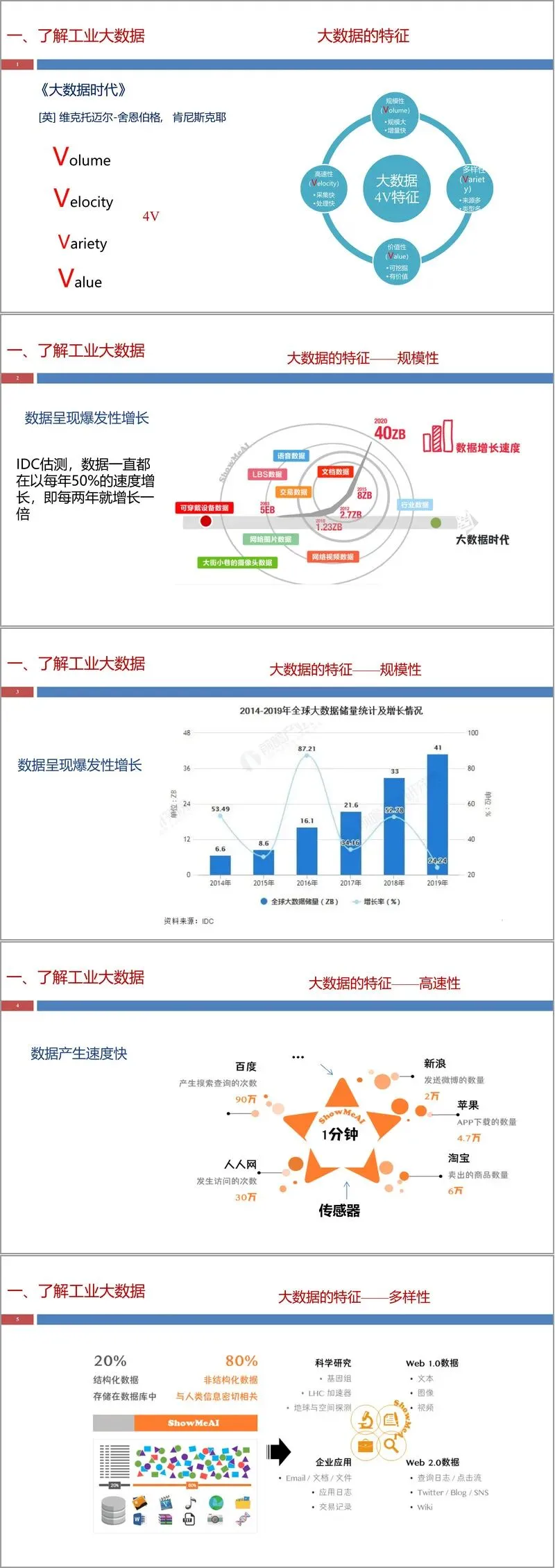
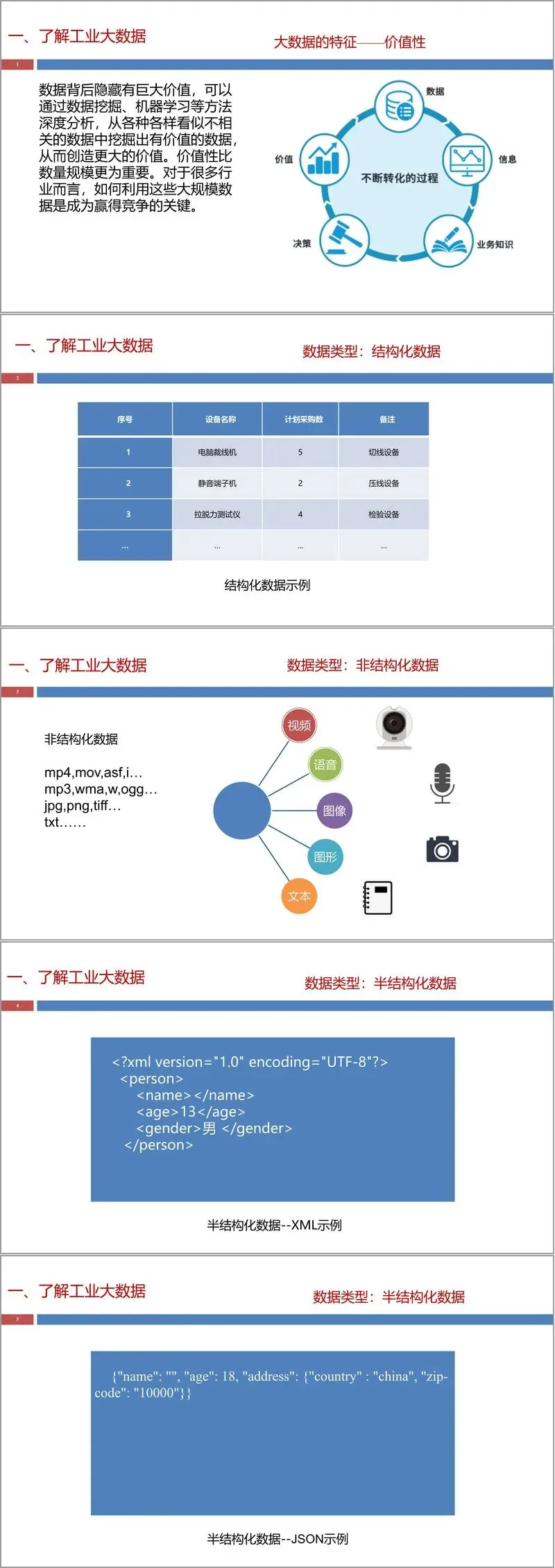
工业大数据以大数据 4V 特征为基础,兼具时序性、实时性、高通量、高纬度、多尺度、高噪性六大专属特性,数据来源分为企业信息化数据、工业互联网数据与外部数据三类,涵盖 ERP、MES、PLC、传感器、RFID 等多类系统与设备产生的结构化、半结构化、非结构化数据,是支撑智能制造的核心资源。文件明确了工业大数据的规模计算方法,结合机床、炼铁等典型场景给出数据量测算实例,帮助从业者直观理解工业场景下的数据量级。
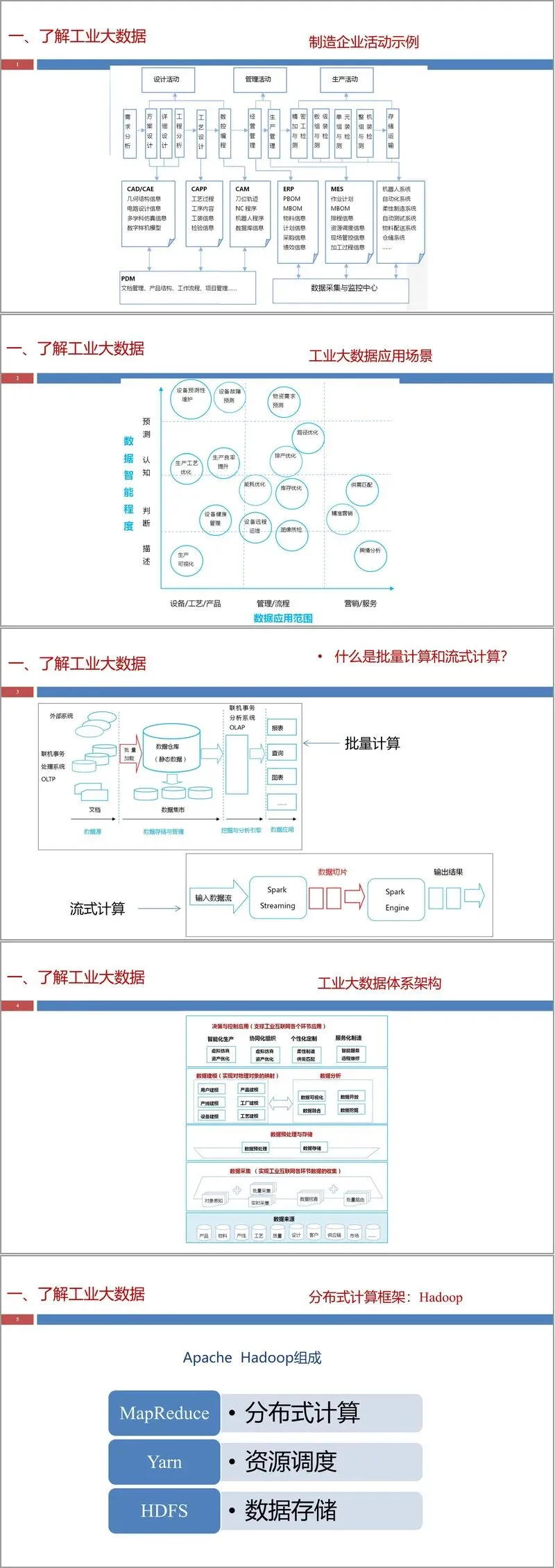
在数据采集环节,文件系统讲解工业现场网络体系,包括现场总线与工业以太网两大核心技术,梳理 PROFINET、EtherCAT、Modbus、OPC UA、MQTT 等主流协议,明确不同协议的应用层级与适配场景。同时介绍传感器、RFID、条码技术等采集手段,以及 PLC、PTL 智能拣选系统的核心数据采集方法,搭配 IoTHub 平台与 MySQL 数据库,完成从现场设备到数据存储的全流程部署。
数据预处理是保障数据质量的关键,核心围绕ETL 流程展开,包含数据抽取、转换、加载三大步骤,通过清洗、去重、补缺失、标准化等操作处理脏数据。文件重点介绍 Kettle 工具的实操方法,涵盖界面操作、转换与步骤创建、数据库连接等核心技能,同时区分数据库与数据仓库的差异,讲解基于 Hadoop 的 Hive 数据仓库构建、分区分桶设置、数据加载与查询语法,为工业大数据的高效存储与查询提供技术支撑。
数据建模环节以 UML 统一建模语言为核心,讲解类图、对象关系、属性与方法的表示方法,指导使用者将设备、生产线、工序、零部件等物理对象转化为信息模型,完成从 UML 类图到关系数据库二维表的映射,搭配 StarUML 工具实现车间设备与生产过程信息模型的可视化绘制,为工业数据结构化管理奠定基础。
工业大数据分析聚焦机器学习与算法应用,划分有监督、无监督、强化学习三大类型,重点讲解回归分析与分类预测两大核心任务。文件介绍 Weka 工具的实操流程,涵盖数据导入、预处理、算法选择、模型训练与评估,同时拓展集成学习、聚类分析、关联规则、时间序列等进阶算法,适配设备故障预测、质量检测、工艺优化等多元工业场景。
数据可视化模块聚焦工业数据的直观呈现,介绍 IoTHub 与 Grafana 两大工具,支持仪表盘、饼图、折线图、三维可视化等多种展示形式,可实现电机转速、物料库存、生产订单、工位状态等数据的实时监控,助力企业快速洞察数据价值。
最后,文件落脚于工业大数据的实际应用,讲解数据驱动制造、设备预测维护、健康状态评估、故障检测、质量检测与工艺优化等核心场景,结合风电、汽车冲压等行业案例,说明健康指数计算、故障预警、缺陷智能识别等落地方法,展现工业大数据在降本增效、提升生产稳定性方面的实际价值。
接下来请您阅读下面的详细资料吧。